Yuan-Sen Ting
The Ohio State University
On Measuring Elemental Abundances
With Machine Learning
Why machine learning in the first place?
What is The Payne by the way?
And no, it was not about a neural network emulator
Full spectral fitting for all labels is needed even at high-rez
Manganese
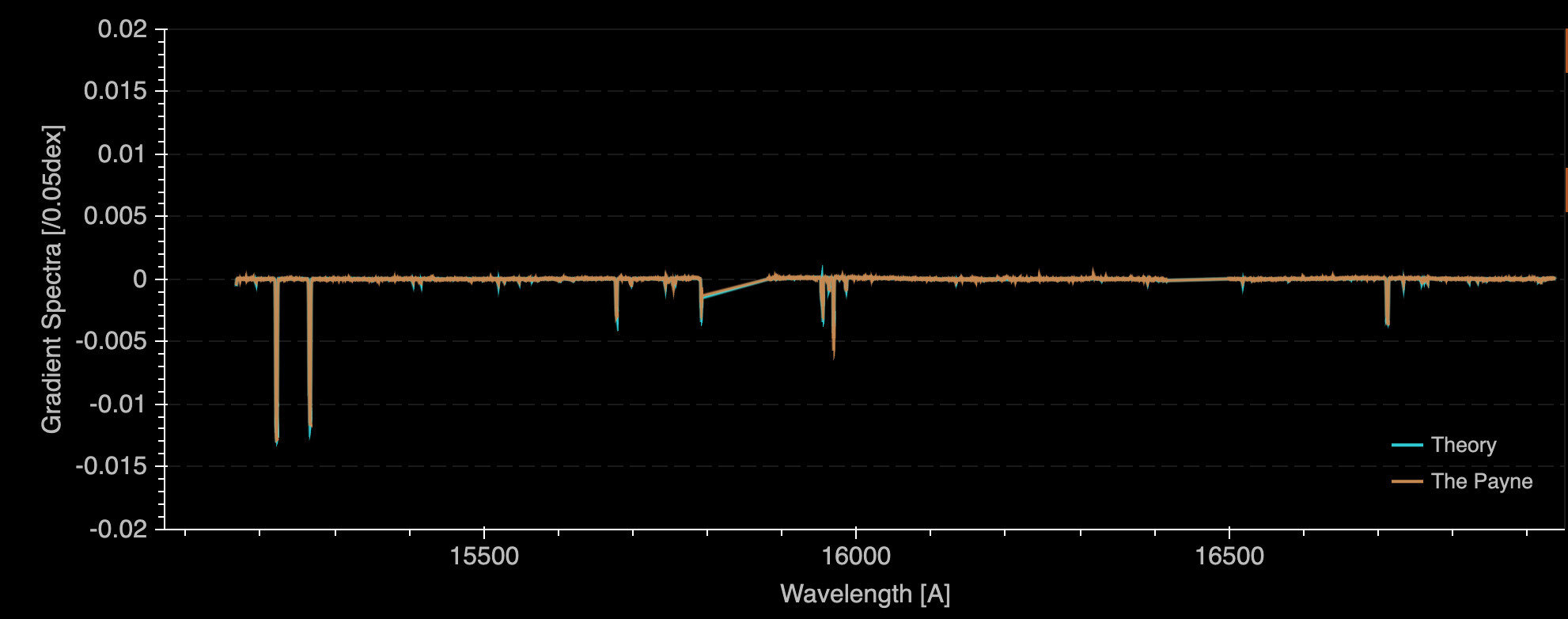
Direct atomic transitions
Wavelength [A]
d flux / d abundance
YST, Conroy, Rix+ 18
Magnesium
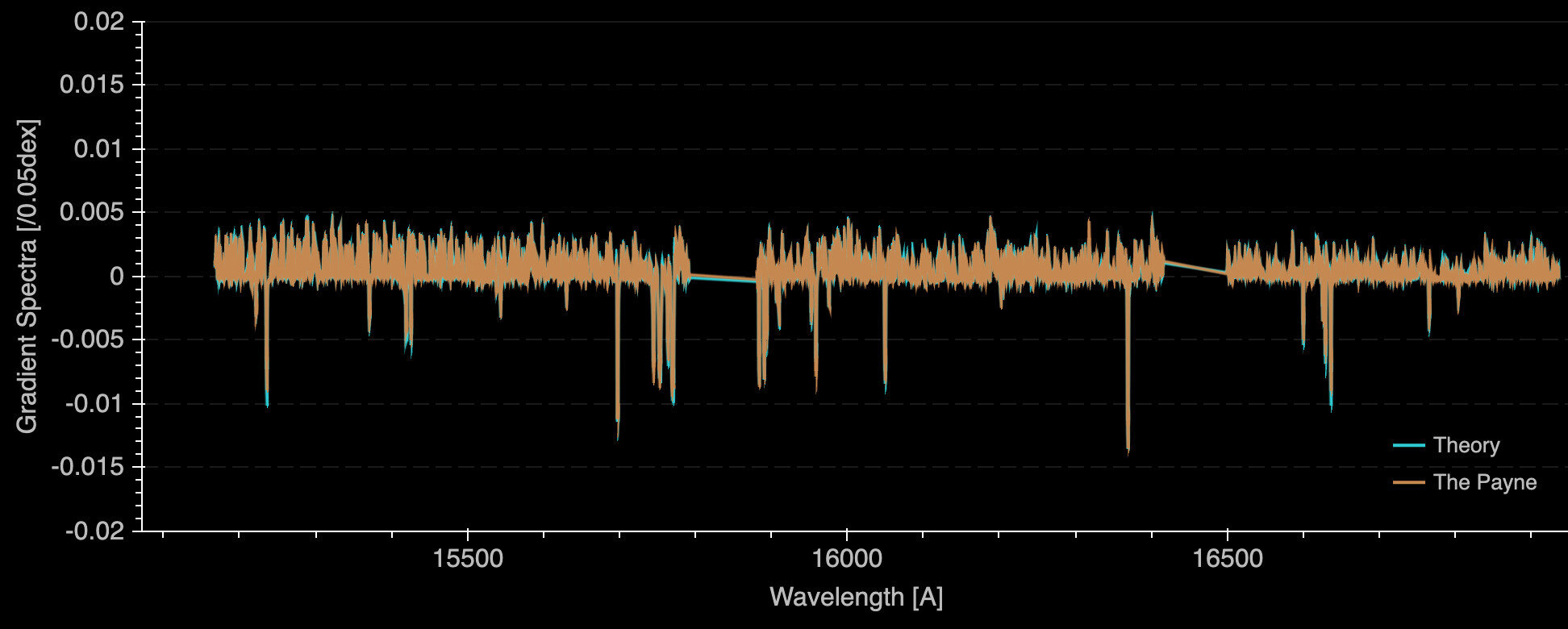
Atomic transitions
Wavelength [A]
d flux / d abundance
Alteration of stellar atmosphere
YST, Conroy, Rix+ 18
Full spectral fitting for all labels is needed even at high-rez
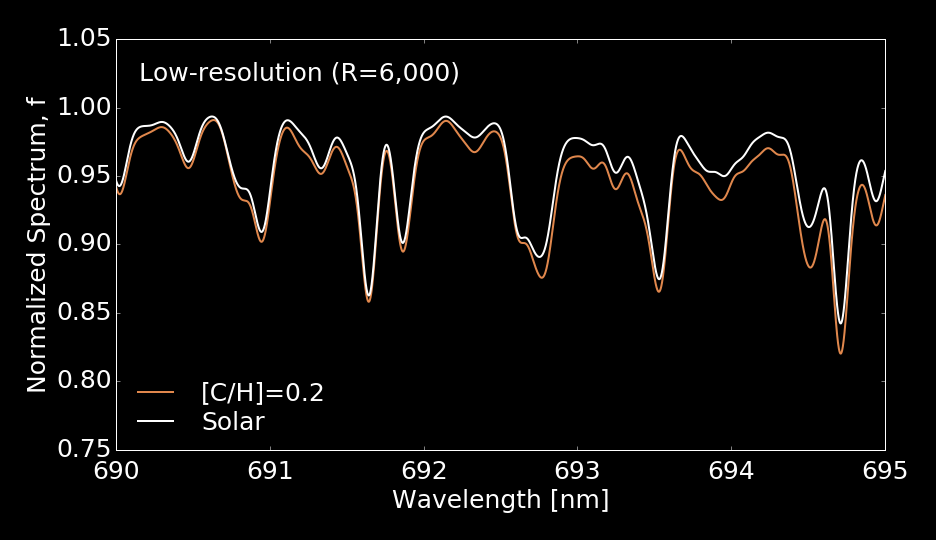
Low resolution
Features blend at low-resolution
Full-spectral fitting is essential for analyzing low-rez spectra
Wavelength [A]
6900
6920
6940
Normalized Spectrum
0.4
0.6
0.8
1.0
To Enable Full-Spectral Fitting
An effective high-dimensional emulator ("interpolator"), mapping from ~20D (number of labels) to O(1000)D (number of pixels)
Overcoming systematics due to imperfect models
- or the synthetic-observation gap
Curse of dimensionality: requires exponentially large data sets


Curse of Dimensionality
Deep Learning
"I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail"
Abraham Maslow

