電腦文字編碼
我(U+6211)
(U+200B)
要編碼幹嘛
文字
電腦中的每個文字,都對應著一個二進位編碼
因為電腦看不懂文字,只看得懂二進位
所以我把一個文字對應到一種二進位編碼,電腦就能識別出來
ASCII
^D
統一標準
如果我有一套編碼系統,其中A對應著0001
然而有另一套編碼系統,其中A對應著0011
則這兩種編碼系統在通訊的時候,文字會變得混亂
所以需要一個統一的編碼系統來解決此問題
ASCII
最早是美國在做這件事
然後你就發現英文字母只有26個
大小寫考慮進去的話也只有52個
標點符號與其他控制字符也不多
所以ASCII就開了256的大小的字符集
裝了128個字符
剩下給西歐國家做自己需要的擴展
也就是EASCII
GBK
丂(0x8140)(U+4E02)
漢字
前面的ASCII只能存256個字符
而一個byte有8個bit,只有256種組合
然後漢字超多,所以GBK用的是兩個byte來存字元,也就是65536種組合
GB-2312-80
GBK是GB-2312-80的擴展,因為GB-2312-80實際上只收錄了6000多個常用漢字,而生僻字則無法顯示
無法顯示的話就會顯示成一個方框▯
這個方框不是GB-2312的字元,而是像仿宋黑體的字體會預留一個方框來應對這種問題,俗稱豆腐字
unicode
𒄃(U+12103)
😀(U+1F600)
�(U+FFFD)
大一統
目前的UNICODE收錄了154998種字元
其中包含了世界各國的文字
還有標題底下的一堆抽象的字元
UNICODE創立之前,很多國家都有自己的編碼系統,而且互不兼容
UNICODE的出現就是為了解決編碼系統衝突的現象
但我們等等就要實作編碼系統衝突
UTF-8 UTF-16
UTF-8: 以1~4個byte存取文字,將常用的文字用1個byte存取,節省空間
