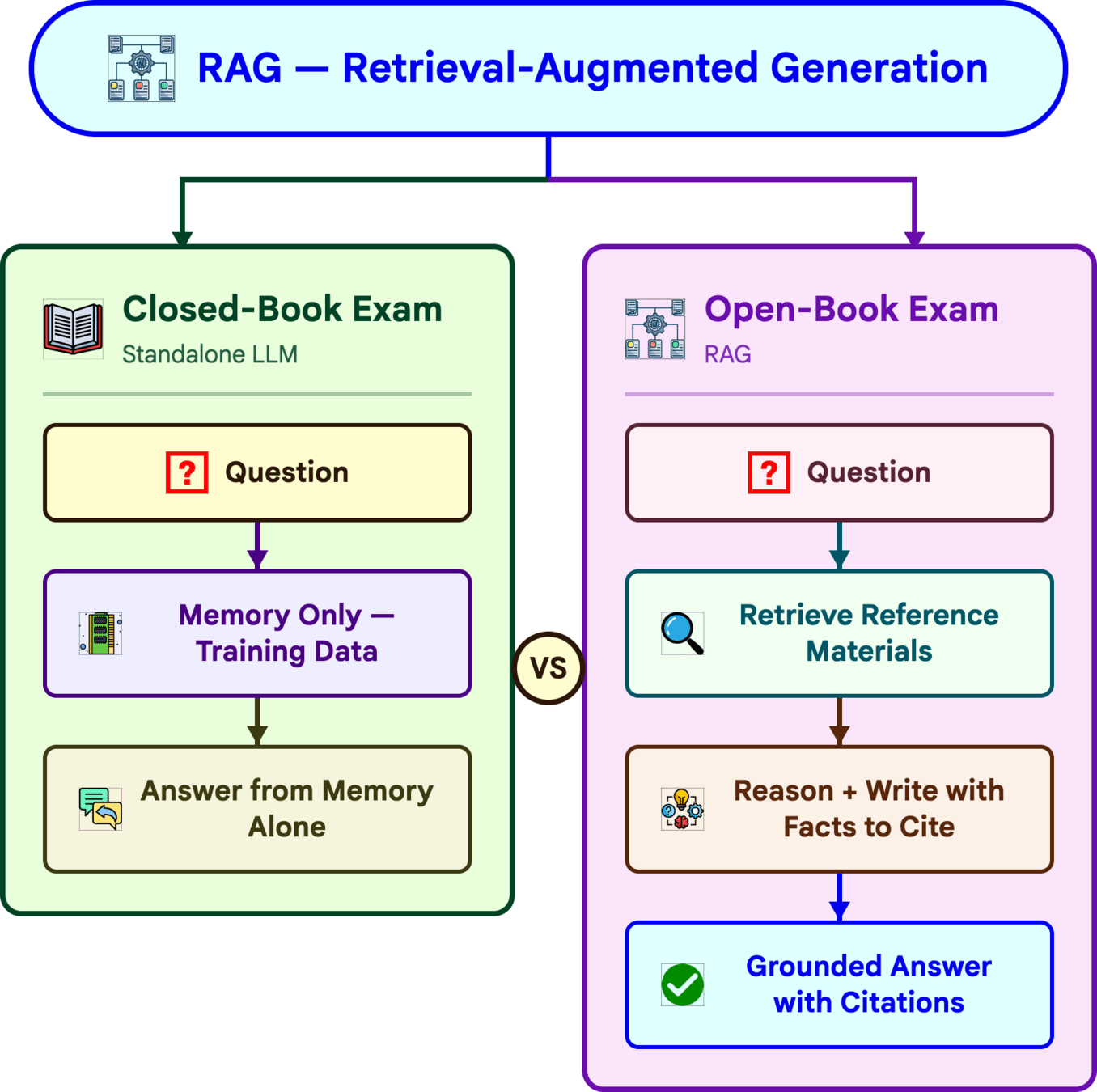
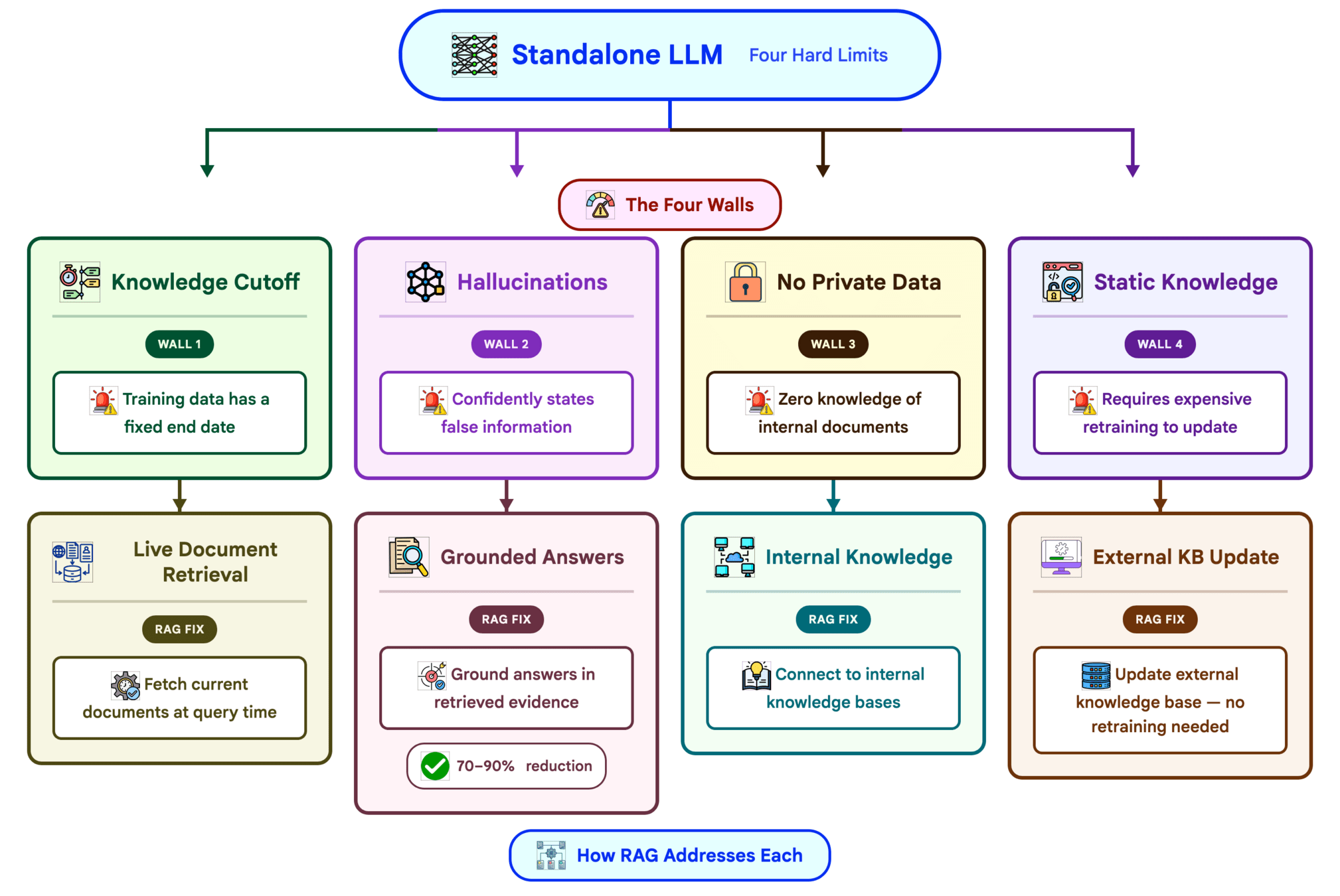
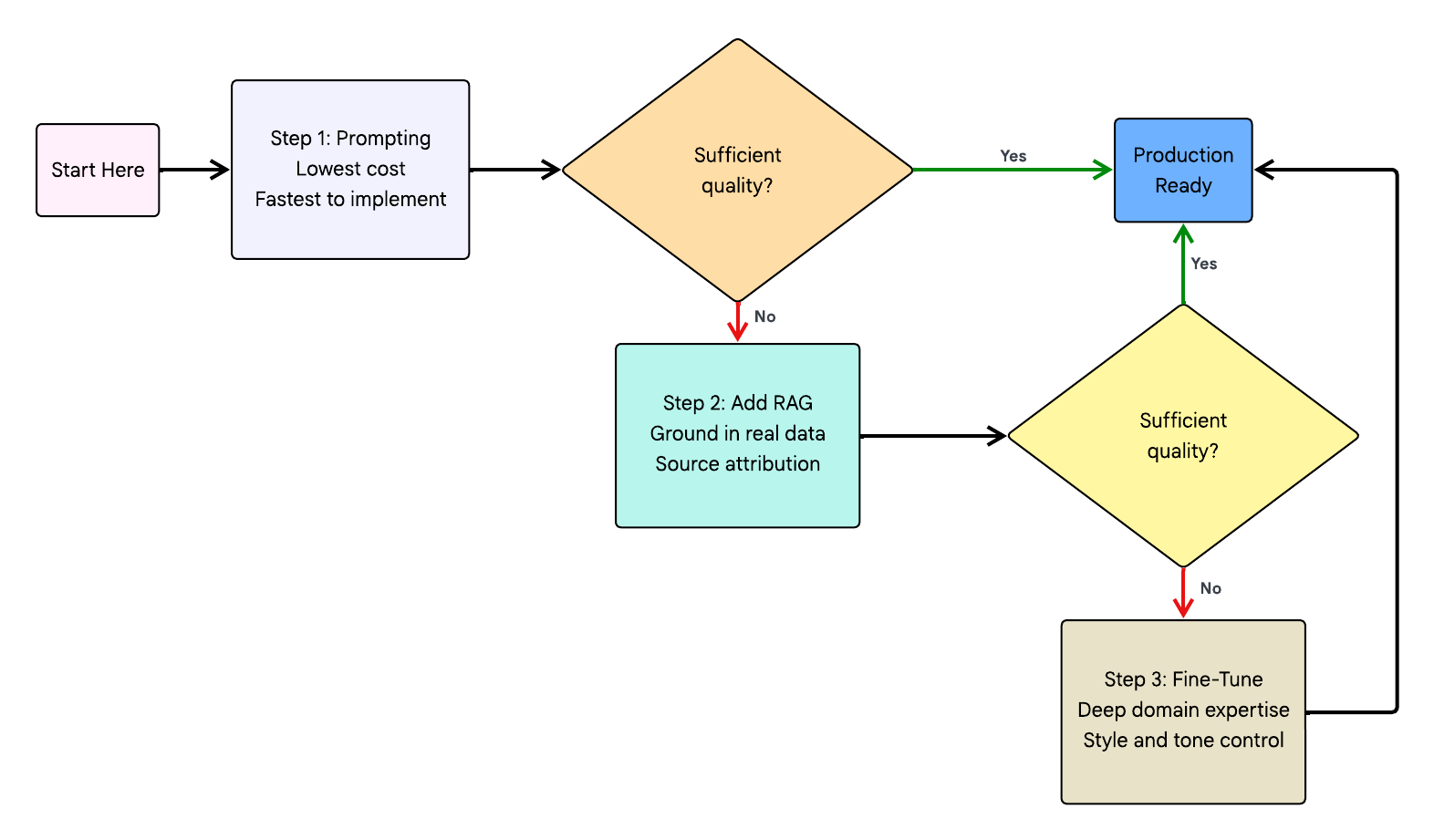