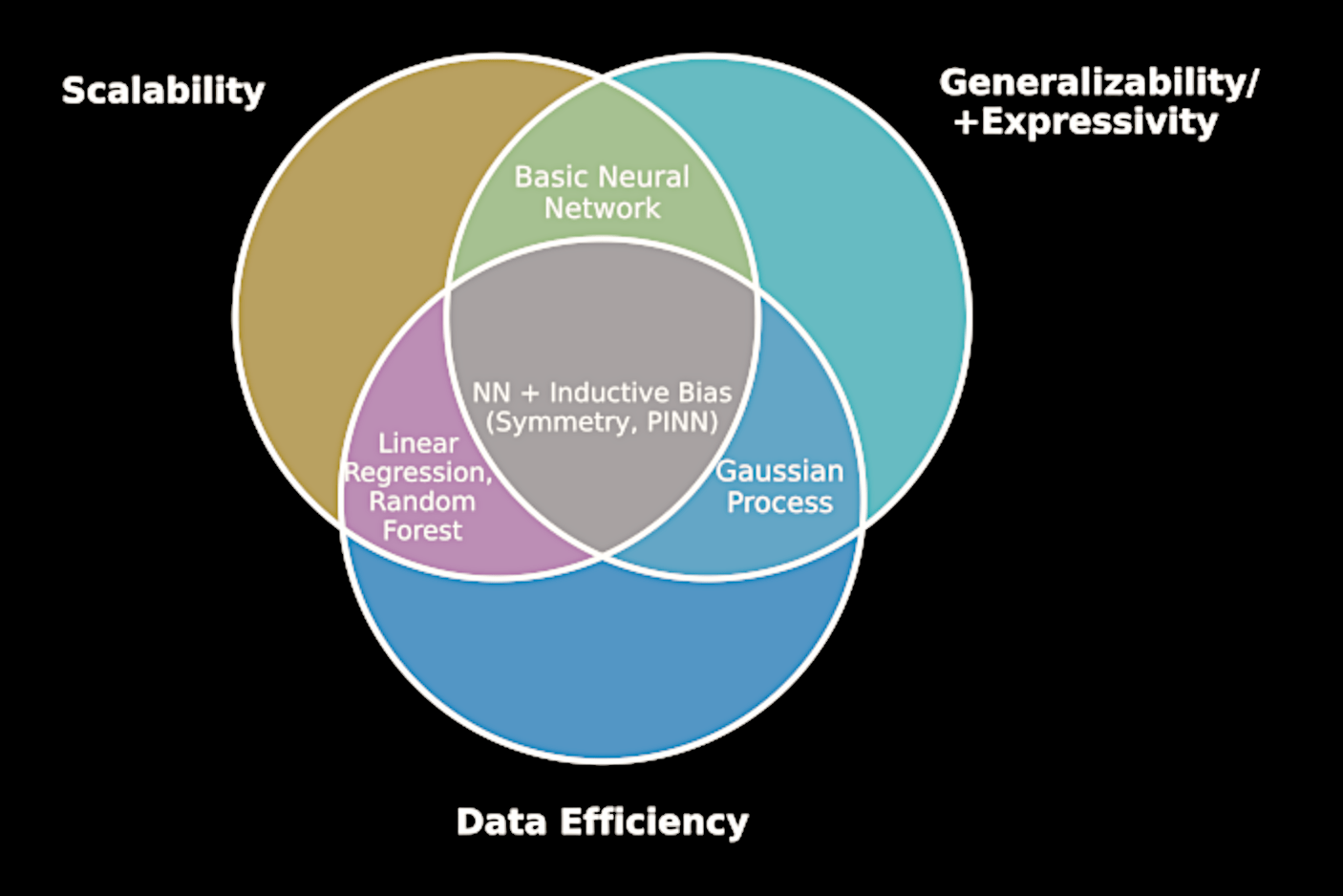
Task

The ML tool with the relevant assumptions


Blindly applying machine learning
Classical tool
A theoretical understanding of deep learning
makes a big difference

Neural Networks
Convolutional neural networks have incorrect"inductive bias"
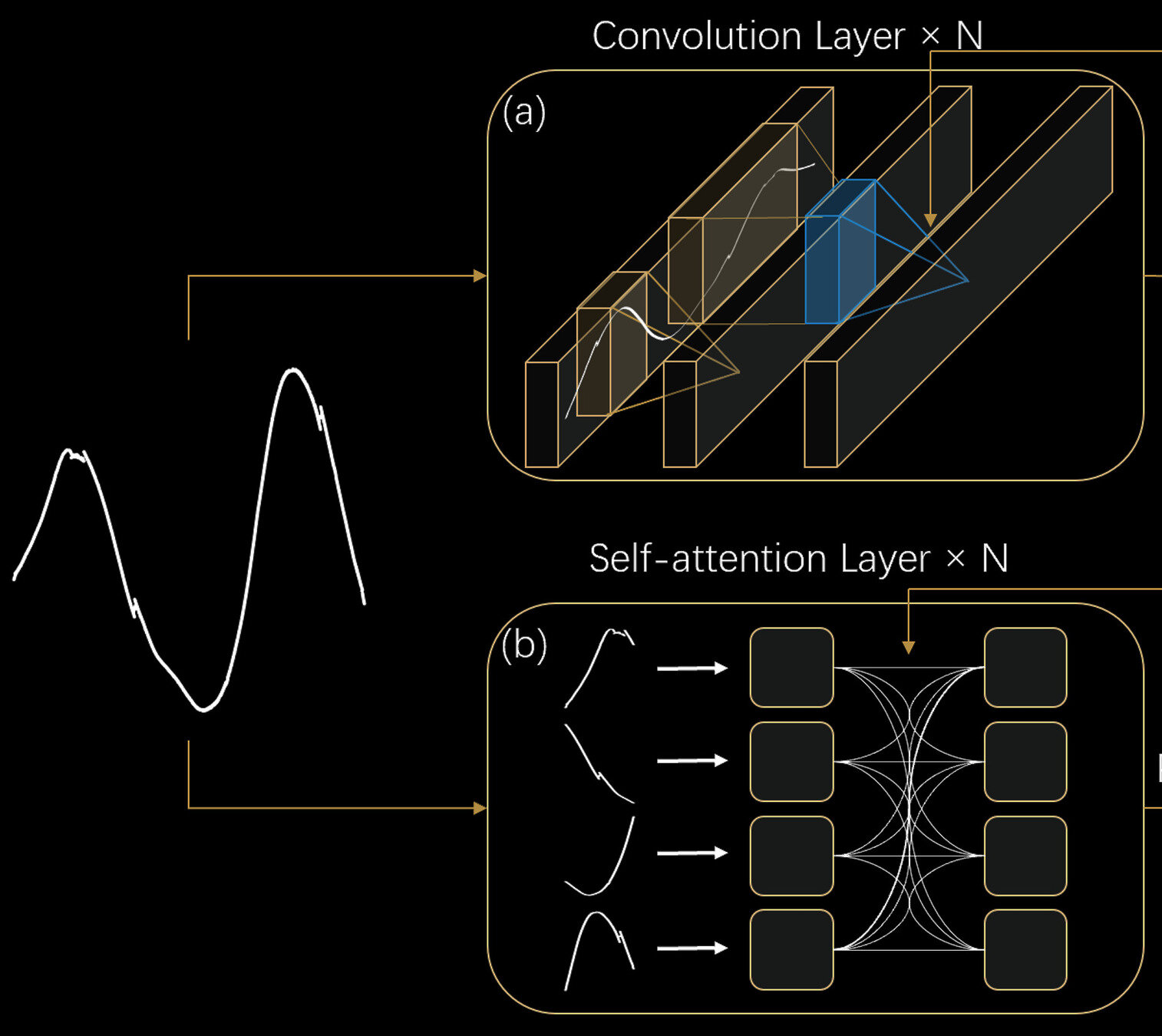
Convolutional Neural Networks
Local perceptive field
Transformer
Long-range information
The cat sat on the mat and licked its paws
Vezī zȳhon vaoreznon ūndessun daor, iderennon ītsos daor.

