


















Elisa Beshero-Bondar PRO
Professor of Digital Humanities and Chair of the Digital Media, Arts, and Technology Program at Penn State Erie, The Behrend College.
An experiment with Small-Scale AI
Wednesday, 16 July 2025 and Wednesday, 6 August 2025
Alexander C. Fisher, Hadleigh Jae Bills, and Elisa Beshero-Bondar
Penn State Erie, The Behrend College
Link to Slides:
https://bit.ly/
digitai-dh25
A tool that assists scholars and editors in applying the TEI Guidelines to their own corpora
Supports learning by providing relevant examples, explanations, and excerpts directly from the TEI Guidelines
Wednesday, 16 July 2025
What we needed in a model:
Wednesday, 16 July 2025
Wednesday, 16 July 2025
Wednesday, 16 July 2025
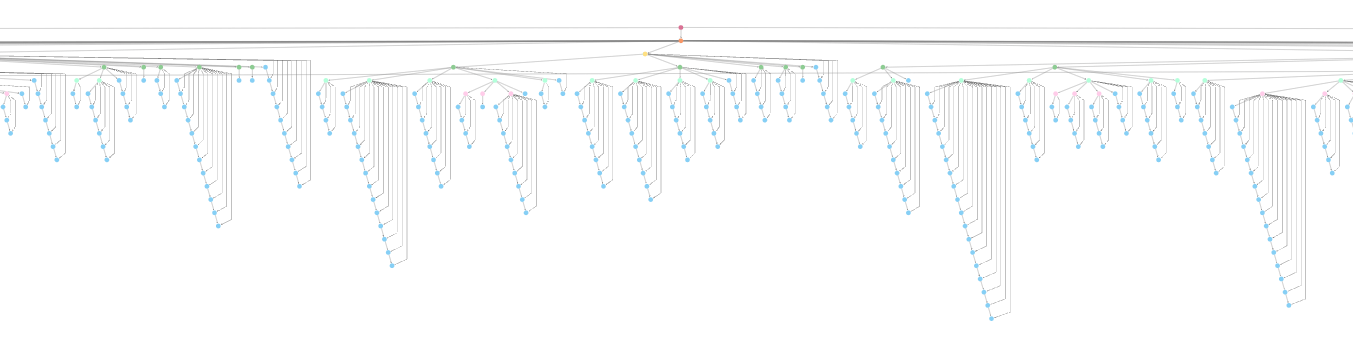
TEI Guidelines p5.xml: a single XML document that contains the entire built TEI Guidelines. It's a hierarchical (tree) structure:
Wednesday, 16 July 2025
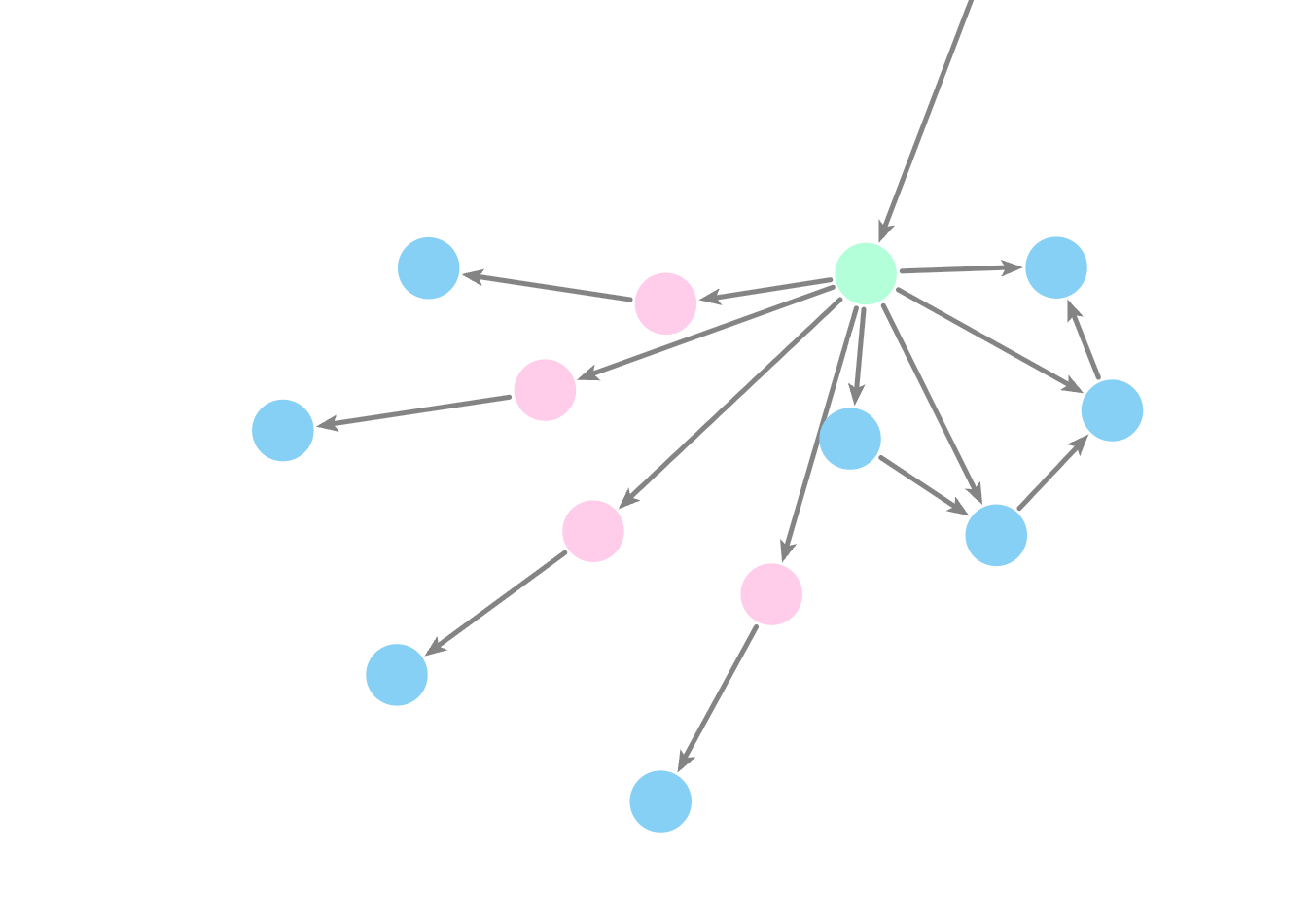
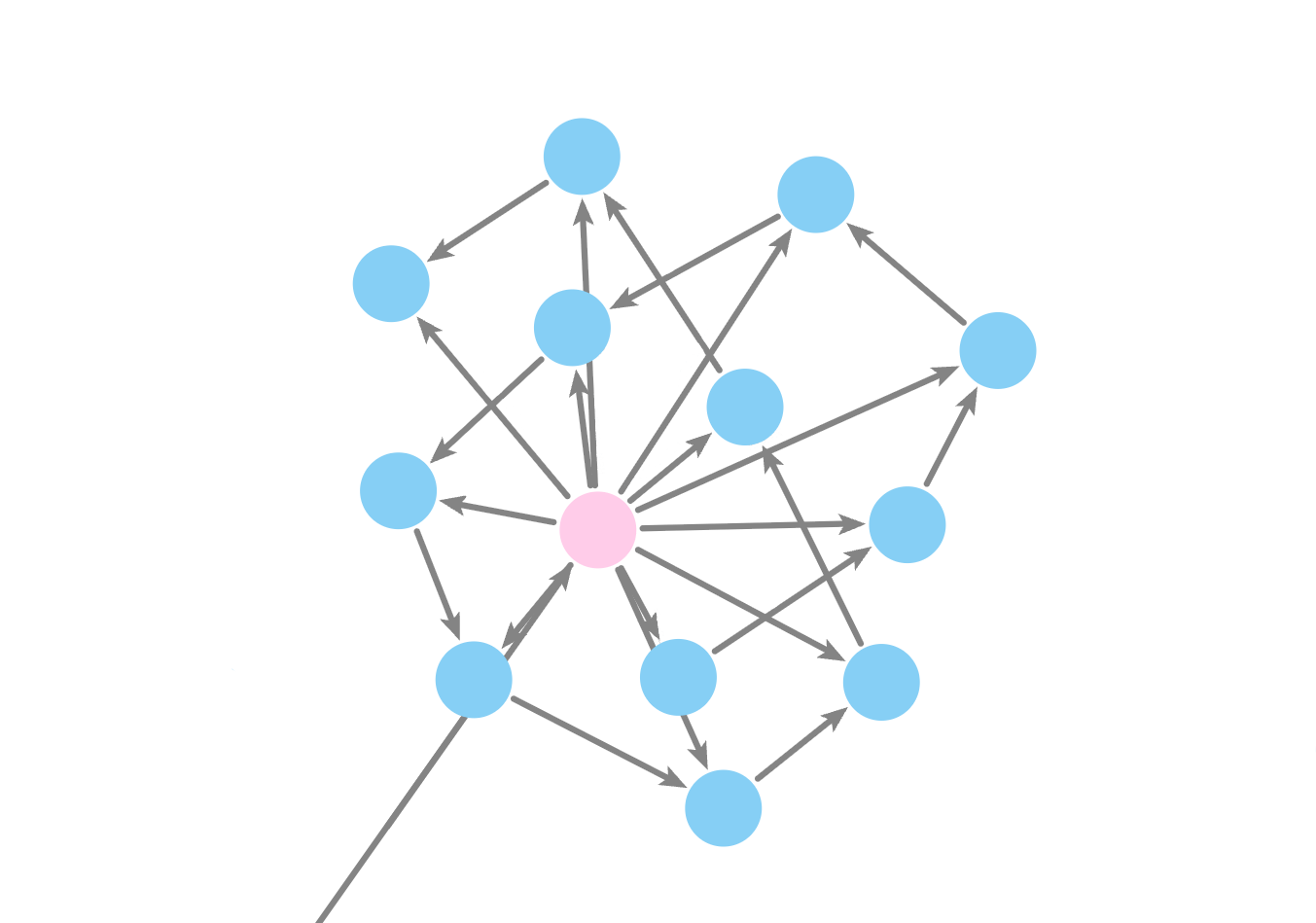
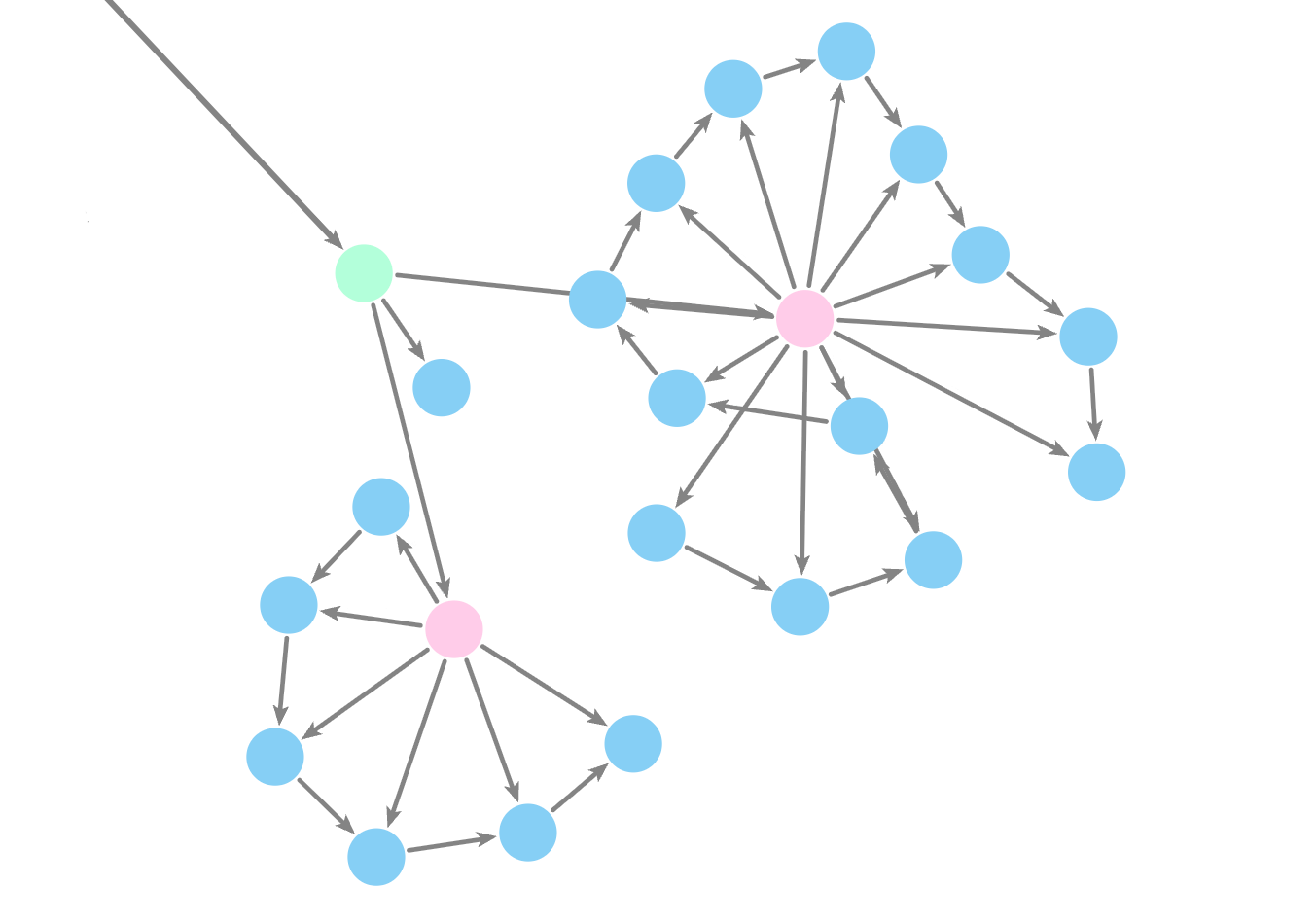
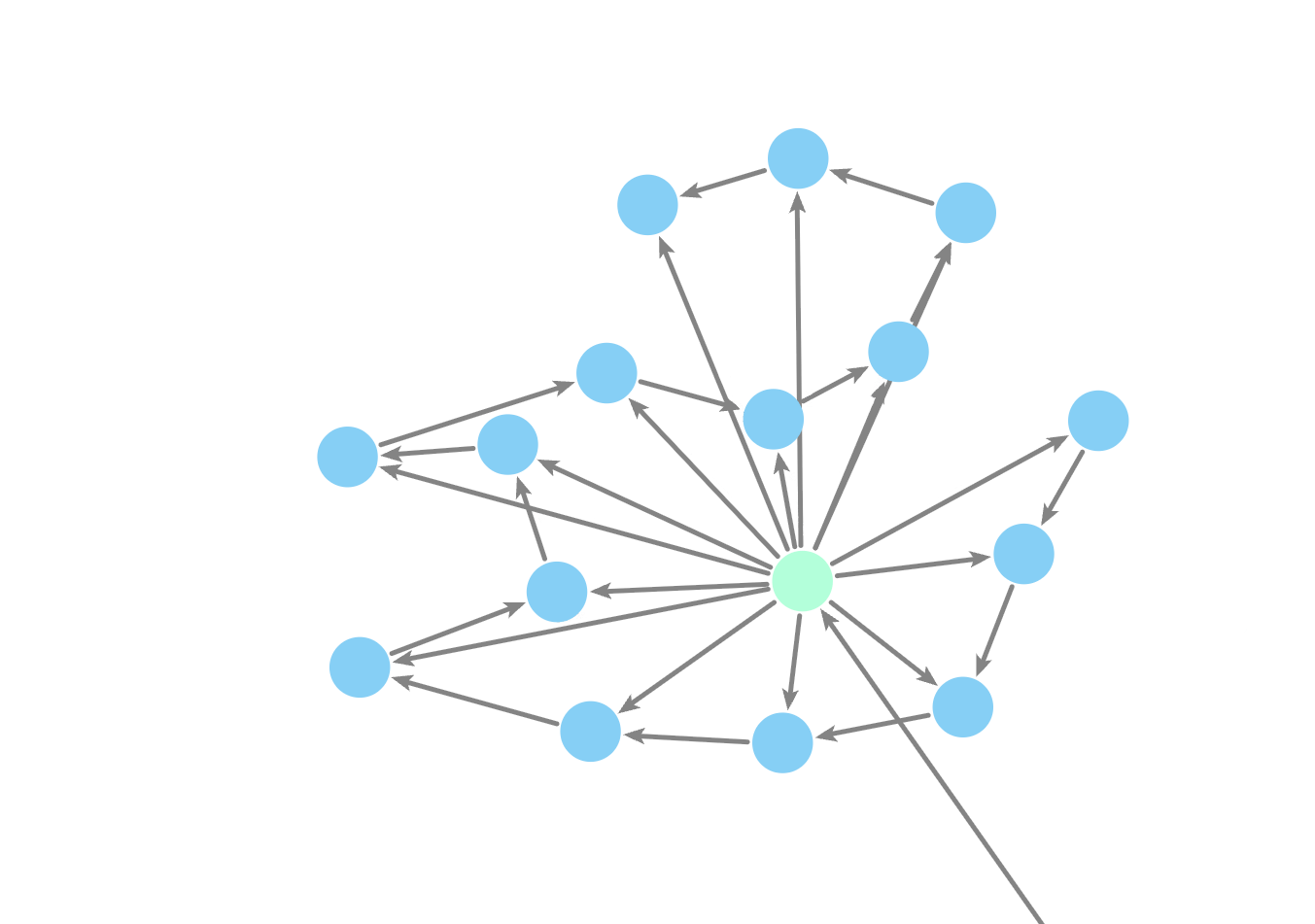
Making a knowlege graph: the challenge!
