Ethan Yeh
INFOR 38th — 學術
INFOR38 葉倚誠
建資 37th 社員
概述與字串基礎
字典樹 Trie
KMP Algorithm
有限自動機 Finite Automaton
廣度優先搜尋 BFS
AC 自動機
題
假設我要在一個文本中 找到多個模式字串
若文本長度 N;模式字串個數 M;模式字串總長度 L
暴力匹配時時間複雜度會達到 O(NML)
AC 自動機本質上是建立在 Trie 上的有限自動機
透過 Trie + 失配連結,在多模式字串匹配時
可以做到近似線性的時間複雜度!
假設我們有字串 S,關於字串 S 有以下定義
子字串:S 的某一個部分,S[i...j]表示 S從i到j的這一段
前綴:從字串開始一直到某個字串的某個位置所形成到子字串
後綴:從字串的某個位置一直到字串結尾所形成的子字串
真前綴/真後綴:字串 S 的前/後綴,但不包含字串 S 本身
模式字串匹配:在字串S中檢查是否包含子字串T,T為模式字串
又稱前綴樹 (Prefix Tree)
如字典一樣儲存很多字串
節點儲存字元,並彼此串連
字串間可以共享前綴
支援插入 、尋找(前綴)、統計等操作
(root)
├── a
│ ├── p
│ │ ├── e (ape)
│ │ ├── x (apex)
│ │ └── p ── l ── e (apple)
├── b
│ ├── a ── t
│ │ ├── c ── h (batch)
│ │ ├── h (bath)
│ │ └── (bat)
├── c
│ ├── a ── t
│ │ ├── c ── h (catch)
│ │ └── (cat)
│ ├── o ── w
│ ├── e ── r (cower)
│ └── (cow)
By ChatGPT
class Trie {
private:
struct Node {
bool isEnd; // 檢測是否為字串結尾
unordered_map<char, Node*> children;
Node() : isEnd(false) {} 初始化 isEnd 為 false
~Node() { // 釋放記憶體
for (auto& child : children) {
delete child.second;
}
}
};
Node* root; // 建立根節點
public:
Trie() : root(new Node()) {} // 初始化根節點
~Trie() { // 釋放記憶體
delete root;
}
};
void insert(const string& word) {
Node* cur = root;
for (const char &c : word) {
if (cur->children.find(c) == cur->children.end()) {
cur->children[c] = new Node();
}
cur = cur->children[c];
}
cur->isEnd = true;
}bool search(const string& word) {
Node* cur = root;
for (const char& c : word) { // 遍歷 word 中的字元
// 不存在字典樹中,回傳 false
if (cur->children.find(c) == cur->children.end()) return false;
cur = cur->children[c];
}
return cur->isEnd; // 檢查是否為字串結尾
}
bool startsWith(const string& prefix) {
Node* cur = root;
for (const char& c : prefix) {
if (cur->children.find(c) == cur->children.end()) return false;
cur = cur->children[c];
}
return true; // 不論是否為字串結尾接回傳 true
}如果我想要在 S = "ababcababa" 中找到模式字串 P = "ababa"
暴力炸開?
| a | b | a | b | c | a | b | a | b | a |
| a | b | a | b | a |
時間複雜度 O(|S|*|P|) 💣
| a | b | a | b | a |
| a |
| a | b | a | b | a |
| a |
| a | b | a | b | a |
| a |
| a | b | a | b | a |
| a |
| a | b | a | b | a |
| a |
可以用配對失敗的資訊,避免不必要的配對
| a | b | a | b | c | a | b | a | b | a |
| a | b | a | b | a |
匹配階段的時間複雜度僅有 O(|S|)!
| a | b | a | b | a |
| a |
| a | b |
| a | b | a | b | a |
| a |
| a | b |
| a | b | a | b | a |
| a |
| a | b |
| a | b |
範例中的模式字串 P = "ababa" 配對之前
可以先對 P 做預處理 (時間複雜度 O(|P|))
取得字串 P[0...j] (1 <= j <= p ) 的最長相等真前綴與真後綴
定義為 前綴函數 ,以 π 表示
舉例來說,有模式字串 P = "ababa"
已經匹配了 "abab",但在 P[4] = 'a' 失配
文本:... a b a b x ...
模式: a b a b a
^ 失配文本:... a b a b x ...
模式: a b a b a
^ 從這裡繼續匹配 (跳過 π[3] 個位置)文本:... a b a b x ...