The foundation of Natural Language Processing: Transformer
Spectra also contain long-range information
Transformers result in improved spectral emulations
4500
4600
4700
4800
4900
5000
Wavelength [A]
Generative Residual [dex]
-0.02
0
0.02
0
-0.1
0.1
-0.02
0
0.02
TransformerPayne (< 0.1%)
Convolutional Neural Networks
Multi-Layer Perceptron
("The Payne", 1% error)
Rozanski, YST+ 2024
(~ 10%)
YST, ARAA, 2026
https://tingyuansen.github.io/NASA_AI_ML_STIG/
https://tingyuansen.github.io/NASA_AI_ML_STIG/
Open-AI, 2023
Predicting and extrapolating the Transformer performance
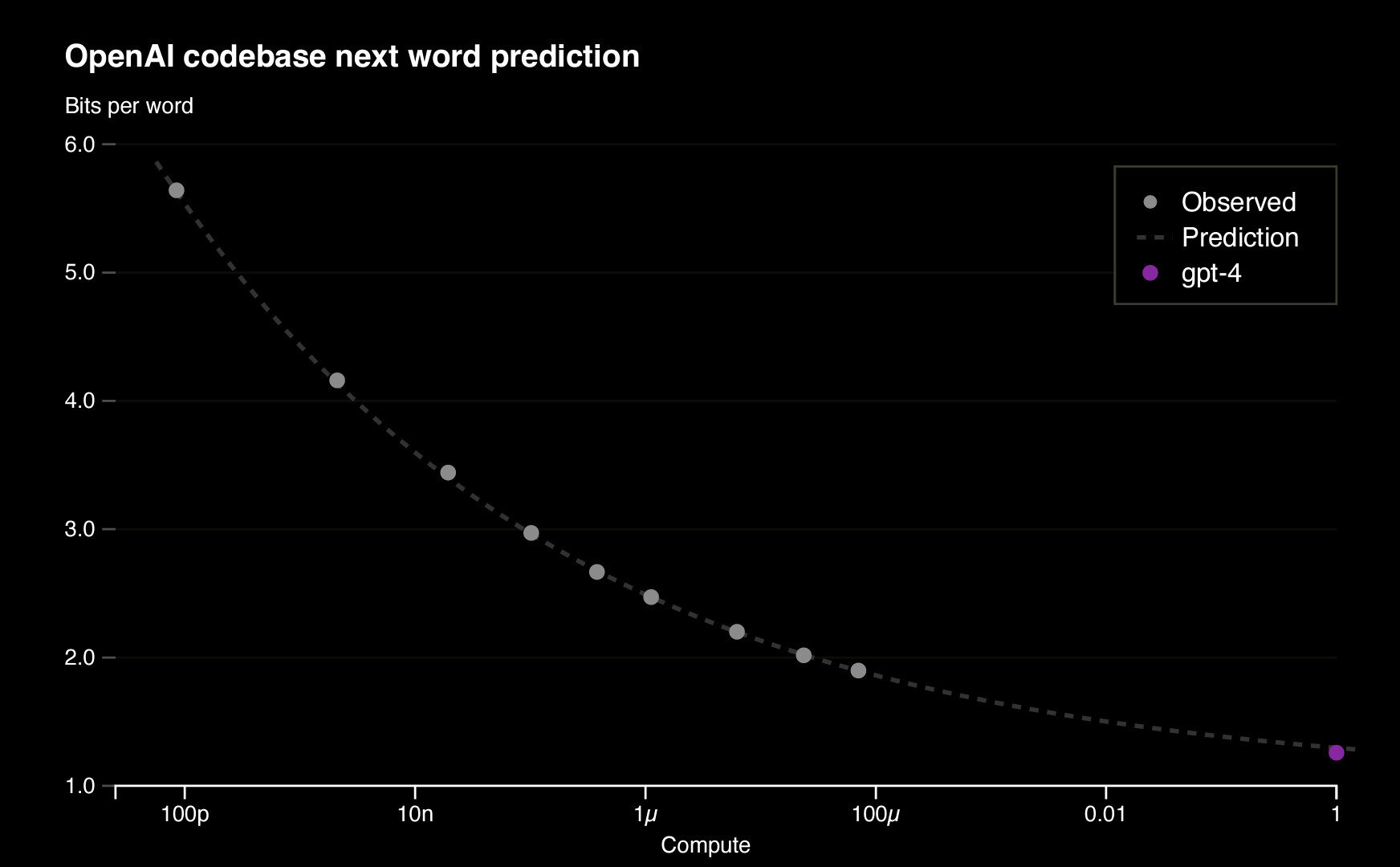
"Model Size "
Performance
"Neural scaling law"
TransformerPayne also exhibits the neural scaling law
The more computing power we can allocate, the more the models will continue to improve
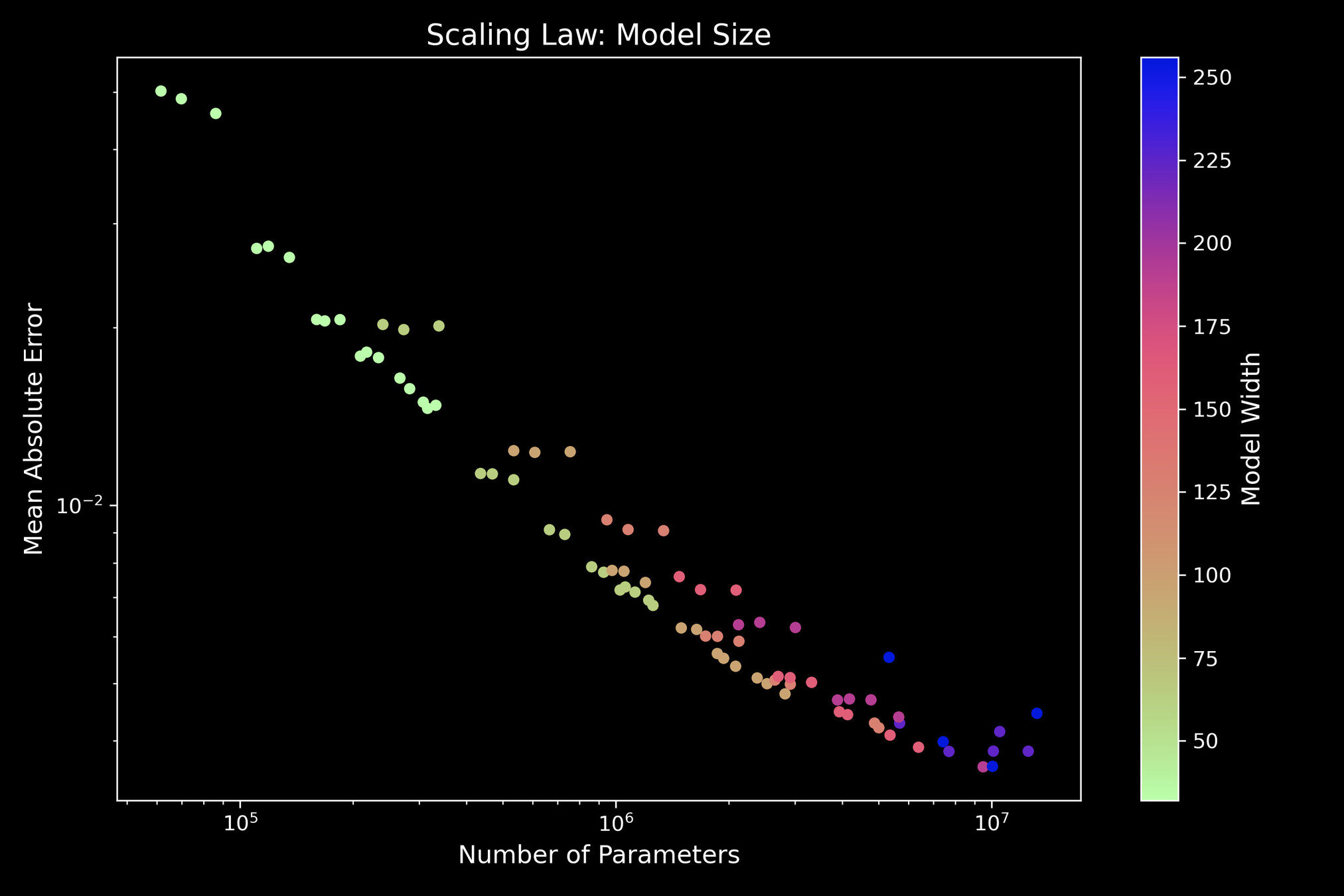
Number of parameters
Emulation Error, MAE
1%
10M
1M
100K
Model Width
Rozanski & YST, 2025
Error budget
In the "old" Payne
Photon noise
Model
Systematics
Emulator
systematics
Error budget
With Transformers
Photon noise
Model
Systematics
Emulator
systematics
Can in principle be arbitrarily small
Note: larger models, especially Transformers, can be slow
To Enable Full-Spectral Fitting
An effective high-dimensional emulator ("interpolator"), mapping from ~20D (number of labels) to O(1000)D (number of pixels)
Overcoming systematics due to imperfect models
- or the synthetic-observation gap
Synthetic spectral models are imperfect
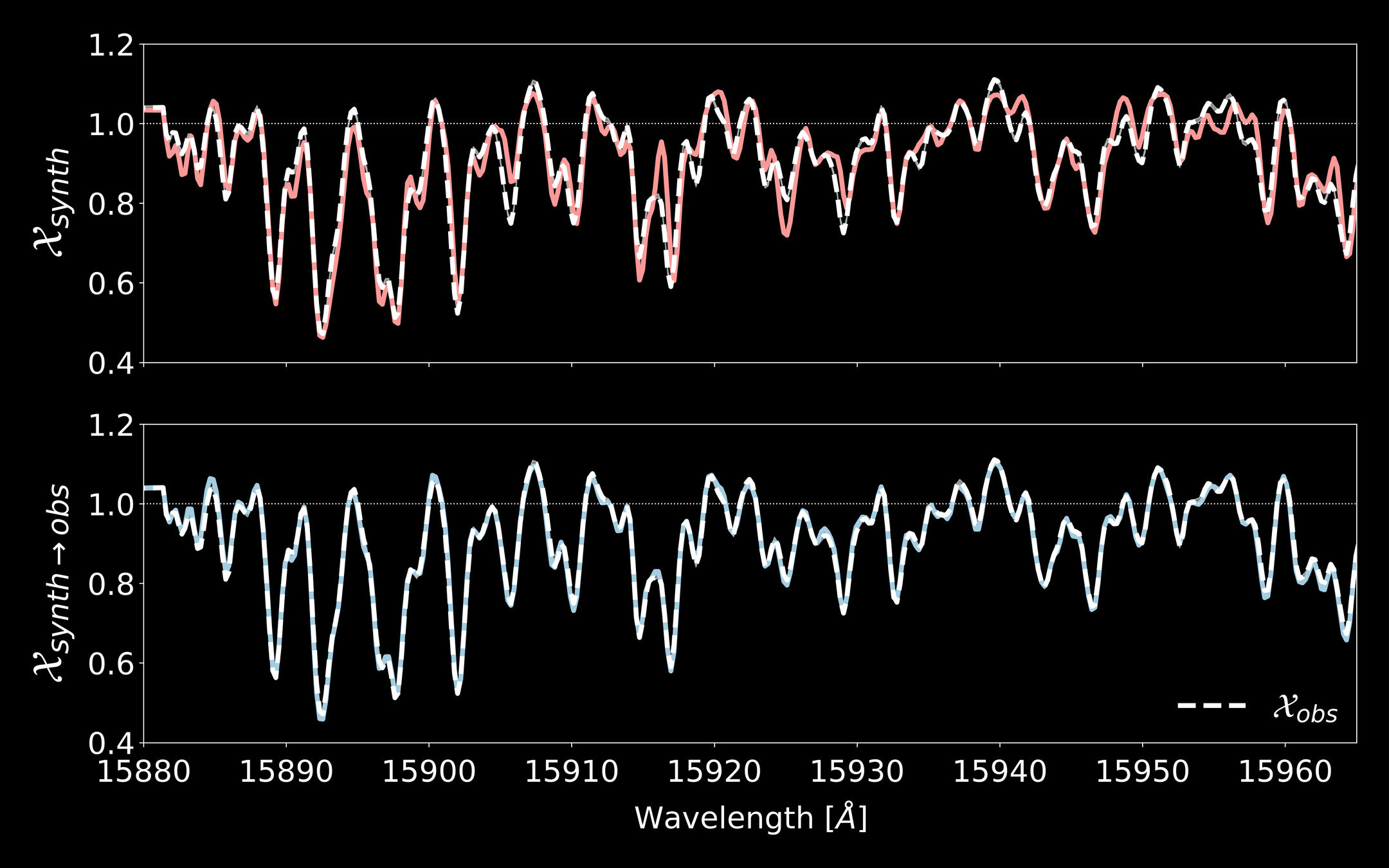
0.5
15900
15940
Best-fit model
Normalized Spectrum
Observation
Wavelength [A]
APOGEE M-Dwarfs
15920
15960
15880
1.0
Data-Driven Models ?
The danger of inferring abundances from data-driven models
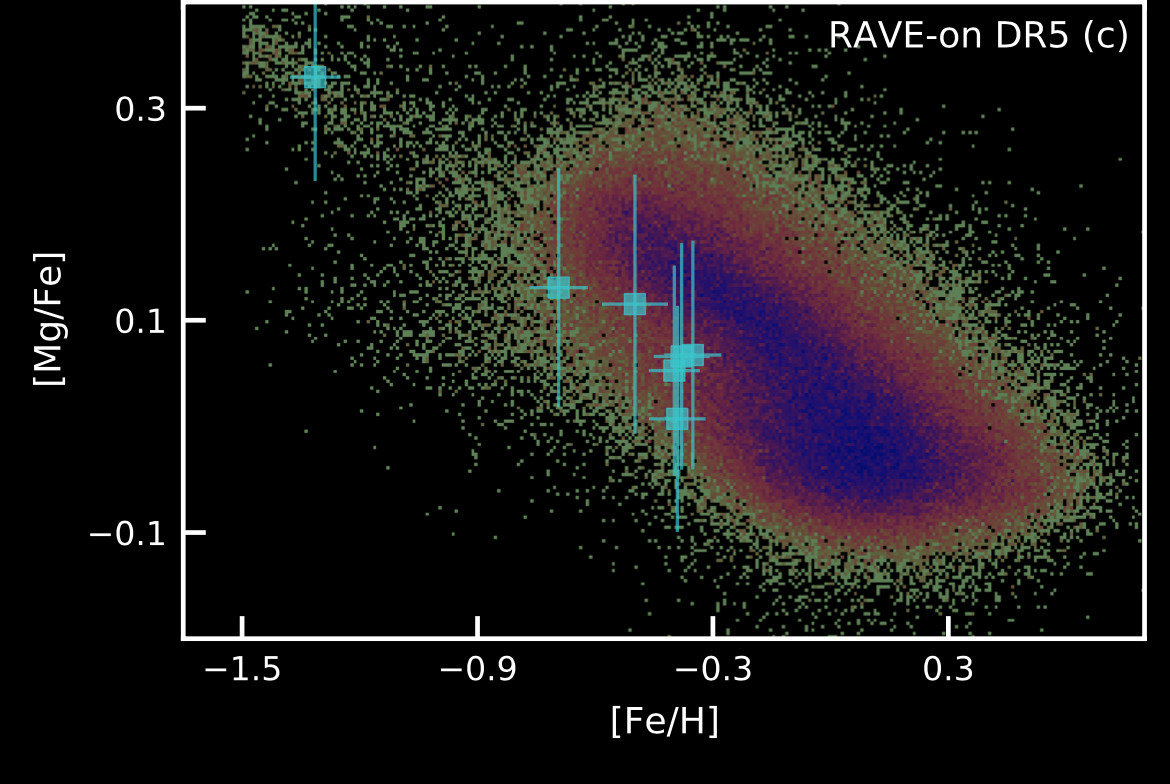
RAVE-on, "data-driven" abundances
Nyx (accreted dwarf system ??)
Zucker,..,YST+ 21
[Fe/H]
[Mg/Fe]
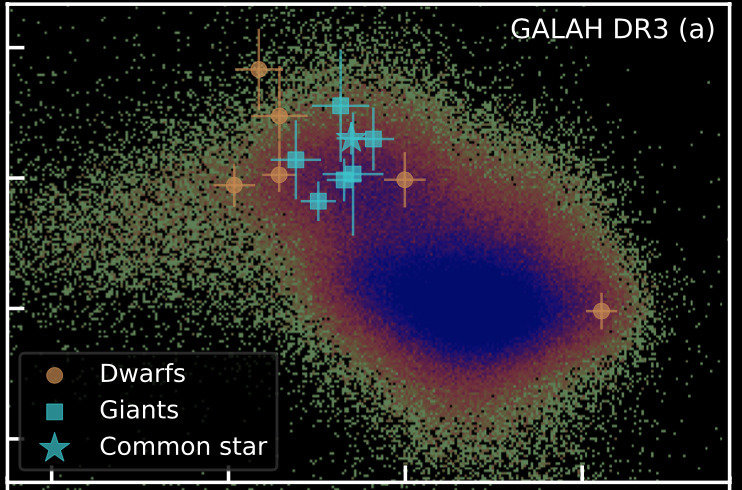
Galah high-res "ab initio" measurements
Not so fast!
-1.5
-1.5
-0.9
-0.3
0.3
-1.5
-0.9
-0.3
0.3
[Fe/H]
Correlation is not causality
[Fe/H]
[Mg/Fe]
log g
spectrum
Correlation is not causality
[Fe/H]
[Mg/Fe]
log g
spectrum
distance
Selection
function
Chemical evolution
Measurement?
Correlation is not causality
[Fe/H]
[Mg/Fe]
log g
spectrum
distance
Selection
function
Chemical evolution
or indirect inference?
Inferring Eu (from correlation) is simple, but measuring Eu is hard