<XML>
<XSLT>
Neo4j
Knowledge Graph
LLM
Nodes
Relationships
<Cypher>
Wednesday, 16 July 2025
The Four Core Components of the DigitAI Retreival Pipeline
Neo4j Graph Database
BGE-M3 Embedding Model
FAISS Vector Search
Qwen2-7B Language Model
Wednesday, 16 July 2025
Neo4j is like a digital card catalog— it doesnt just store texts, it understands how they relate to each other
WITH doc, doc_data
FOREACH (part_data_1 IN doc_data.CONTAINS_PARTS |
MERGE (part:Part {name: part_data_1.PART}) SET part.sequence = part_data_1.SEQUENCE
MERGE (doc)-[:HAS_PART]->(part)
WITH part, part_data_1
FOREACH (chapter_data_2 IN part_data_1.CONTAINS_CHAPTERS |
MERGE (chapter:Chapter {chapter_id: chapter_data_2.ID})
SET chapter.sequence = chapter_data_2.SEQUENCE,
chapter.title = chapter_data_2.CHAPTER,
chapter.links = [x IN chapter_data_2.RELATES_TO WHERE x IS NOT NULL | x.ID]
MERGE (part)-[:HAS_CHAPTER]->(chapter)
WITH chapter, chapter_data_2 FOREACH (example_data_7 IN paragraph_data_6.TEI_ENCODING_DISCUSSED.CONTAINS_EXAMPLES |
MERGE (example:Example {example: example_data_7.EXAMPLE})
SET example.language = example_data_7.LANGUAGE
MERGE (paragraph)-[:HAS_EXAMPLE]->(example)
WITH example, example_data_7
FOREACH (paragraph_data_8 IN example_data_7.CONTAINS_END_PARAS |
MERGE (paragraph:TerminalPara {parastring: paragraph_data_8.PARASTRING})
SET paragraph.files_mentioned =
[x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.FILES_MENTIONED
WHERE x IS NOT NULL | x.FILE],
paragraph.parameter_entities_mentioned =
[x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.PES_MENTIONED WHERE x IS NOT NULL | x.PE],
paragraph.elements_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.ELEMENTS_MENTIONED
WHERE x IS NOT NULL | x.ELEMENT_NAME], paragraph.attributes_mentioned =
[x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.ATTRIBUTES_MENTIONED
WHERE x IS NOT NULL | x.ATTRIBUTE_NAME],
paragraph.sequence = paragraph_data_8.SEQUENCE,
paragraph.frags_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.FRAGS_MENTIONED
WHERE x IS NOT NULL | x.FRAG],
paragraph.ns_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.NSS_MENTIONED
WHERE x IS NOT NULL | x.NS],
paragraph.classes_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.CLASSES_MENTIONED
WHERE x IS NOT NULL | x.CLASS],
paragraph.modules_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.MODULES_MENTIONED
WHERE x IS NOT NULL | x.MODULE],
paragraph.macros_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.MACROS_MENTIONED
WHERE x IS NOT NULL | x.MACRO],
paragraph.speclist_links = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.CONTAINS_SPECLISTS.SPECLIST
WHERE x IS NOT NULL | x.ID],
paragraph.relaxng_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.RNGS_MENTIONED
WHERE x IS NOT NULL | x.RNG],
paragraph.datatypes_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.DATATYPES_MENTIONED
WHERE x IS NOT NULL | x.DATATYPE], paragraph.links = [x IN paragraph_data_8.RELATES_TO.SECTION
WHERE x IS NOT NULL | x.ID],
paragraph.parameter_entities_mentioned_ge = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.PES_MENTIONED
WHERE x IS NOT NULL | x.GE],
paragraph.schemas_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.SCHEMAS_MENTIONED
WHERE x IS NOT NULL | x.SCHEMA]
MERGE (example)-[:HAS_END_PARAGRAPH]->(paragraph)
) {"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:0", "text": null, "labels": ["Document"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:1", "text": null, "labels": ["Part"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:2", "text": null, "labels": ["Part"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:3", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:4", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:5", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:6", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:7", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:8", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:9", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:10", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:11", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:12", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:13", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:14", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:15", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:16", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:17", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:18", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:19", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:20", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:21", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:22", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:23", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:24", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:25", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:26", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:27", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:28", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:29", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:30", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:31", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:32", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:33", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:34", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:35", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:36", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:37", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:38", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:39", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:40", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:41", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:42", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:43", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:44", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:45", "text": null, "labels": ["Section"]}BGE-M3 acts as a translator!
Turns ideas into coordinates so similar meanings land "near" each other in vector space
It takes ~10 minutes to prepare embeddings from BGE-M3 on a machine with 128 GB RAM!
Wednesday, 16 July 2025
An FAISS search runs in a few milliseconds!