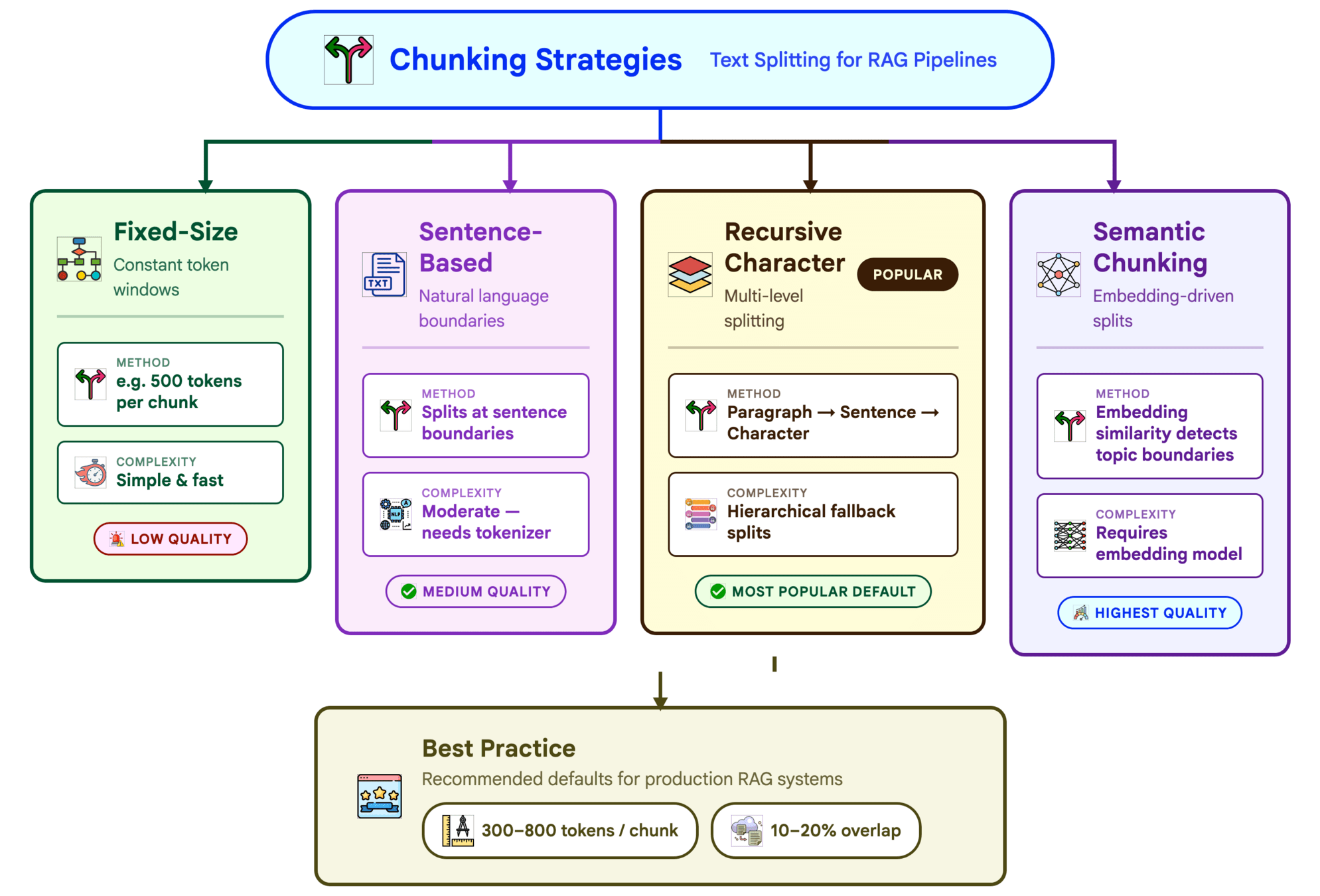
# ===== RAG Pipeline Implementation =====
# A complete Retrieval-Augmented Generation system
import os
import json
import hashlib
import numpy as np
from dataclasses import dataclass, field
from typing import List, Dict, Optional, Tuple
from datetime import datetime
@dataclass
class Document:
"""Represents a document in the knowledge base."""