True "response function", Kurucz models
Wavelength [A]
4000
5000
6000
7000
8000
Effective Temperature
4400
4600
4800
5000
Wavelength [A]
4000
5000
6000
7000
8000
Color code : the "gradient" spectrum
Data-driven
Inferring Eu from other elements, not measuring Eu
Interim Solution ("Physics-Inspired" Neural Networks):
Data-Driven Model + Model Gradient Regularization
= DD-Payne
YST+ 2017
Forcing the gradient to be
aligned with the expected "line list"
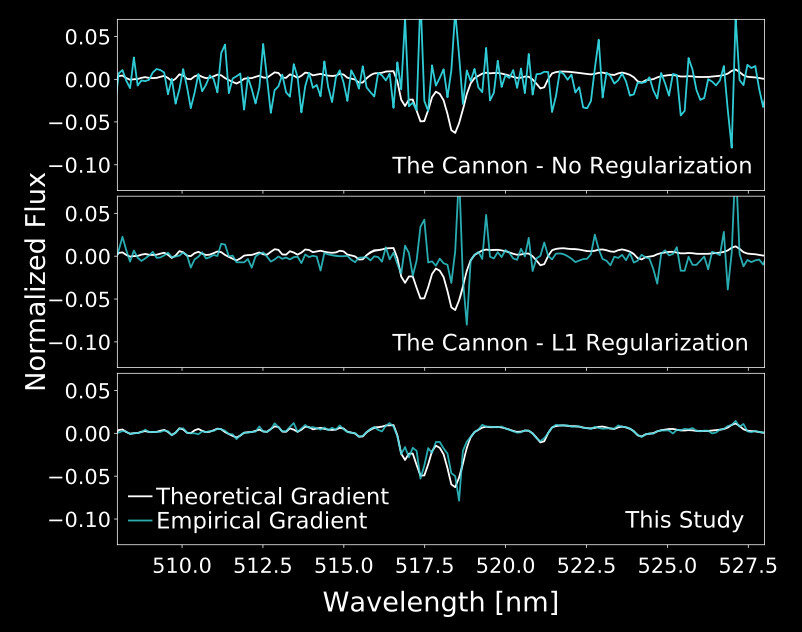
Measuring magnesium from the magnesium lines

Synthetic spectra
Observed spectra

Xiang, YST, Rix+ 2019

Zhang, Xiang, YST+ 2024
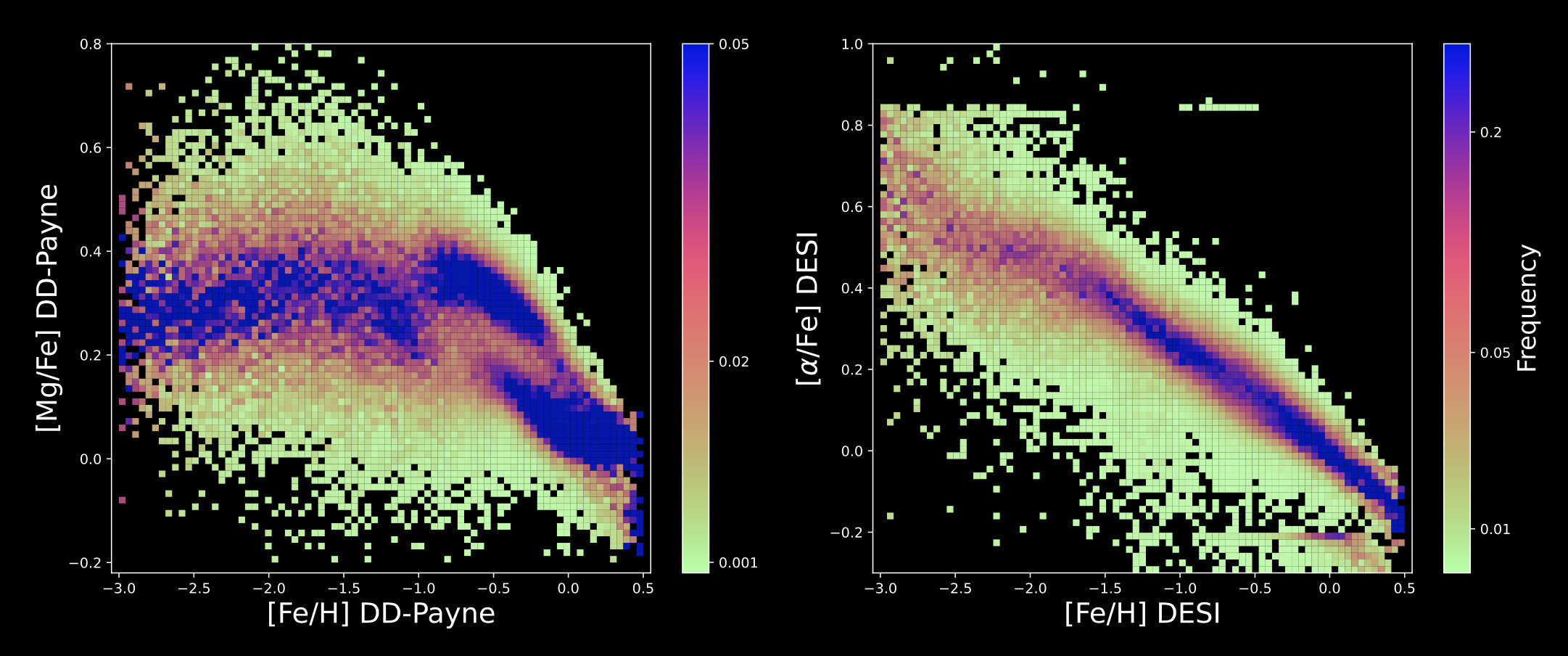
Extracting Information from Low-Resolution DESI Spectra
This Study
DESI Data Release
[Fe/H]
-3
-2
-1
0
-3
-2
-1
0
-3
-2
-1
0
-0.2
0.0
0.2
0.4
0.6
0.8
[Mg/Fe]
[Mg/Fe]
Thick Disk
Thin Disk
GSE
-0.2
0.0
0.2
0.4
0.6
0.8
[Mg/Fe]
Zhang, Xiang, YST+ 2024
[Fe/H]
[X/Fe]
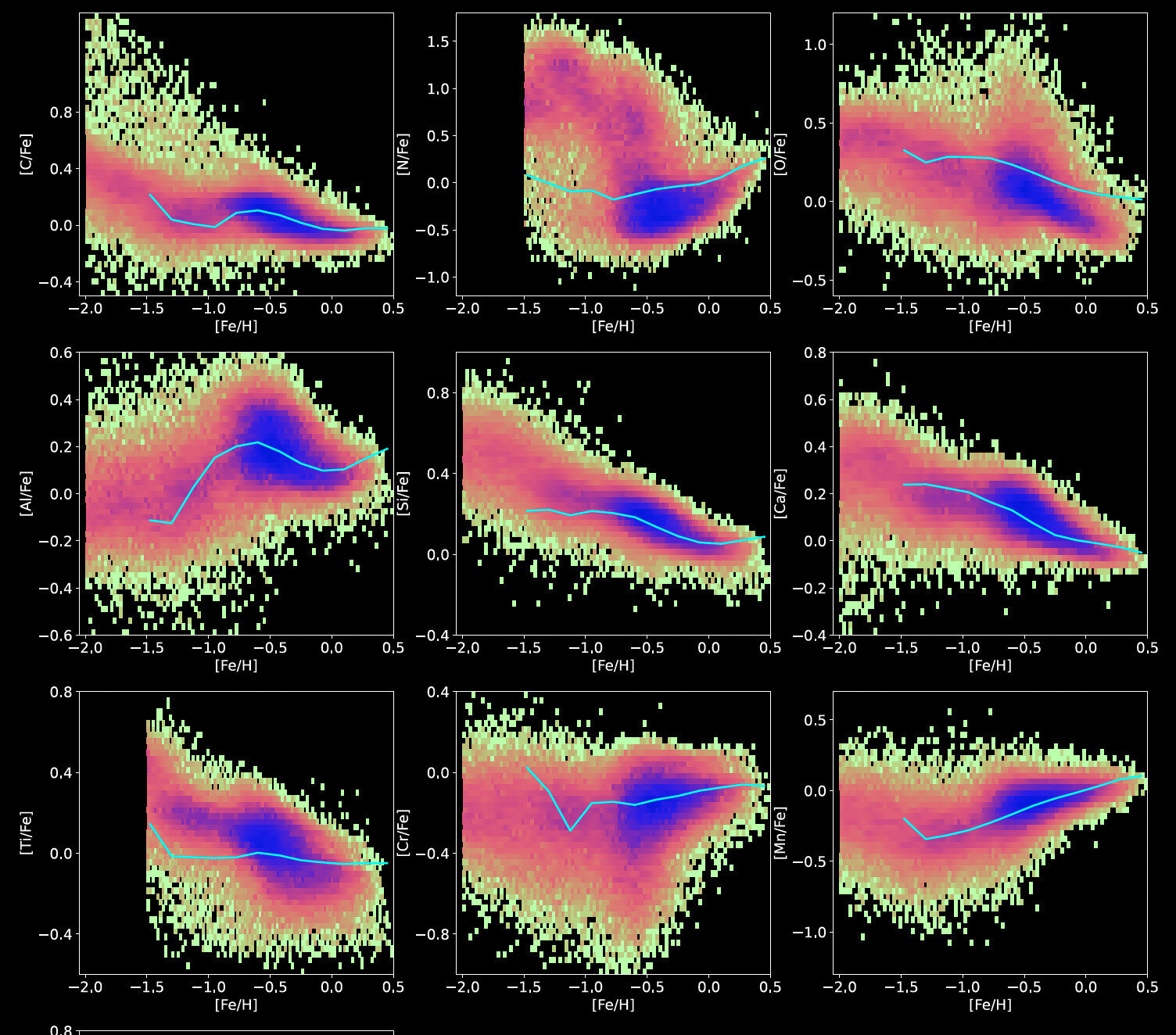
Ti
Cr
Mn
Al
Si
Ca
O
Ni
C
Extracting Information from Low-Resolution DESI Spectra
Chemical evolution model
Zhang, Xiang, YST+ 2024
Foundation models:
Effective domain transfer between surveys with massive pretraining