FAISS is like a highly efficient search engine that ranks results by context and meaning, not just keywords
Wednesday, 16 July 2025
FAISS
Neo4j Database
BGE-M3
Qwen LLM
Neo4j Database
BGE-M3
FAISS
RAG Embeddings
.JSONL
RAG Embeddings
.FAISS
Embedded Prompt
Generates Vector Embeddings from Node Text
RAG Embeddings Converted to FAISS Formatted Data Map
Data Map Compared to Embedded Query
Constructs Query
Top Matched Embeddings Retrieved as Text From Neo4j
Human Prompt
Wednesday, 16 July 2025
# === Get user input ===
query = input("❓ Enter your query: ").strip()
if not query:
print("⚠️ No query provided. Exiting.")
exit()# === Encode the query ===
query_embedding = model.encode(query)
# Convert to 2D array and normalize if cosine similarity is enabled
if normalize:
query_embedding = sk_normalize([query_embedding], norm="l2")
else:
query_embedding = np.array([query_embedding])
query_embedding = query_embedding.astype("float32")
# === Perform FAISS similarity search ===
TOP_K = 5 # Number of top matching texts to retrieve
scores, indices = index.search(query_embedding, TOP_K)
# Filter out invalid results (-1 = no match)
matched_ids = [id_map[i] for i in indices[0] if i != -1]
if not matched_ids:
print("⚠️ No relevant matches found in the FAISS index.")
exit()# === Fetch matching texts from JSONL file ===
def fetch_node_texts_by_ids(node_ids):
texts = []
with open(neo4jNodes, "r", encoding="utf-8") as f:
for line in f:
record = json.loads(line)
if record.get("id") in node_ids and record.get("text"):
texts.append(record["text"])
return texts
texts = fetch_node_texts_by_ids(matched_ids)
if not texts:
print("❌ No node texts found for matched IDs in local file.")
exit()# === Construct prompt for the LLM ===
context = "\n".join(f"- {text}" for text in texts)
prompt = f"""You are a chatbot that helps people understand
the TEI guidelines which specify how to encode machine-readable
texts using XML.
Answer the question below in the **same language the question is asked in**.
Use examples from the provided context as needed — they can be in any language.
Do not translate them.
Context:
{context}
Question:
{query}
"""
# === Send prompt to local Ollama LLM ===
def ask_ollama(prompt, model):
try:
response = requests.post(
"http://localhost:11434/api/generate",
json={
"model": model,
"prompt": prompt,
"stream": False
}
)
return response.json().get("response", "[ERROR] Empty response from LLM.")
except Exception as e:
print("❌ Error while querying Ollama:", e)
return "[ERROR] Could not get response from local LLM."
# === Query the model ===
print(f"🤖 Sending prompt to LLM ({llm_model})...")
answer = ask_ollama(prompt, llm_model)
# === Display the result ===
print("\n🧾 Response:\n")
print(answer)Wednesday, 16 July 2025
Wednesday, 16 July 2025
Wednesday, 16 July 2025
https://bit.ly/
digitai-github
GitHub:
https://bit.ly/
digitai-dh25
Slides:
https://bit.ly/
digitai-dh25
https://bit.ly/
digitai-jupyter
Jupyter Notebooks:
Enter your query:
What should I use to mark the title of a poem in a TEI document?
Sending prompt to LLM (qwen:7b) ...
Response:
Para marcar o título de uma poesia no formato TEI, você pode usar
um elemento específico como ‹title›' ou ‹head› contendo o texto do
título. Aqui está um exemplo:
'''xml
<tei>
<front>
<title>Onde os Ventos Cantam</title>
<! -- Other frontmatter elements -->
</front>
<! -- Rest of the TEI document -->
</tei>
'''
No codigo acima, '<titles>' foi usado para indicar o titulo da
poesia. Lembre-se de substituir "Onde os Ventos Cantam" pelo
título real que deseja registrar.By Elisa Beshero-Bondar
A presentation about a small explainable AI project to fine-tune a language model with a graph RAG built with the TEI Guidelines.