id: str
content: str
metadata: Dict = field(default_factory=dict)
embedding: Optional[List[float]] = None
created_at: str = field(default_factory=lambda: datetime.now().isoformat())
def chunk(self, chunk_size: int = 512, overlap: int = 50) -> List["Document"]:
"""Split document into overlapping chunks."""
words = self.content.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk_words = words[i:i + chunk_size]
chunk_text = " ".join(chunk_words)
chunk_id = hashlib.md5(f"{self.id}_{i}".encode()).hexdigest()
chunks.append(Document(
id=chunk_id,
content=chunk_text,
metadata={**self.metadata, "parent_id": self.id, "chunk_index": i},
))
return chunks
class VectorStore:
"""Simple in-memory vector store using cosine similarity."""
def __init__(self, dimension: int = 384):
self.dimension = dimension
self.documents: Dict[str, Document] = {}
self.embeddings: Dict[str, np.ndarray] = {}
def add_document(self, doc: Document, embedding: List[float]) -> None:
"""Add a document with its embedding to the store."""
self.documents[doc.id] = doc
self.embeddings[doc.id] = np.array(embedding, dtype=np.float32)
def cosine_similarity(self, vec_a: np.ndarray, vec_b: np.ndarray) -> float:
"""Calculate cosine similarity between two vectors."""
dot_product = np.dot(vec_a, vec_b)
norm_a = np.linalg.norm(vec_a)
norm_b = np.linalg.norm(vec_b)
if norm_a == 0 or norm_b == 0:
return 0.0
return float(dot_product / (norm_a * norm_b))
def search(self, query_embedding: List[float], top_k: int = 5) -> List[Tuple[Document, float]]:
"""Find the top_k most similar documents to the query."""
query_vec = np.array(query_embedding, dtype=np.float32)
scores = []
for doc_id, doc_vec in self.embeddings.items():
similarity = self.cosine_similarity(query_vec, doc_vec)
scores.append((self.documents[doc_id], similarity))
scores.sort(key=lambda x: x[1], reverse=True)
return scores[:top_k]
def delete_document(self, doc_id: str) -> bool:
"""Remove a document from the store."""
if doc_id in self.documents:
del self.documents[doc_id]
del self.embeddings[doc_id]
return True
return False
def count(self) -> int:
return len(self.documents)
class RAGPipeline:
"""Main RAG pipeline: retrieve context, augment prompt, generate."""
def __init__(self, vector_store: VectorStore, model_name: str = "gpt-4"):
self.vector_store = vector_store
self.model_name = model_name
self.history: List[Dict] = []
def build_prompt(self, query: str, context_docs: List[Tuple[Document, float]]) -> str:
"""Construct the augmented prompt with retrieved context."""
context_block = "\n\n---\n\n".join(
f"[Source {i+1} | Score: {score:.3f}]\n{doc.content}"
for i, (doc, score) in enumerate(context_docs)
)
return (
f"Answer the question using ONLY the context below.\n"
f"If the context doesn't contain the answer, say so.\n\n"
f"### Context:\n{context_block}\n\n"
f"### Question:\n{query}\n\n"
f"### Answer:"
)
def query(self, question: str, top_k: int = 3) -> Dict:
"""Run the full RAG pipeline for a question."""
fake_embedding = np.random.randn(self.vector_store.dimension).tolist()
retrieved = self.vector_store.search(fake_embedding, top_k=top_k)
prompt = self.build_prompt(question, retrieved)
response = f"[Simulated {self.model_name} response for: {question}]"
result = {
"question": question,
"answer": response,
"sources": [{"id": doc.id, "score": s} for doc, s in retrieved],
"prompt_length": len(prompt),
"timestamp": datetime.now().isoformat(),
}
self.history.append(result)
return result