https://pair.withgoogle.com/explorables/grokking/
https://pair.withgoogle.com/explorables/grokking/
https://pair.withgoogle.com/explorables/grokking/
Neural Network Weights
Not every big deep learning model is a foundation model
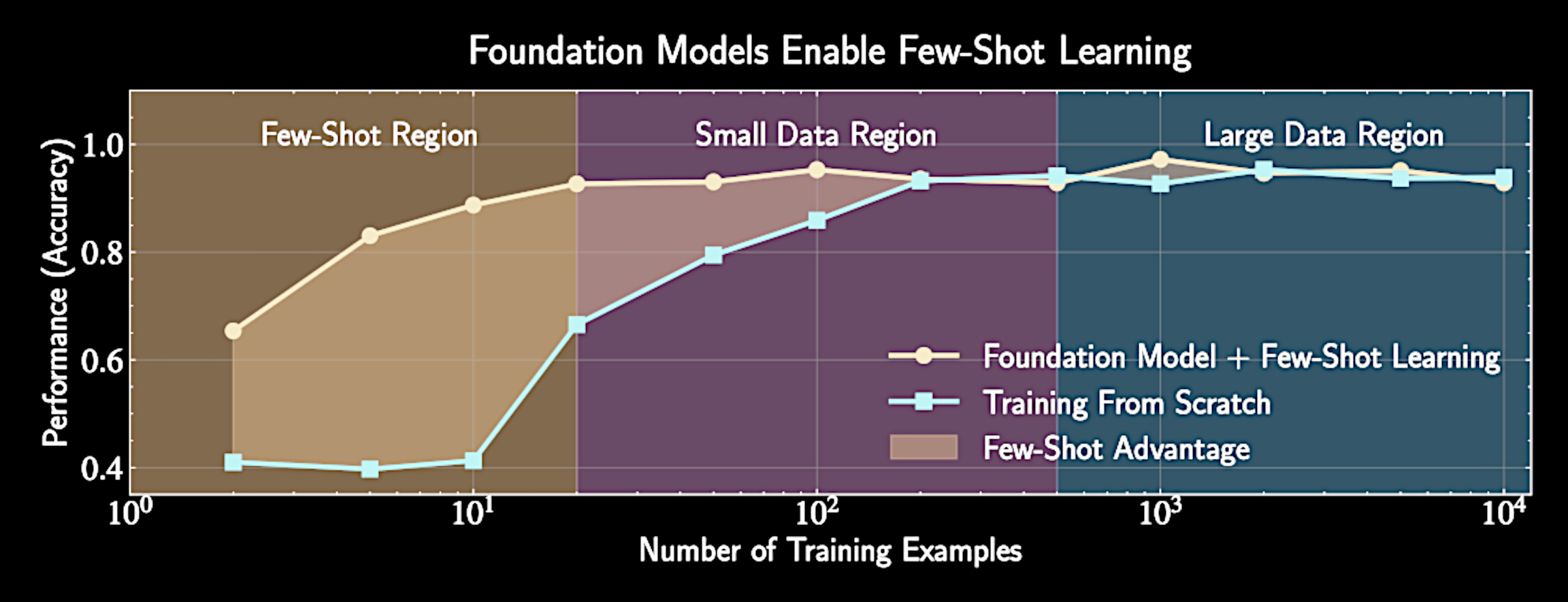
YST, ARAA, 2026
Few-shot
learning
is the key
Freezing most parameters, tuning a small number of neurons
Zhao, YST+, 2025
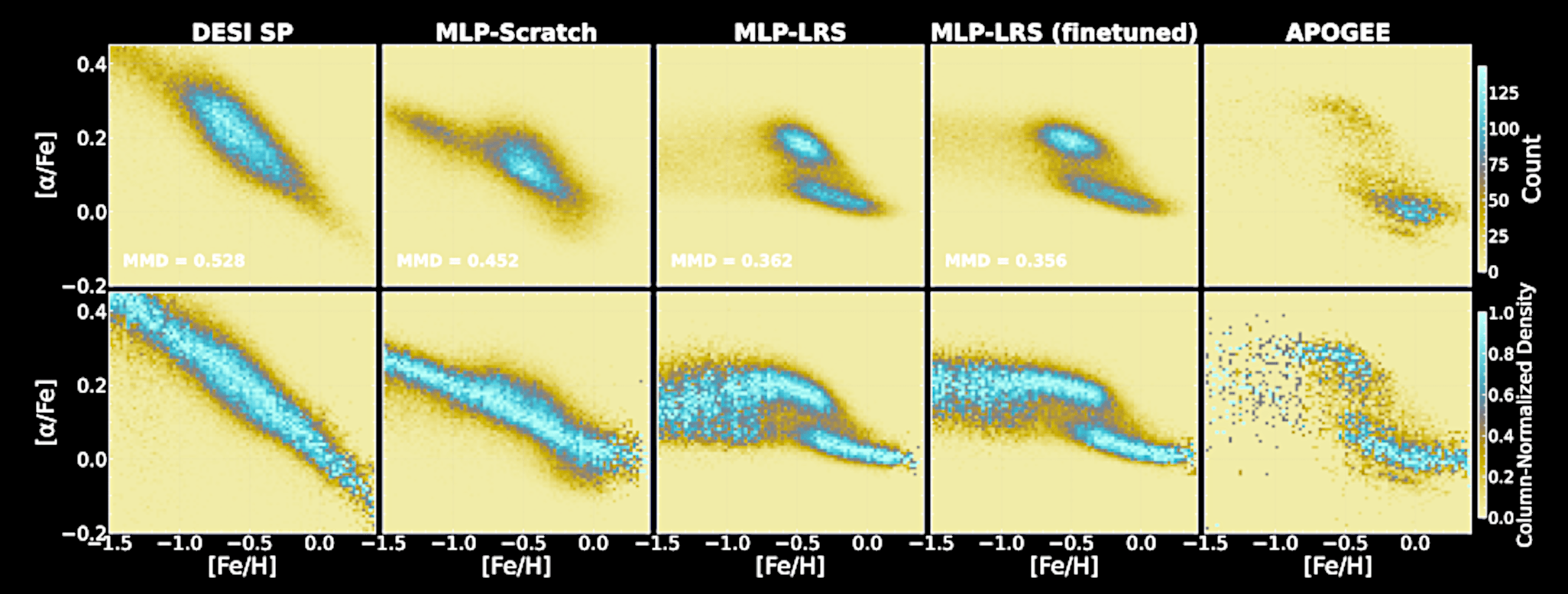
Recovering the DESI thin/thick disk with an O(100) training set
Zhao, YST+, 2025
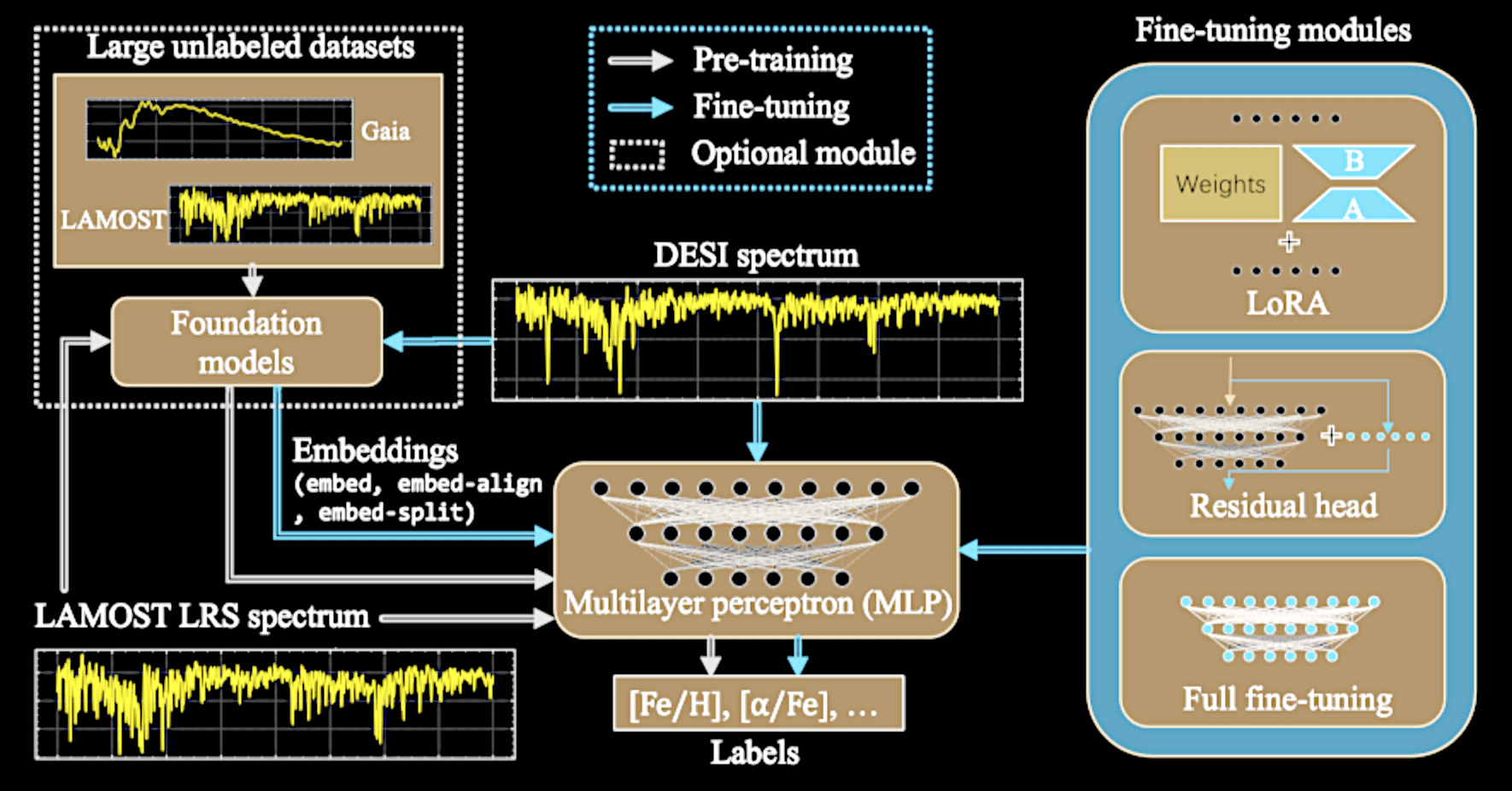
Pre-training with LAMOST
DESI Pipeline
APOGEE (target)
NN from scratch
NN from LAMOST
+ fine tune
Note :
Transformer models Foundation models
Foundation models Transformer models
To Enable Full-Spectral Fitting
An effective high-dimensional emulators ("interpolator"), mapping from ~20D (number of labels) to O(1000)D (number of pixels)
Overcoming systematics due to imperfect models
- or the synthetic-observation gap
Using data-driven models is cheating!