模式: a b a b a
又稱為 π 函數 / 失配函數 / Failure Function
代表模式字串最長的相等真前綴與真後綴長度
π[i] = max{j | 0 < j ≤ i, S[0...j-1] = S[i-j+1...i]},π[0] = 0
E.g. 對於字串 "abcabcdabc"
π[0] = 0 π[5] = 3
π[1] = 0 π[6] = 0
π[2] = 0 π[7] = 1
π[3] = 1 π[8] = 0
π[4] = 2 π[9] = 0
#include <bits/stdc++.h>
#define endl '\n'
using namespace std;
vector<int> prefix_function(const string &s) { // π 函數
const int n = s.size(); // n = 字串長度
vector<int> pi(n); // 儲存 π 函數
for (int i = 1; i < n; ++i) {
for (int j = i; j >= 0; --j) {
// 檢查 s[0:k] 與 s[i-j+1:i+1] 是否一致 (相等真前綴/後綴)
if (s.substr(0, j) == s.substr(i - j + 1, i + 1)) {
pi[i] = j;
break; // 找到最長真前綴/後綴後跳出迴圈
}
}
}
return pi;
}
對於一個長度為 n 的字串
最長真前綴/後綴一定會小於等於 n - 1
所以我們有 π[i] <= i-1;π[i + 1] <= i
⇒ π[i + 1] - π[i] <= 1
也就是說,j 可以改成從 π[i - 1] 開始!
#include <bits/stdc++.h>
#define endl '\n'
using namespace std;
vector<int> prefix_function(const string &s) { // π 函數
const int n = s.size(); // n = 字串長度
vector<int> pi(n); // 儲存 π 函數
for (int i = 1; i < n; ++i) {
for (int j = pi[i - 1]; j >= 0; --j) { // 讓 j 從 π[i - 1] 開始
// 檢查 s[0:k] 與 s[i-j+1:i+1] 是否一致 (相等真前綴/後綴)
if (s.substr(0, j) == s.substr(i - j + 1, i + 1)) {
pi[i] = j;
break; // 找到最長真前綴/後綴後跳出迴圈
}
}
}
return pi;
}
經過了第一次優化之後
時間複雜度降為 O(n²),但最終目標是 O(n)
考慮用類似動態規劃的想法來解
如果要求 π[i],可以利用已知的 π[i -1]
例如對於字串 S = "ababcab",有 π [3] = 2,要求π [4]
從 π[3] = 2 得知 S[0...3] 有相等真前綴/後綴 "ab"
比較前/後綴的下一個字母 (S[2] = 'a',S[4] = '4')
失配,指針回退至 π[1] = 0,比較 S[0] 及 S[4]
重複直到找到π 函數值或無法再回退 (此時 π 函數 = 0)
| a | b | a | c | a | b | a | b |
| 0 | 0 | 1 | 0 | 1 | 2 |
| a |
| b |
| b |
| a |
| a |
| a |
| b |
| c |
| 3 |
| a |
| b |
| a |
2
3
1
3
| a | b | a | c | a | b | a | b |
| 0 | 0 | 1 | 0 | 1 | 2 |
| a |
| a |
| b |
| b |
| 3 |
| 2 |
#include <bits/stdc++.h>
#define endl '\n'
using namespace std;
