










Content ITV PRO
This is Itvedant Content department
Learning Outcome
5
Improving ReLU with Leaky ReLU
4
ReLU and the Deep Learning Revolution
3
Vanishing Gradient Problem
2
Mathematical Intuition Behind Non-Linearity
1
Neural Networks Without Activation Functions
Recall
In the Perceptron model, a neuron calculates the net input using the formula:
Net Input (z) = (Weights × Inputs) + Bias
The neuron calculates a weighted sum of inputs and adds a bias to get the net input value.
After calculating the sum, the neuron must decide what to do with the value.
If the result is very large, the neuron cannot pass the raw value directly to the next layer.
A filter decides whether and how strongly the neuron activates.
This filter is called the Activation Function.
Hook/Story/Analogy(Slide 4)
Transition from Analogy to Technical Concept(Slide 5)
Sigmoid (The S-Curve)
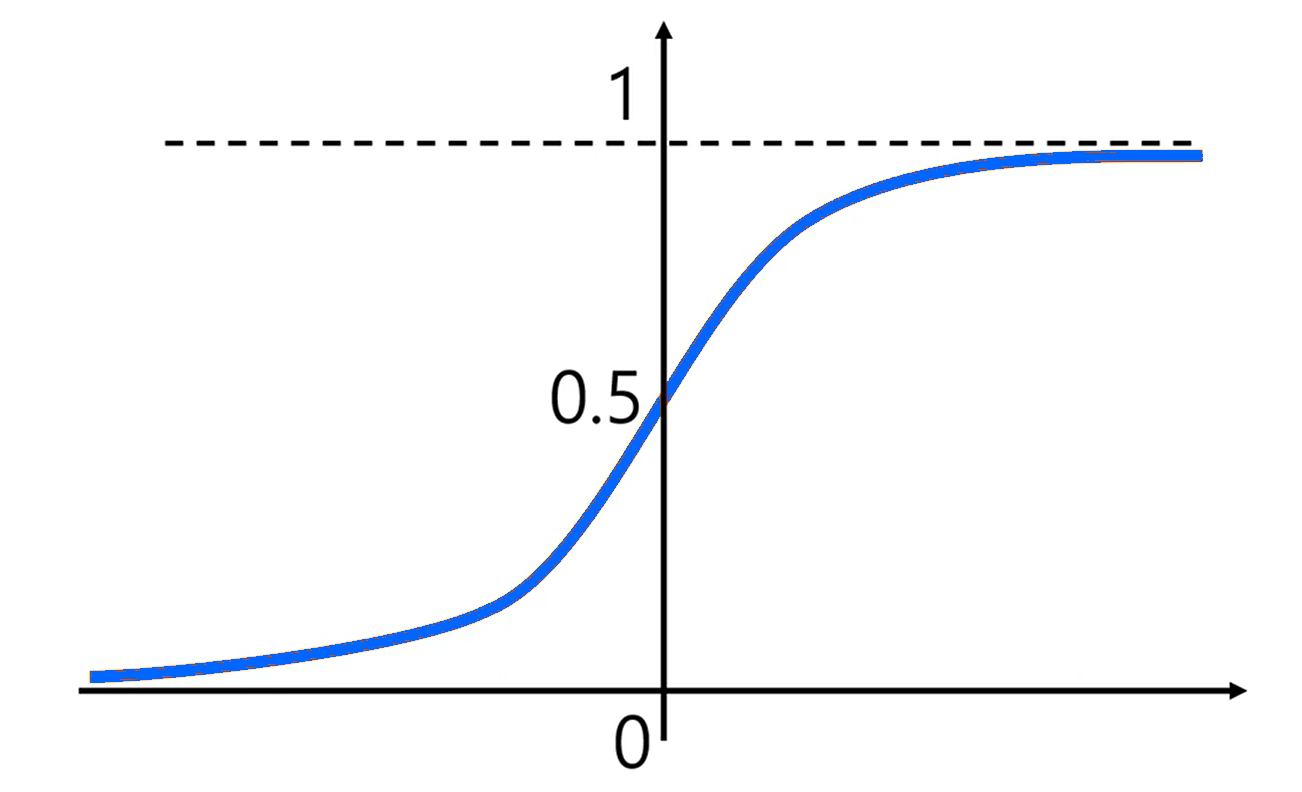
The Sigmoid function is one of the earliest activation functions used in neural networks.
Its job is to take any input value and convert it into a number between 0 and 1.
So no matter how big or small the input is, the output will always be:
0<Output<1
Because of this property, it is often interpreted as a probability.
So the model can answer Yes/No type questions.
These are called binary classification problems.
The Sigmoid function is called smooth because the curve changes gradually and continuously without any sudden jumps or sharp corners.