Abundance
pipeline
Stellar labels
Moving beyond stopgaps -
developing better calibrated models
Synthetic spectra
Observed spectra
Calibrating spectral models is God's work
God is amused by coding agents
Time horizon with 50% success rate: >10 hours as of December
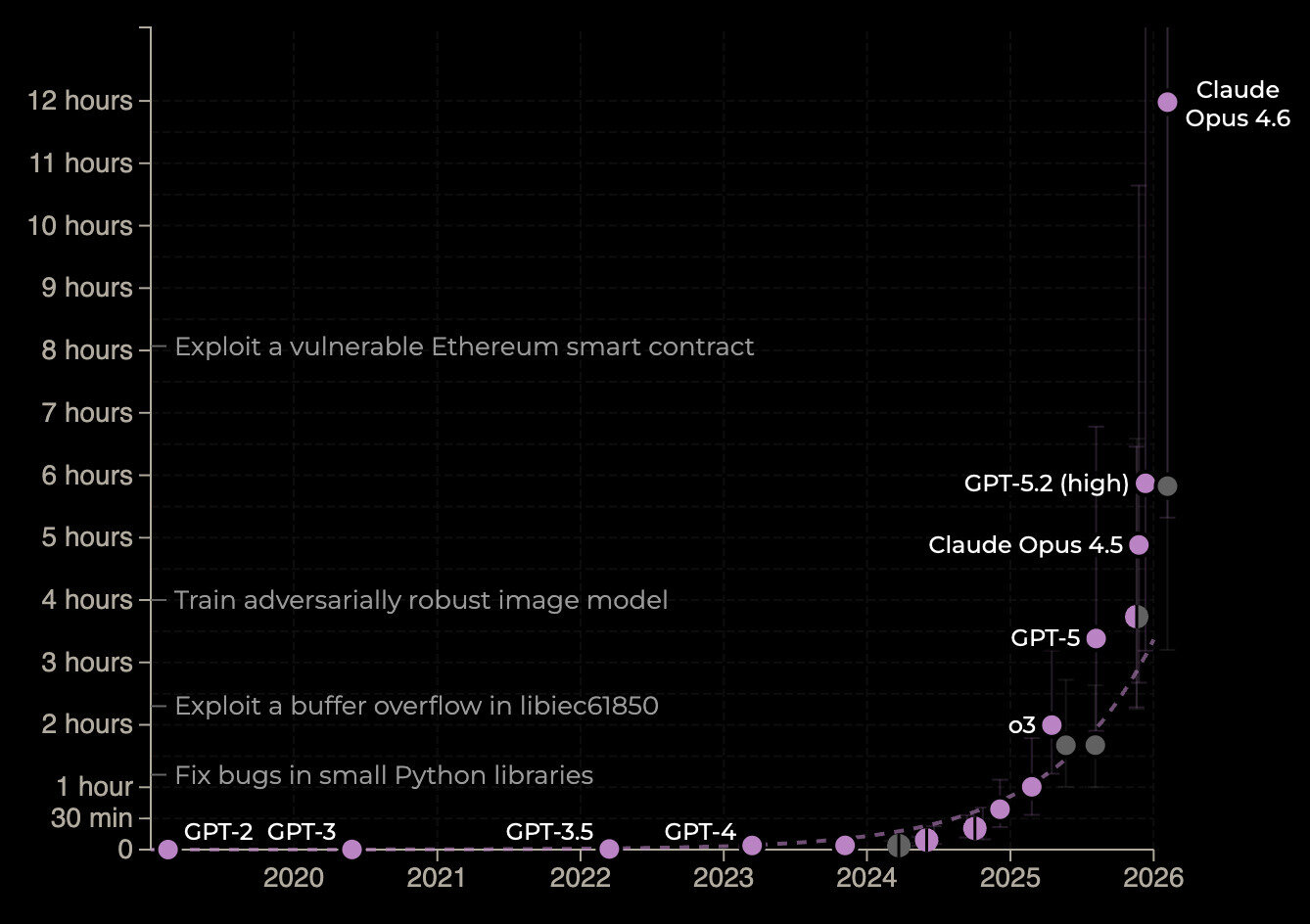
METR.com
Kim & YST, 2026

Dedicated to the memory of Robert L. Kurucz
(1944–2025)
Rewriting Kurucz codes entirely in Python

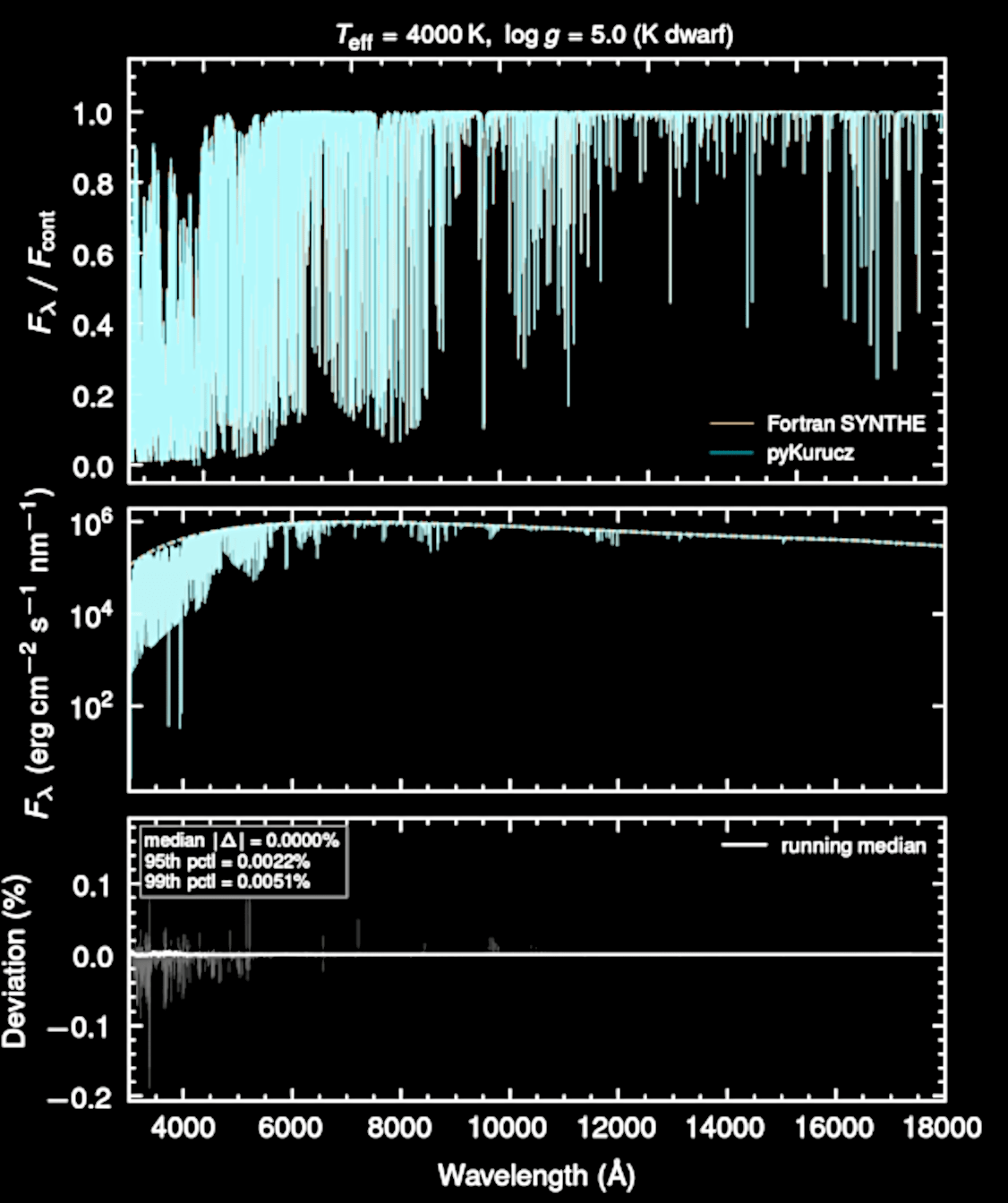
An excellent replica!
Fortran vs Python

github.com/tingyuanse/kurucz
Why does ASPCAP still give arguably the most reliable results?
Full-Spectral Fitting
Line-by-line
equivalent width
Star a =
Star b =
Individual bad lines can dominate the systematics

