





Content ITV PRO
This is Itvedant Content department
Define Customer Churn Problem and Objectives
Business Scenario
Welcome aboard!
Today is your first day as a Junior Data Scientist on the Telecom Customer Intelligence Project at AutoVision Analytics.
The company is facing customer churn, leading to revenue loss and higher acquisition costs. To address this, it plans to build a Machine Learning-based Customer Churn Prediction System that identifies customers likely to leave.
Your first task is to understand the churn problem, define the project objective, and determine what the model should predict.
Pre-Lab Preparation
Topic : Classification Models
1) Logistic Regression
2) Decision Tree Classification
3) Pruning Techniques
4) Support Vector Machine (SVM)
5) Naive Bayes Algorithm
git pull origin branchNameGit Pull
Task 1: Understand the Customer Churn Problem
Before building any Machine Learning model, the management team wants every member of the Data Science team to understand the business problem thoroughly.
Customer Churn Prediction is one of the most important applications of Machine Learning in the telecom industry. By identifying customers who are likely to leave, the company can take preventive actions such as personalized offers, better customer support, or loyalty programs to retain them.
Your task is to understand what Customer Churn means, why it occurs, and why predicting it is valuable for the business.
What is Customer Churn?
Customer Churn refers to the situation where a customer stops using a company's products or services.
Common reasons for churn include:
Predicting churn allows businesses to identify at-risk customers and take proactive measures to improve customer retention and revenue.
Open Google Colab
1
Since this is a new Machine Learning project, create a new Google Colab notebook.
Download the Dataset
2
Click to download dataset : Customer_Churn_dataset.csv
Import the Required Library
3
import pandas as pd
import numpy as npLoad the Dataset
4
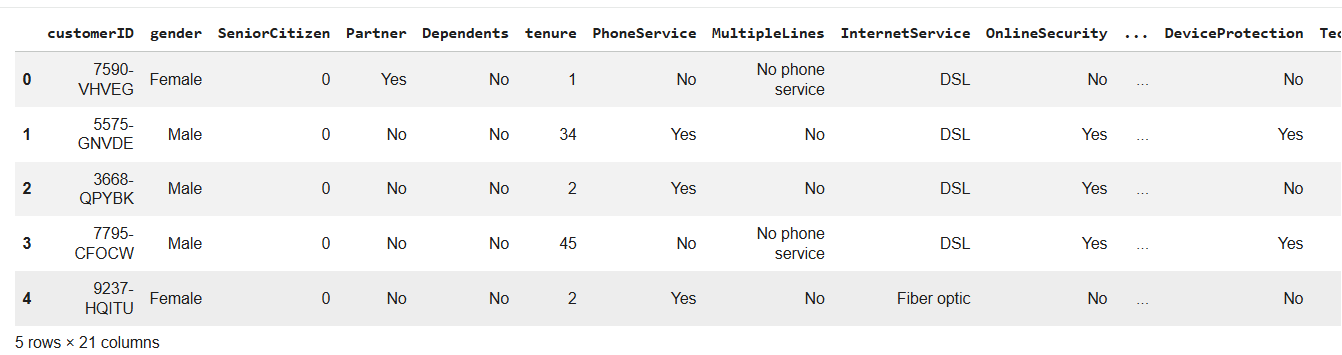
df = pd.read_csv("Telcom-Customer-Churn.csv")Verify that the Dataset has Loaded Successfully
5
df.head()Task 2: Identify the Business Objective
After understanding the problem, your manager asks you to define the project's business objective before any data analysis or model building begins.
A clearly defined objective helps the Data Science team align technical solutions with business goals and ensures that the project delivers measurable value.
Your task is to identify:
Activity
Prepare a Project Objective Report.
| Item | Description |
|---|---|
| Business Problem | |
| Business Objective | |
| Expected Outcome |
Task 3: Identify the Target Variable
Before building any Machine Learning model, a Data Scientist must identify the target variable, i.e., the value that the model is expected to predict.
The management team wants to predict whether a customer is likely to leave the telecom service or continue using it. Therefore, your responsibility is to explore the dataset and identify the target variable for this project.
For this project:
Target Variable = Churn
Possible values:
Since the target variable contains categories rather than continuous numerical values, this is a Classification Problem.
Check Dataset Information
1
df.info()Observe:
Display All Column Names
2
df.columnsIdentify the Target Variable and view its classes
3
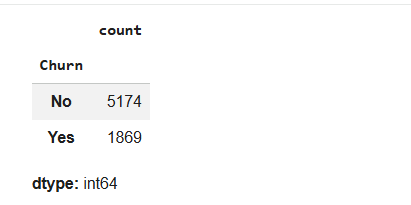
df["Churn"].unique()Count Customers in Each Class
4
df["Churn"].value_counts()This helps understand how many customers have churned and how many have not churned.
Task 4: Understand Classification Models
The Senior Data Scientist introduces the Machine Learning algorithms that will be used in the upcoming phases of the project.
Your task today is not to implement these algorithms, but to understand when and why they are used for classification problems like Customer Churn Prediction.
Logistic Regression
Logistic Regression is a supervised Machine Learning algorithm used for binary classification problems, where the output belongs to one of two categories such as Yes/No or Churn/No Churn.
Decision Tree Classification
Decision Tree Classification creates a tree-like structure of decision rules to classify observations into different categories. It is simple to interpret and widely used in business applications.
Pruning Techniques
Pruning is the process of removing unnecessary branches from a Decision Tree to make it simpler and prevent overfitting, thereby improving performance on unseen data.
Support Vector Machine (SVM)
Support Vector Machine is a classification algorithm that identifies the best decision boundary (hyperplane) to separate different classes.
It performs well for both simple and complex classification problems.
Naive Bayes Algorithm
Naive Bayes is a probabilistic classification algorithm based on Bayes' Theorem. It assumes that features are independent and is commonly used in spam detection, sentiment analysis, and customer classification problems.
Activity
Prepare a Classification Model Summary.
| Model | Primary use |
|---|---|
| Logistic Regression | |
| Decision Tree Classification | |
| Support Vector Machine | |
| Naive Bayes Algorithm |
Great job!
You have successfully completed Lab 7: Define Customer Churn Problem and Objectives.
In this lab, you identified the customer churn problem, defined the business objective and target variable, understood why churn prediction is a classification problem, and gained an introduction to Logistic Regression, Decision Trees, Pruning, SVM, and Naive Bayes.
You are now ready to proceed to the next stage of the Telecom Customer Intelligence Project.
Checkpoint
Next-Lab Preparation
Git Push
git push origin branchNameTopic : Classification Models
1) Logistic Regression
2) Model Evaluation Metrics (Accuracy, Precision, Recall, F1-score, Confusion Matrix, ROC-AUC)
By Content ITV