Example:
| Input | Sigmoid Output |
|---|---|
| 10 | 0.99995 |
| 100 | 0.9999 |
| 1000 | 0.9999 |
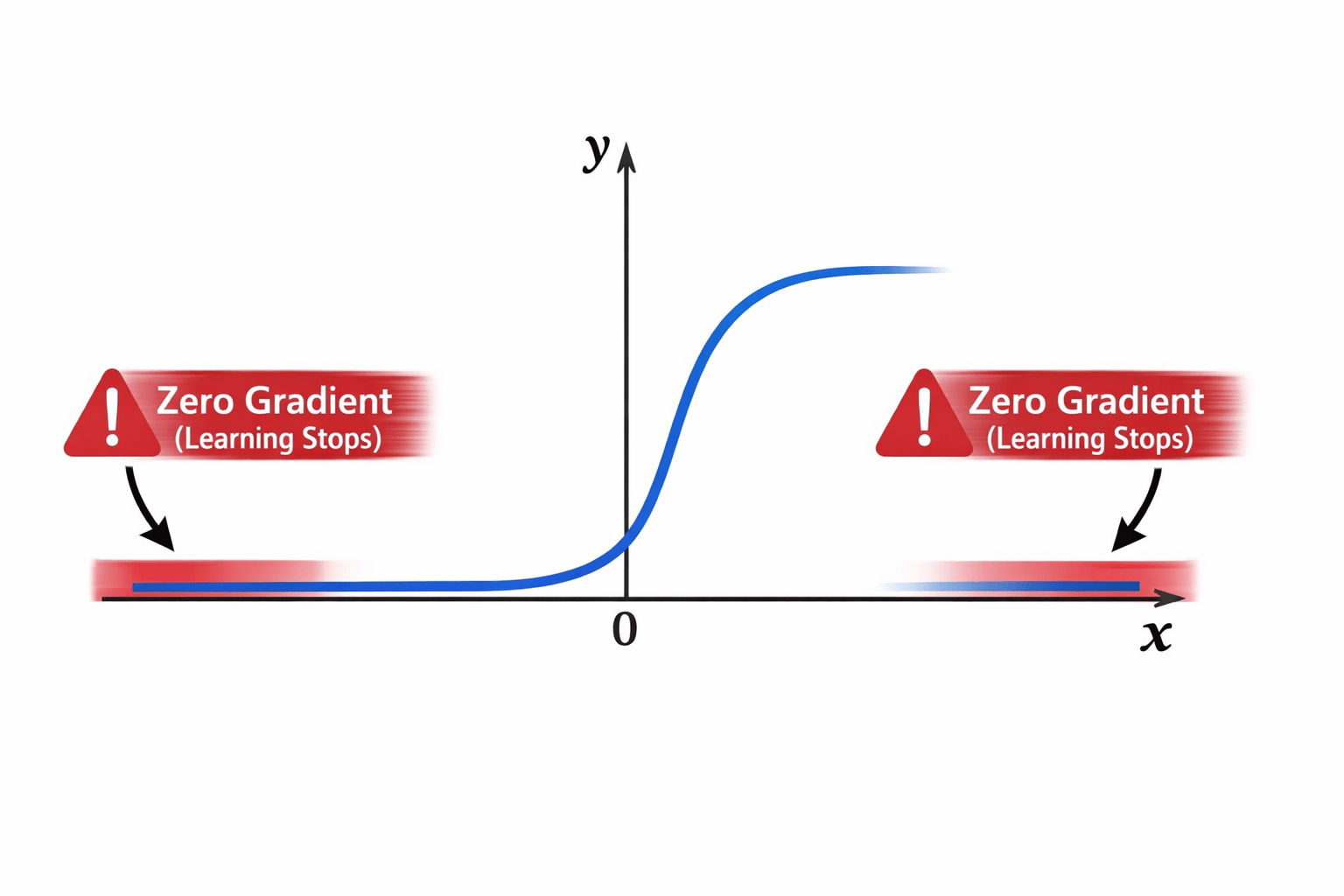
Even though the inputs are very different, the outputs become almost the same.
So the curve at the edges becomes flat.
When the curve is flat, the "gradient" (the learning signal) becomes zero.
During Backpropagation, the network stops learning entirely. Deep layers literally "starve" to death.