The boutique line-by-line equivalent width differential analysis
e.g., Liu, YST, Yong+, Nature, 2024
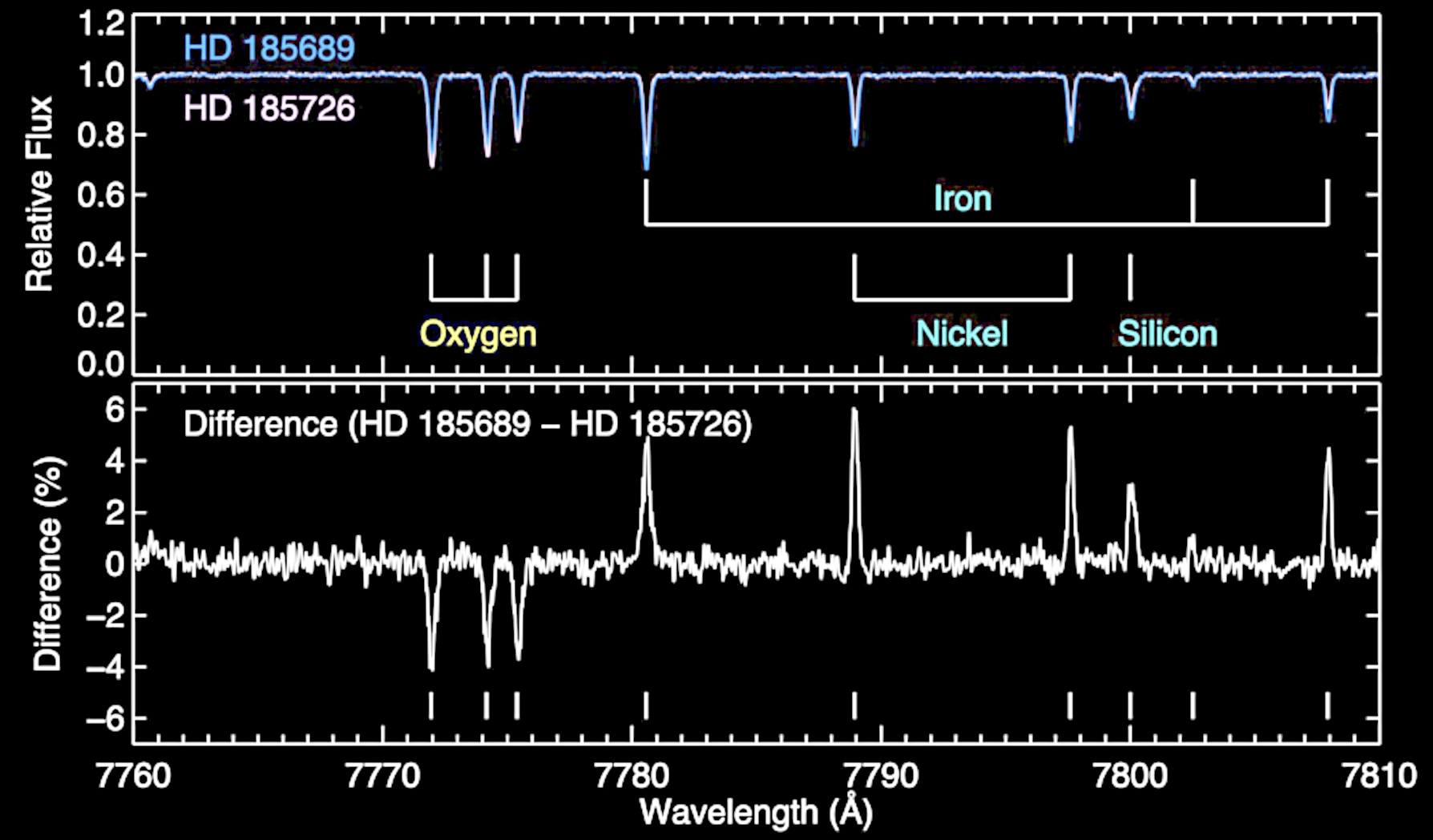

precision ~ 0.01 dex
Full-Spectral Fitting
Line-by-line
equivalent width
Star a =
Star b =
Individual bad lines can dominate the systematics
Canceling out line-by-line systematics
Full-Spectral Fitting
Line-by-line
equivalent width
Individual bad lines can dominate the systematics
Not enough graduate students...
ASPCAP
Is this true?
A more drastic approach:
differential line-by-line analysis for millions of stars in AS5?
AI agents (LLM models)


AI agents (LLM models)