vector<int> prefixFunction(const string &s) {
const int n = s.size(); // 字串的長度
vector<int> pi(n); // 儲存前綴函數的陣列,大小為字串長度
for (int i = 1; i < n; ++i) {
int j = pi[i - 1]; // 取得前一個位置的前綴函數值
// 若匹配失敗,則沿著前綴函數回溯到更短的前綴
while (j > 0 && s[i] != s[j]) {
j = pi[j - 1];
}
// 若匹配成功,將前綴函數值加 1
if (s[i] == s[j]) {
++j;
}
pi[i] = j;
}
return pi;
}
vector<int> kmp(const string &s, const string &p) {
const int n = s.size(), m = p.size();
vector<int> pi = prefixFunction(p); // 計算前綴函數
vector<int> res;
for (int i = 0, j = 0; i < n; ++i) {
// 若匹配失敗,則沿著前綴函數回溯到更短的前綴
while (j > 0 && s[i] != p[j]) {
j = pi[j - 1];
}
// 若匹配成功,匹配長度加 1
if (s[i] == p[j]) {
++j;
}
// 如果匹配長度等於模式字串長度,表示匹配成功
if (j == m) {
res.push_back(i - m + 1); // 儲存匹配的位置
j = pi[j - 1];
}
}
return res;
}int main() {
string s, p;
cin >> s >> p;
vector<int> res = kmp(s, p);
for (const auto &i : res) {
cout << i << "";
}
cout << endl;
return 0;
}ababaababc5代表一個字串集合 (F) 的抽象數學模型
用於判斷輸入字串是否屬於該集合
分為 DFA、NFA (確定 / 非確定)
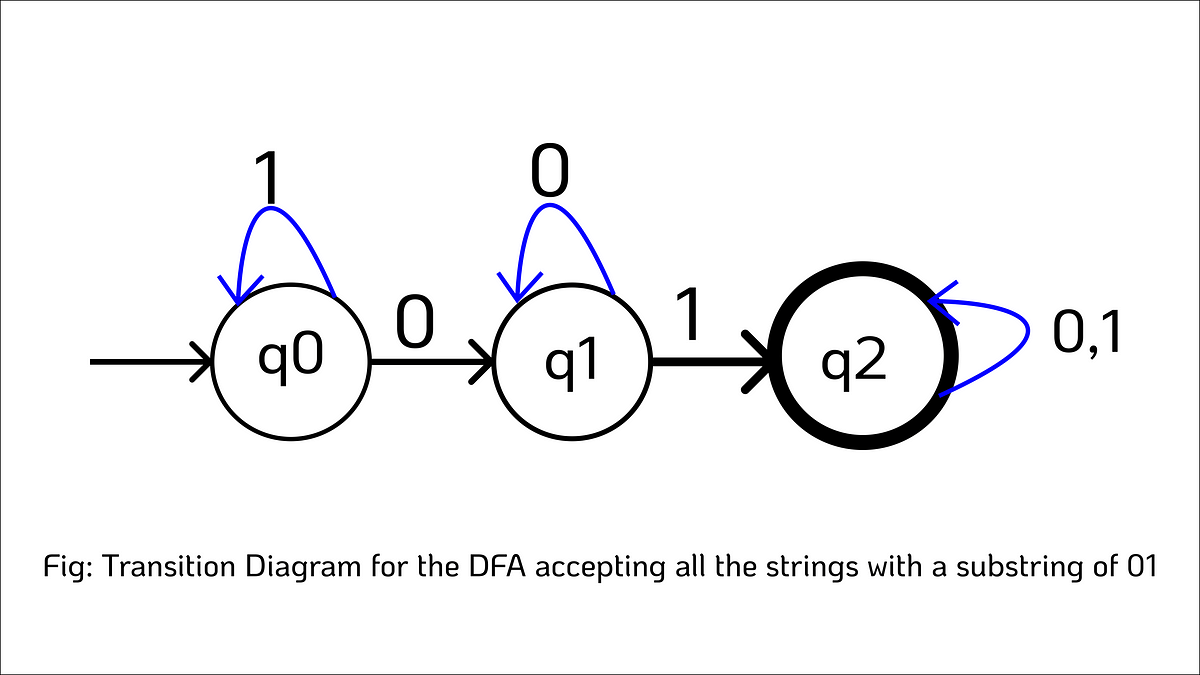
由以下元素組成:
Q = {q0, q1, q2}
∑ = {0, 1}
F = {q2}
僅接受 "01" 的自動機 (DFA)
Trie 也是一種自動機!
(root)
├── a
│ ├── p
│ │ ├── e (ape)
│ │ ├── x (apex)
│ │ └── p ── l ── e (apple)
├── b
│ ├── a ── t
│ │ ├── c ── h (batch)
│ │ ├── h (bath)
│ │ └── (bat)
├── c
│ ├── a ── t
│ │ ├── c ── h (catch)
│ │ └── (cat)
│ ├── o ── w
│ ├── e ── r (cower)
│ └── (cow)
| DFA | NFA |
|---|---|
| 確定有限自動機 | 非確定有限自動機 |
| 輸入對轉換為一一對應 | 輸入對轉換可以一對多 |
| 不允許 ε 轉換 | 允許 ε 轉換 |
| n(Q) 通常大於等價 NFA | n(Q) 通常小於等價 DFA |
| O(|S|) | O(|S| * n(Q)) |
| 任何 NFA 皆可轉換為等價 DFA |
| 皆能使用正規表達式 |
Trie + 失配連結 (運用 KMP 邏輯) 所構成的有限自動機 = AC 自動機
將所有模式字串加入 Trie 中
使用 BFS 從 root 開始遍歷,建立失配連結
*建立輸出連結
進行字串匹配
時間複雜度:建立 Trie / 失配連結 + 字串匹配 = O(L + M + N)
M:模式字串總長度;N:文本長度;Z:成功匹配總數
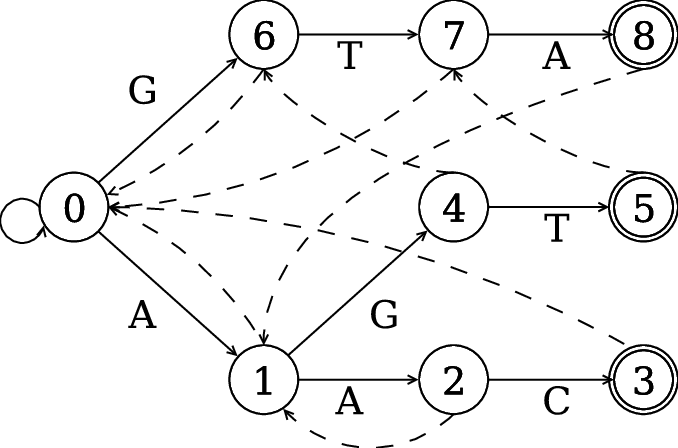