Tanh (The Zero-Centered S-Curve)
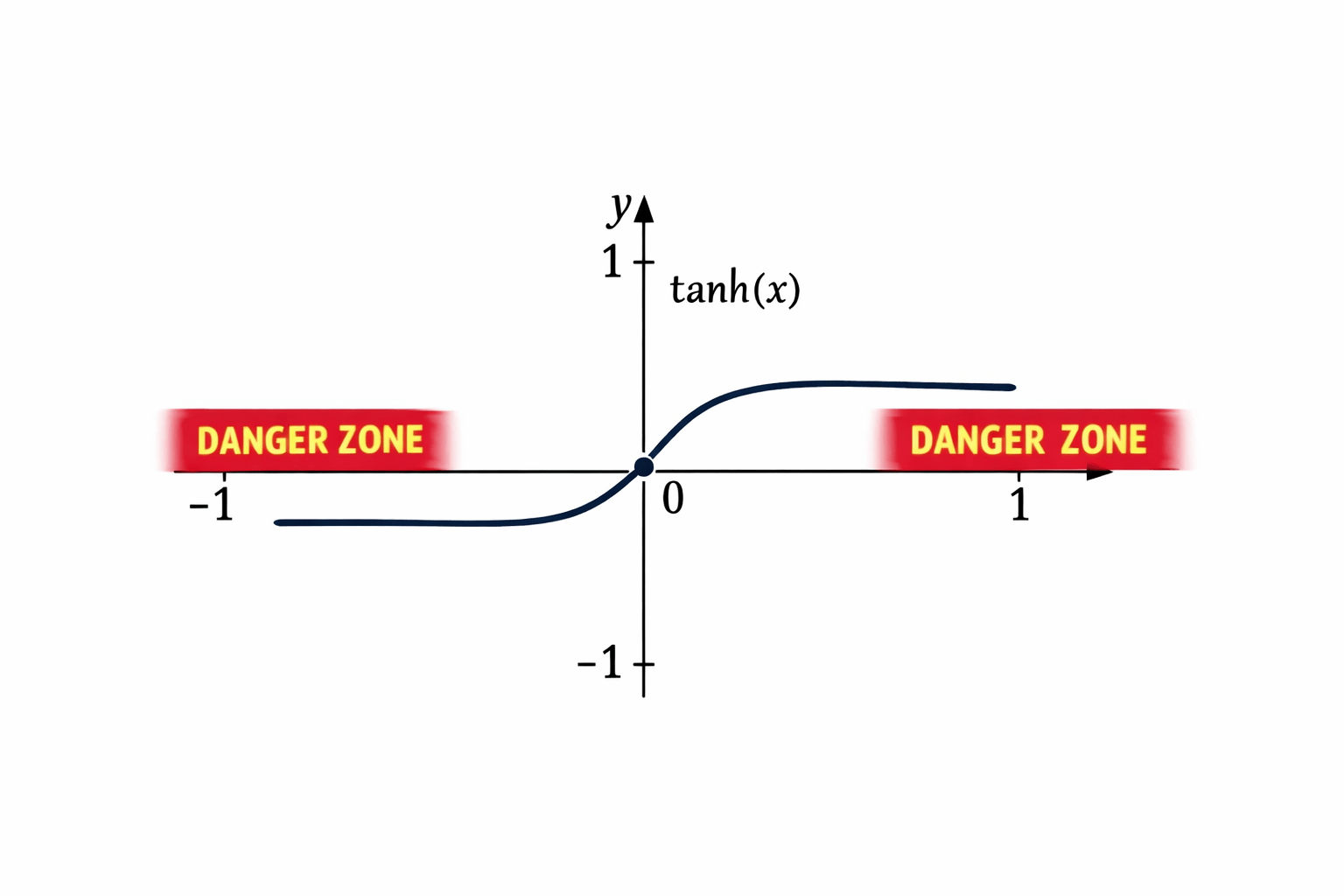
The Tanh (Hyperbolic Tangent) activation function is very similar to the Sigmoid function, but with one important improvement.
So instead of compressing values only into positive numbers, Tanh allows both negative and positive outputs.
Think of it like this:
| Input Value | Tanh Output |
|---|---|
| Very large positive number | Close to +1 |
| 0 | 0 |
| Very large negative number | Close to −1 |
So Tanh squishes any number into the range −1 to 1
Why Researchers Created Tanh ?
Sigmoid had a problem: outputs are always positive.
Example:
| Input | Sigmoid Output |
|---|---|
| -5 | 0.006 |
| 0 | 0.5 |
| 5 | 0.99 |
Notice something:
All outputs are positive numbers.
Researchers solved this by creating Tanh, which is zero-centered.
During gradient descent optimization, this causes unbalanced weight updates.
Earlier activation functions like Sigmoid and Tanh had a major problem called the Vanishing Gradient Problem.
Because of this issue, deep neural networks could not learn properly, especially when they had many layers.
For many years this slowed down progress in Artificial Intelligence, sometimes called the AI Winter.
Core Concepts (.....Slide N-3)
Summary
4
Multi-Class Classification Output: Use Softmax (converts outputs into probabilities that sum to 1).
3
Binary Classification Output: Use Sigmoid (outputs probability between 0 and 1).
2
Alternative: Use Leaky ReLU if neurons stop learning (Dying ReLU problem).
1
Hidden Layers: Use ReLU because it is fast and reduces the vanishing gradient problem.
Quiz
Why was the Sigmoid activation function abandoned in deep neural network hidden layers?
A. It outputs only negative numbers
B. It is purely linear and cannot learn complex patterns
C. Large inputs flatten the curve, causing the Vanishing Gradient problem
D. It causes the Dying ReLU problem
Quiz-Answer
Why was the Sigmoid activation function abandoned in deep neural network hidden layers?
A. It outputs only negative numbers
B. It is purely linear and cannot learn complex patterns
C. Large inputs flatten the curve, causing the Vanishing Gradient problem
D. It causes the Dying ReLU problem
By Content ITV