Proposing actions
Execute actions
State evolution
Knowledge distillation

YST+, 2025
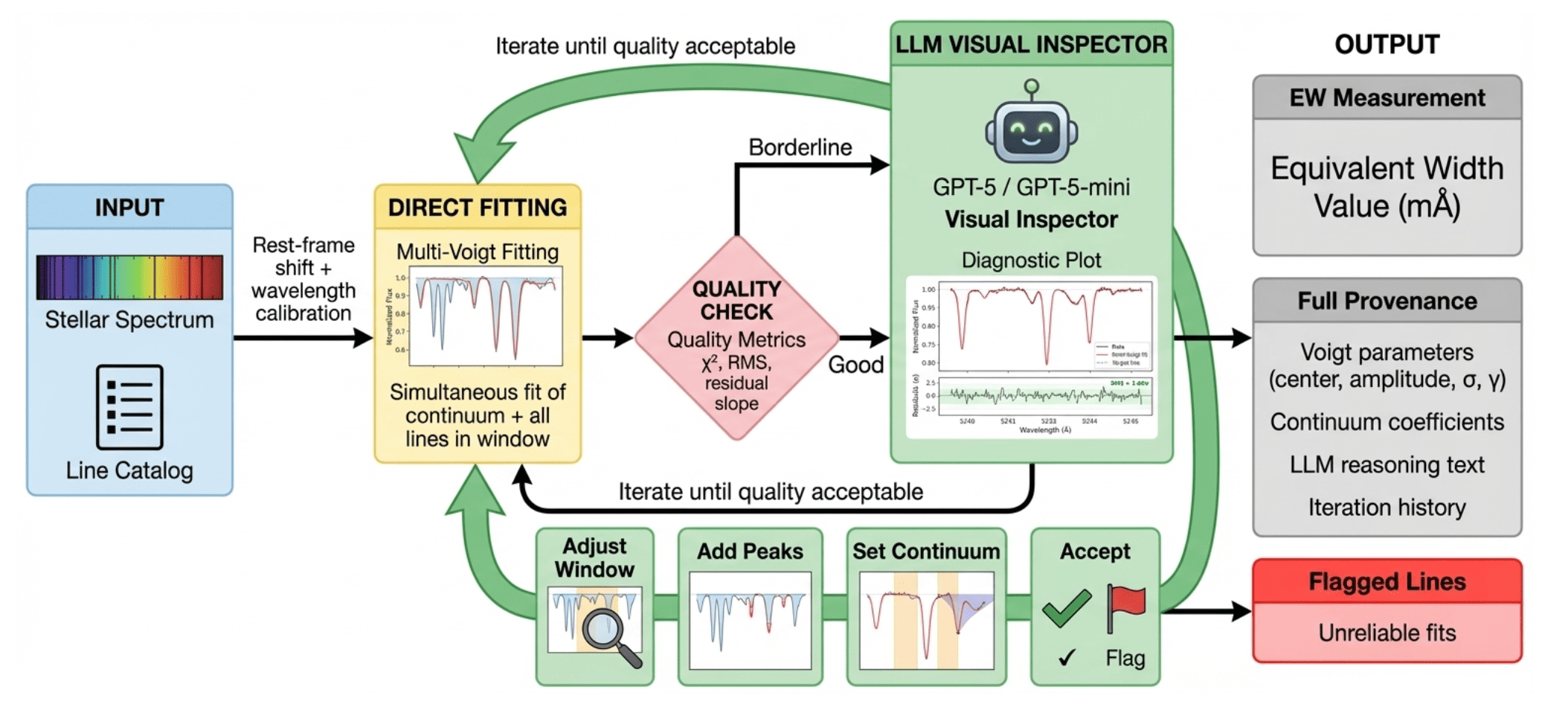
Fitting equivalent widths used to require human judgments
YST+, 2025
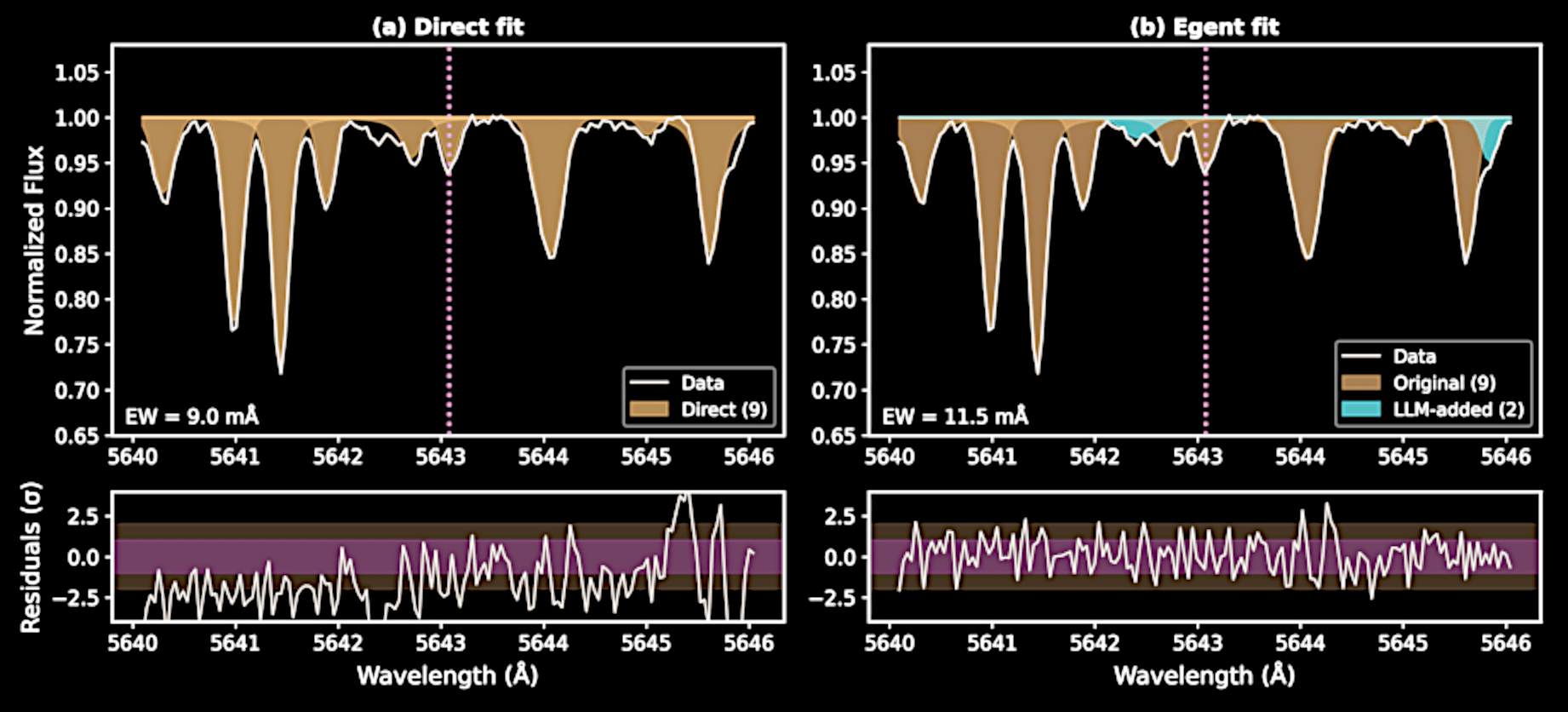
E.g., deciding whether there's an unresolved blend of lines
YST+, 2025
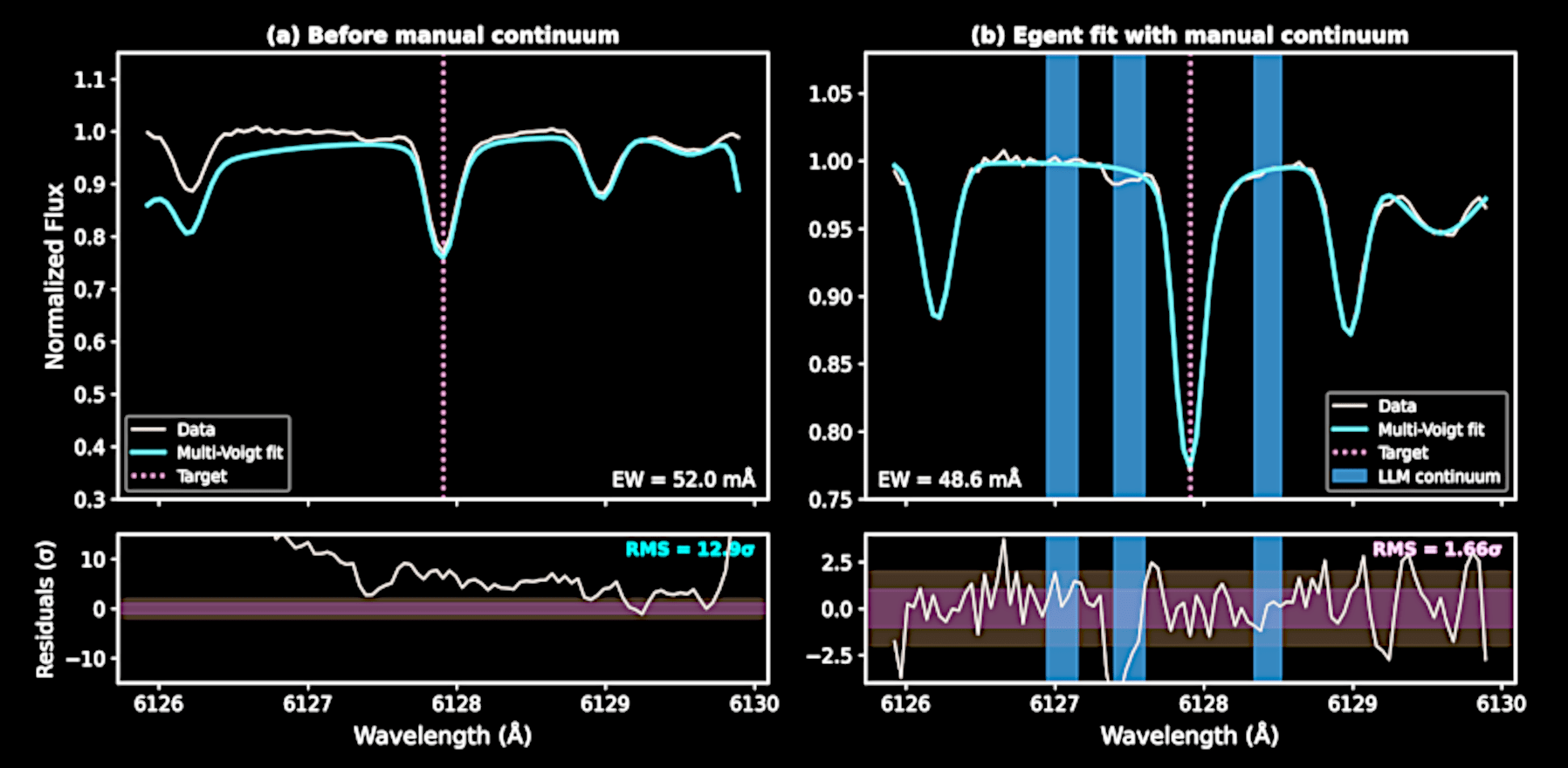
E.g., adjusting for the continuum
YST+, 2025
Also a web interface for Egent
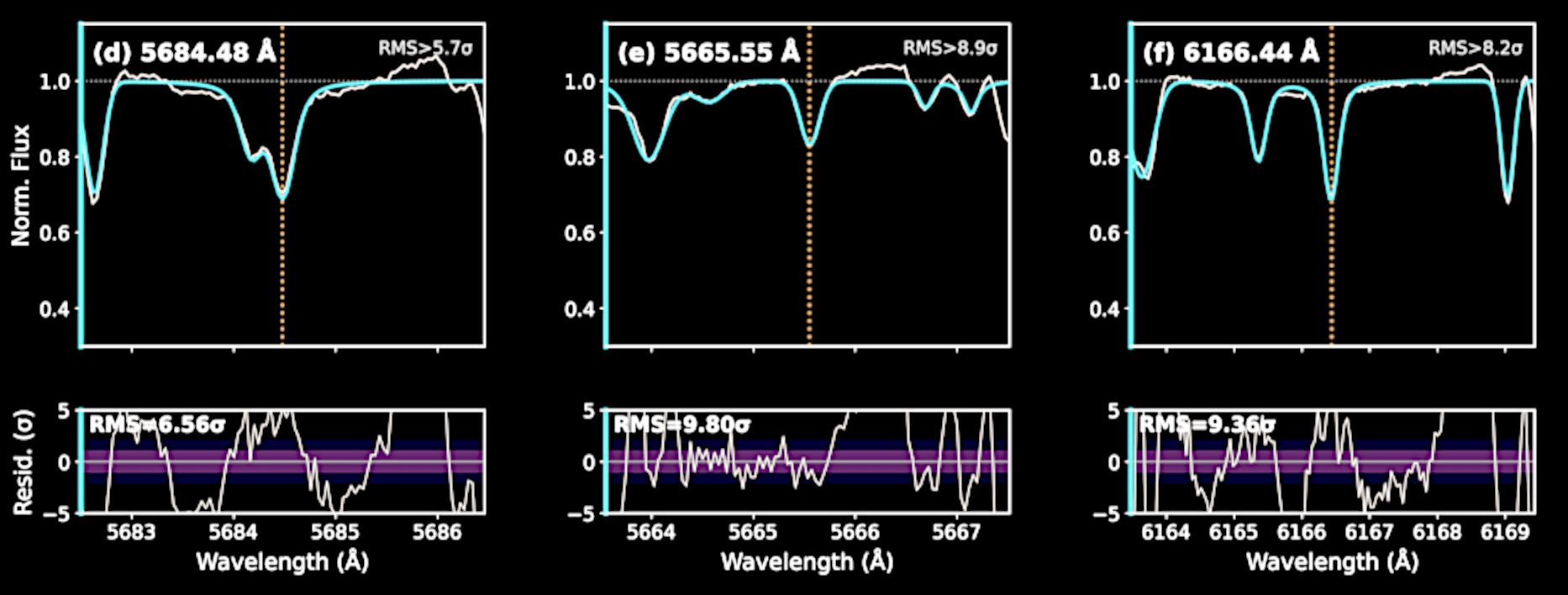
Flagging bad fits automatically, despite Egent's best efforts
What took an expert a year now costs only $100 + a few hours
Liu, YST, Yong+, Nature, 2024
precision ~ 0.01 dex
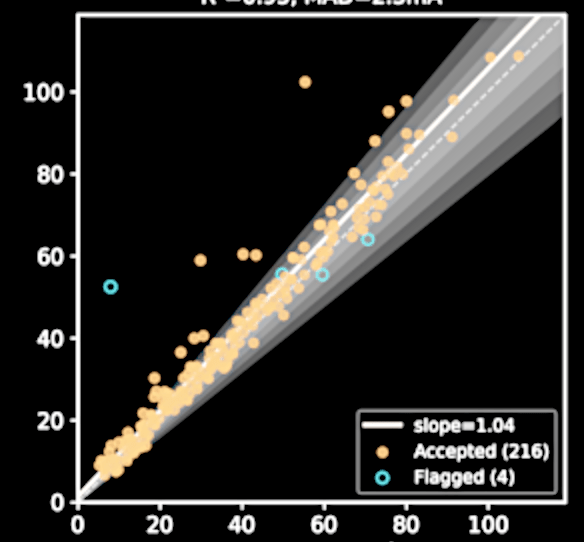
One of
the 250 stars
David Yong's right hand
Equivalent width
Egent with GPT-5-mini