E.g. 若在節點 4 -> 5 失配,因為已經匹配 'G',所以透過失配連結轉移到節點 6 繼續匹配
目標:找尋當前路徑的最長後綴與 Trie 中某個模式字串前綴的匹配位置
使用 BFS:計算節點的失配連結時,需利用其父節點的失配連結
根節點失配連結指向自己
根節點的直接子節點的失配連結指向根節點 (第一個就失配只能回到原點)
void buildFailLinks() {
queue<Node*> q;
// 將根節點的子節點的失配連結為根節點
for (const auto &child : root->children) {
child.second->fail = root;
q.push(child.second);
}
// 使用 BFS 遍歷所有節點
while (!q.empty()) {
Node *cur = q.front();
q.pop();
// 為當前節點的每個子節點建立失配連結
for (const auto &child : cur->children) {
Node *fail = cur->fail; // 從當前節點的失配連結開始
// 找到失配指針指向的節點,若匹配失敗則沿著失配連結走,直到匹配成功或回到根節點
while (fail != root && fail->children.find(child.first) == fail->children.end()) {
fail = fail->fail;
}
// 若找到匹配的子節點,建立失配連結
if (fail->children.find(child.first) != fail->children.end()) {
child.second->fail = fail->children[child.first];
} else {
child.second->fail = root;
}
q.push(child.second); // 將子節點加入佇列中
}
}
}用一個指針遍歷文本,指針從不回退
將每個遍歷到的字符沿著 Trie 匹配
若遍歷到字串結尾,將對應的模式字串索引值及其出現的位置存入
匹配成功後沿著當前節點的失配連結走,找出所有匹配避免遺漏 (E.g. 若有模式字串 "abc"、"bc",匹配 "abc" 等同於匹配 "bc")
若失配則沿著失配連結繼續嘗試匹配
遍歷文本後匹配結束,達成近似線性時間複雜度
vector<pair<int, int>> search(const string &text) { vector<pair<int, int>> res;
Node *cur = root;
const int SIZE = text.size();
for (int i = 0; i < SIZE; ++i) {
const char c = text[i];
// 若匹配失派,則沿著失配連結走
while (cur != root && cur->children.find(c) == cur->children.end()) {
cur = cur->fail;
}
if (cur->children.find(c) != cur->children.end()) {
cur = cur->children[c]; // 若匹配成功,則移動到該子節點
}
// 檢查當前節點及其失配連結上的節點是否為接受狀態 (模式字串結尾)
Node *tmp = cur;
while (tmp != root) {
if (tmp->isEnd) {
res.push_back({i - patterns[tmp->index].size() + 1, tmp->index});
}
tmp = tmp->fail; // 沿著失配連結檢查
}
}
return res;
}當前的字串匹配函數中,每找到一個接受狀態 (模式字串結尾)
我們都需要沿著失配連結走一次,檢查有沒有遺漏的字串
這會讓時間複雜度增加不少
可以考慮加上一個輸出連結,如果找到接受狀態
藉由輸出連結可以直接找到所有匹配到的模式字串
這樣做就能真正達到近似線性的時間複雜度!
