








Content ITV PRO
This is Itvedant Content department
Learning Outcome
5
Compare the trade-offs between Bagging (reducing variance) & Boosting (reducing bias)
4
Visualize how boosting increases weights on mistakes.
3
Demystify the sequential, error-correcting logic of Boosting.
2
Understand the parallel, independent structure of Bagging.
1
Define the core philosophy of Ensemble Learning.
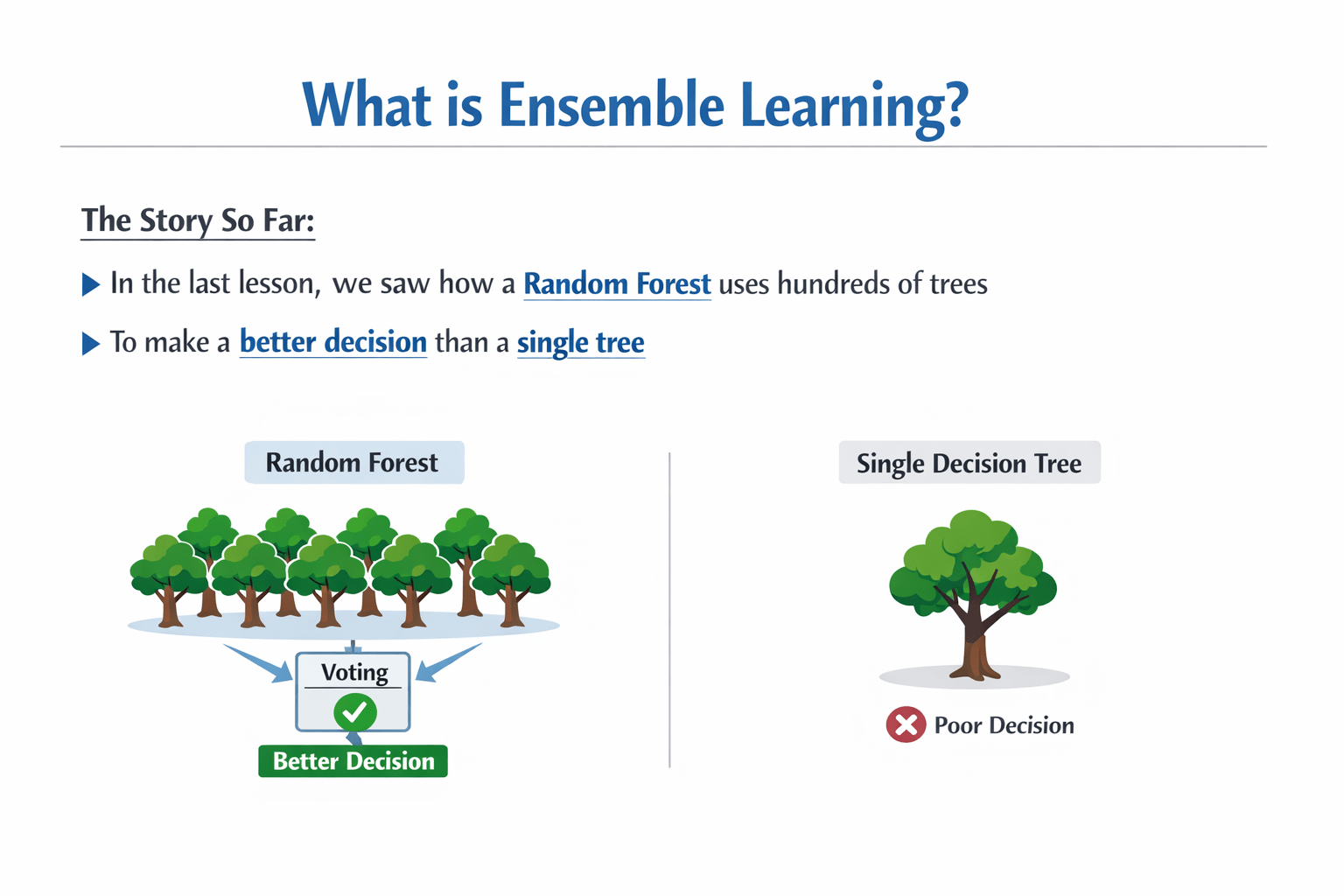
In the last lesson, we saw how a Random Forest uses hundreds of trees to make a better decision than a single tree.
There are two fundamentally different ways to manage this team: Bagging and Boosting.
Bagging (Bootstrap Aggregating)
Imagine a jury of 100 people trying to guess the weight of an ox.
They are not allowed to talk to each other. They each write their guess on a hidden piece of paper.
We collect all the papers and average the numbers. The result is shockingly accurate
Bagging builds 100 models at the exact same time (in parallel). They do not communicate. We simply take a majority vote or average at the end.
The Machine's Logic:
Random Forest is the most famous example of this!
Boosting
The Analogy: "The Masterclass Relay"
Tutor 1 teaches a student math.
The student takes a test.
They score 80%, but they completely fail all the Geometry questions.
Tutor 2 steps in.
Boosting
Tutor 3 steps in and focuses entirely on Fractions.
Together, the sequence of tutors creates a flawless math student.
Boosting builds models one at a time (sequentially).
Each new model acts as a "tutor" whose only job is to fix the specific errors made by the model right before it.