UTF-16: 以2或4個byte存取文字,對於較少見的文字,可以相較於UTF-8更節省空間
代理對
UTF-16 編碼中用來表示超過 U+FFFF 的字元。
UTF-16 本身是以2 byte為基礎,但 Unicode 的範圍到 U+10FFFF,
超過了2byte能直接表示的範圍。
因此,UTF-16 引入了代理對,用兩組2byte單元來表示一個字元。
bilibili的神奇影片標題
講師之前在B站刷到一個標題空白的影片
複製下來後發現是U+D835與U+DC38的組合
這兩個就是一個代理對,兩個組合起來的字元是𝐸(U+1D438)
但理論上你不能單獨打出一個高位代理或低位代理
所以很神奇
喔對了這個影片好像是個音樂MV
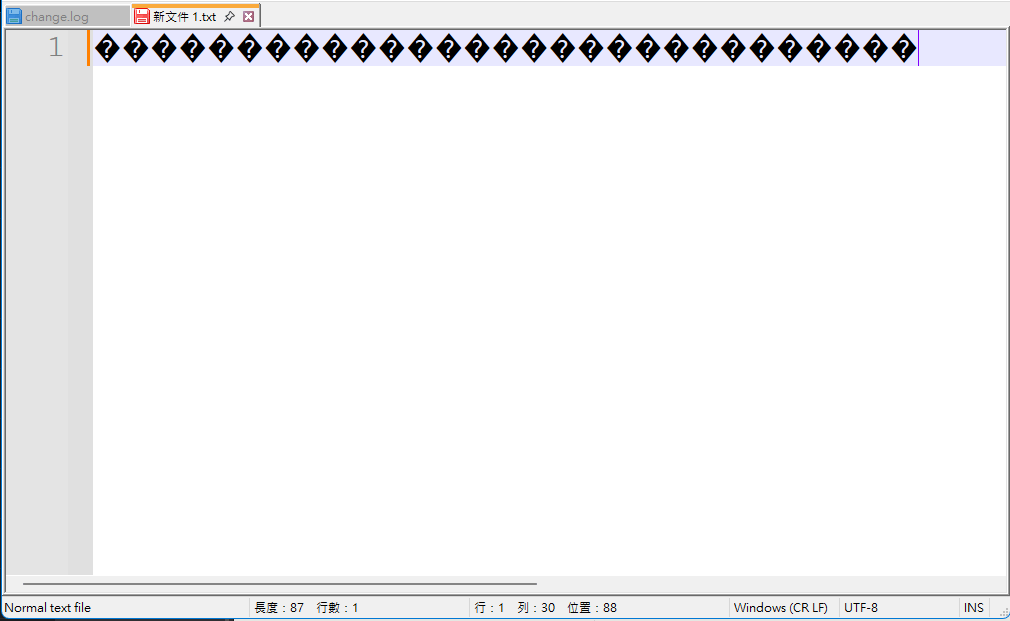
錕斤拷�
0xEFBFBD
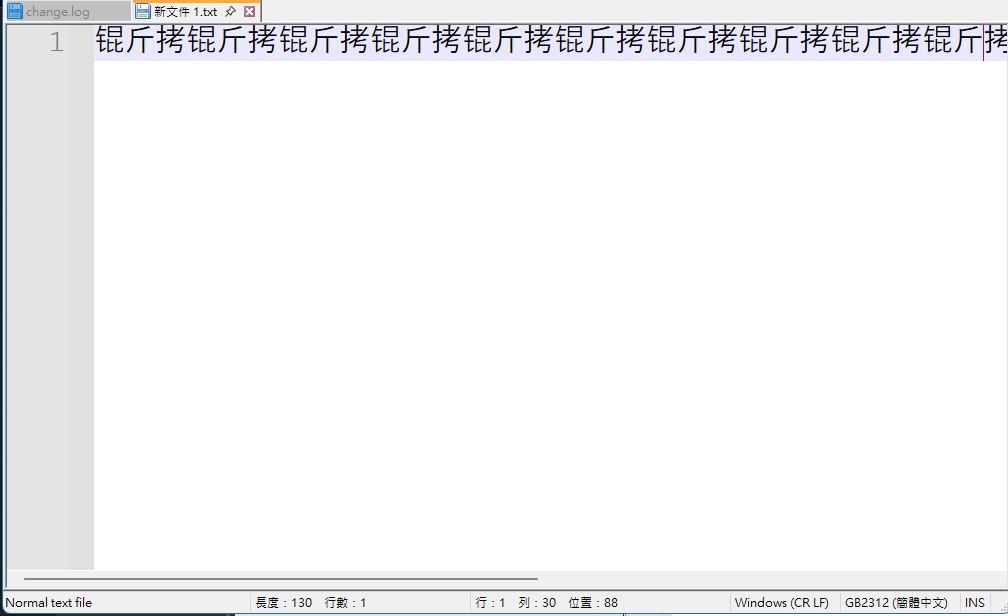
錕斤拷
這個著名的編碼衝突來自GBK與UTF-8的衝突
當一個以GBK編碼儲存的文檔,以UTF-8編譯時
會產生錯誤,UTF-8就會用�(0xEFBFBD)替代
而此文檔再次用GBK打開時,��(EFBFBDEFBFBD)就會被當成EFBF, BDEF, BFBD三個字元,也就是錕斤拷
不是阿超怪
講師在實驗中發現,GBK轉UTF-8所產生的�並不是0xEFBFBD,而是0020(空格)
很怪
所以我們無法透過此方法產生大量的0xEFBFBD
但是我們可以直接複製�
notepad++
使用notepad++,將編碼改成UTF-8,複製貼上多個�
將編碼轉成GB2312
你就成功了
有趣的一些字元
U+200B,零寬空格,顧名思義,他是一個沒有寬度的空格
最開頭的標題底下就是這個
U+00A0,不換行空格,此字元打出來後,你會發現你的enter無法起到換行的作用
Minimal
By ck11300768鄭博軒