#include <bits/stdc++.h>
#define endl '\n'
using namespace std;
class AhoCorasick {
private:
struct Node {
unordered_map<char, Node*> children;
Node* fail;
bool isEnd;
int index;
vector<int> outputs; // 建立輸出連結
Node() : fail(nullptr), isEnd(false), index(-1) {}
};
Node* root;
vector<string> patterns;
public:
AhoCorasick() {
root = new Node();
}
~AhoCorasick() {
queue<Node*> q;
q.push(root);
while (!q.empty()) {
Node* cur = q.front();
q.pop();
for (const auto& child : cur->children) {
q.push(child.second);
}
delete cur;
}
}
void insert(const string& p) {
Node* cur = root;
for (char c : p) {
if (cur->children.find(c) == cur->children.end()) {
cur->children[c] = new Node();
}
cur = cur->children[c];
}
cur->isEnd = true;
cur->index = patterns.size();
patterns.push_back(p);
}
void buildFailLinks() {
queue<Node*> q;
for (const auto& child : root->children) {
child.second->fail = root;
q.push(child.second);
}
while (!q.empty()) {
Node* cur = q.front();
q.pop();
for (const auto& child : cur->children) {
Node* fail = cur->fail;
while (fail != root && fail->children.find(child.first) == fail->children.end()) {
fail = fail->fail;
}
if (fail->children.find(child.first) != fail->children.end()) {
fail = fail->children[child.first];
}
child.second->fail = fail;
q.push(child.second);
}
if (cur->isEnd) { // 如果當前節點為接受狀態,則加入輸出連結
cur->outputs.push_back(cur->index);
}
// 將失配連結的所有輸出都加到自己的輸出連結
for (int idx : cur->fail->outputs) {
cur->outputs.push_back(idx);
}
}
}
vector<pair<int, int>> search(const string& text) {
vector<pair<int, int>> res;
Node* cur = root;
const int SIZE = text.size();
for (int i = 0; i < SIZE; ++i) {
const char c = text[i];
while (cur != root && cur->children.find(c) == cur->children.end()) {
cur = cur->fail;
}
if (cur->children.find(c) != cur->children.end()) {
cur = cur->children[c];
}
// 使用輸出連結直接獲取所有可能的匹配
for (int index : cur->outputs) {
res.push_back({i - patterns[index].size() + 1, index});
}
}
return res;
}
};
可以使用建立完成的 AC 自動機
完成一個簡易的敏感字詞過濾器
輸入文本及敏感字詞
輸出時將敏感字詞轉換為星號
#include <bits/stdc++.h>
#define endl '\n'
using namespace std;
class AhoCorasick {
private:
struct Node {
unordered_map<char, Node*> children;
Node* fail;
bool isEnd;
int index;
vector<int> outputs;
Node() : fail(nullptr), isEnd(false), index(-1) {}
};
Node* root;
public:
vector<string> patterns;
AhoCorasick() {
root = new Node();
}
~AhoCorasick() {
queue<Node*> q;
q.push(root);
while (!q.empty()) {
Node* cur = q.front();
q.pop();
for (const auto& child : cur->children) {
q.push(child.second);
}
delete cur;
}
}
void insert(const string& p) {
Node* cur = root;
for (char c : p) {
if (cur->children.find(c) == cur->children.end()) {
cur->children[c] = new Node();
}
cur = cur->children[c];
}
cur->isEnd = true;
cur->index = patterns.size();
patterns.push_back(p);
}
void buildFailLinks() {
queue<Node*> q;
for (const auto& child : root->children) {
child.second->fail = root;
q.push(child.second);
}
while (!q.empty()) {
Node* cur = q.front();
q.pop();
for (const auto& child : cur->children) {
Node* fail = cur->fail;
while (fail != root && fail->children.find(child.first) == fail->children.end()) {
fail = fail->fail;
}
if (fail->children.find(child.first) != fail->children.end()) {
fail = fail->children[child.first];
}
child.second->fail = fail;
q.push(child.second);
}
if (cur->isEnd) {
cur->outputs.push_back(cur->index);
}
for (int idx : cur->fail->outputs) {
cur->outputs.push_back(idx);
}
}
}
vector<pair<int, int>> search(const string& text) {
vector<pair<int, int>> res;
Node* cur = root;
const int SIZE = text.size();
for (int i = 0; i < SIZE; ++i) {
const char c = text[i];
while (cur != root && cur->children.find(c) == cur->children.end()) {
cur = cur->fail;
}
if (cur->children.find(c) != cur->children.end()) {
cur = cur->children[c];
}
for (int index : cur->outputs) {
res.push_back({i - patterns[index].size() + 1, index});
}
}
return res;
}
};
int main() {
AhoCorasick ac;
int n;
cin >> n;
while (n--) {
string word;
cin >> word;
ac.insert(word);
}
ac.buildFailLinks();
string input;
cin >> input;
vector<pair<int, int>> matches = ac.search(input);
if (matches.empty()) {
cout << input << endl;
} else {
sort(matches.begin(), matches.end(), [](const auto& a, const auto& b) {
return a.first > b.first;
});
for (const auto& match : matches) {
int start = match.first;
int index = match.second;
string patt = ac.patterns[index];
input.replace(start, patt.size(), string(patt.size(), '*'));
}
}
cout << endl;
return 0;
}
By Ethan Yeh