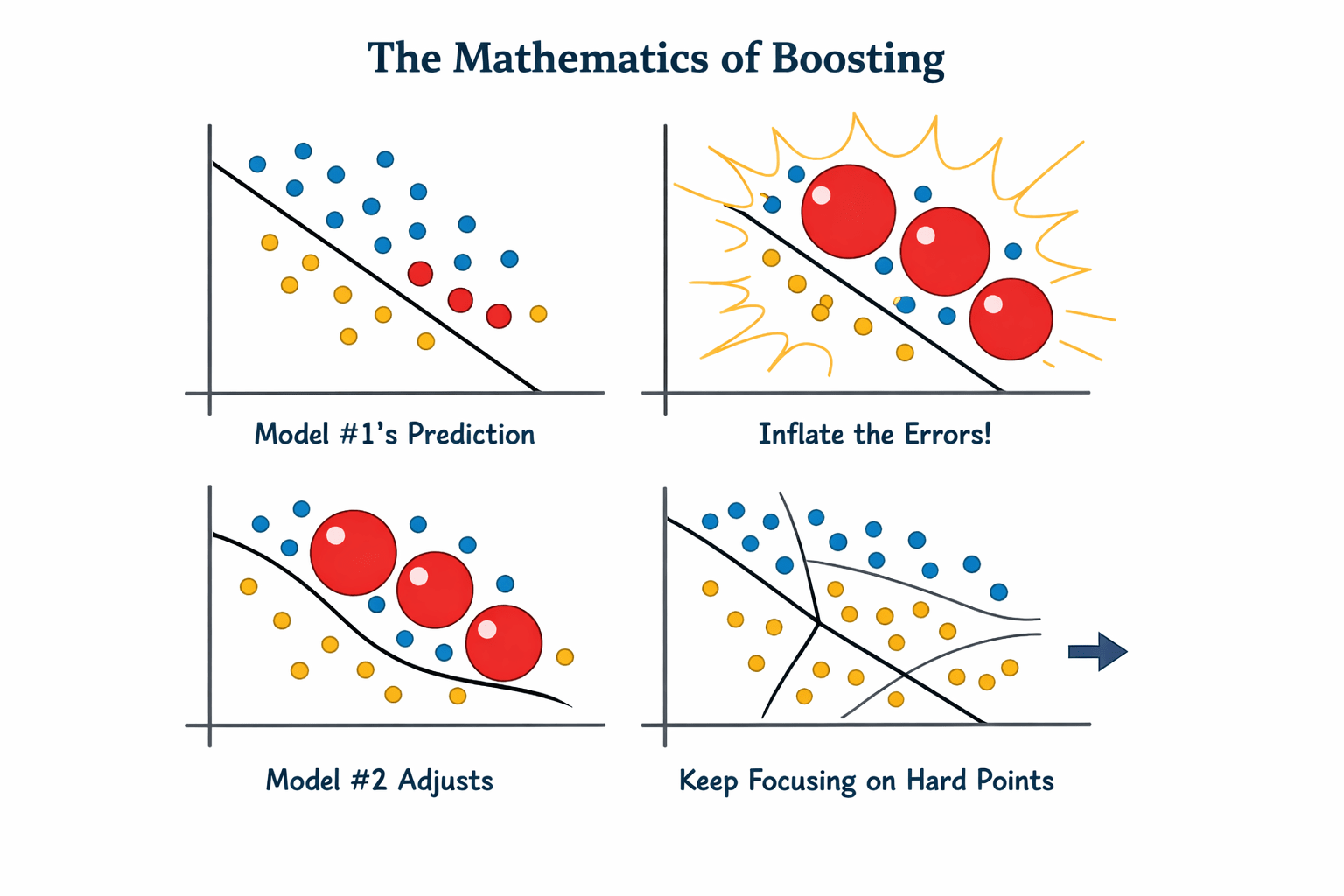
The Mathematics of Boosting
How does it "focus" on mistakes? Using Weights
Step 1: Model #1 makes predictions.
It gets 90 dots right and 10 dots wrong.
Step 2: The algorithm mathematically inflates the "weight" (importance) of those 10 wrong dots, making them look massive to the next model.
The Mathematics of Boosting
How does it "focus" on mistakes? Using Weights
Step 3: Model #2 is terrified of missing those massive dots, so it changes its entire boundary just to get them right.
Step 4: This repeats, with the models constantly passing the "hardest to predict" data points down the chain.
The Showdown: Variance vs. Bias
The Disease of High Variance (Overfitting):
The model is too wild and memorizes noise.
The Cure: Bagging. By averaging hundreds of wild models together, they cancel out each other's noise, creating a smooth, stable prediction.
The Cure: Boosting. By forcing a sequence of simple models to obsessively correct mistakes, they combine to form a highly intelligent, complex boundary.
The Disease of High Bias (Underfitting):
The model is too simple and keeps making the same dumb mistakes
Pros & Cons
Summary
4
Bagging reduces overfitting ,Boosting reduces underfitting (needs careful tuning).
3
Boosting builds models sequentially, each fixing previous errors.
2
Bagging builds independent models in parallel and averages results for stability.
1
Ensemble Learning combines weak models into a strong model.
Quiz
Why is a Bagging algorithm (like Random Forest) generally faster to train on massive computer clusters than a Boosting algorithm?
A. Bagging uses fewer features.
B. Parallel (Bagging) vs Sequential (Boosting)
C. Requires complex transformations
D. Bagging only uses Linear Regression under the hood
Why is a Bagging algorithm (like Random Forest) generally faster to train on massive computer clusters than a Boosting algorithm?
A. Bagging uses fewer features.
B. Parallel (Bagging) vs Sequential (Boosting)
C. Requires complex transformations
D. Bagging only uses Linear Regression under the hood
Quiz-Answer
By Content ITV



