Docker
Computers perform repetitive tasks; People solve problems.
Accelerate, Forsgren PhD.
Master Expert Technologie de l'information EPITECH 2020.
Co-fondateur et CTO d'une startup dans l'Edtech 2019 - fin 2022. (+3 ans)
Formation PSPO-1 Agile Scrum 2022.
Co-fondateur et CTO d'une startup dans la Deeptech fin 2022 - aujourd'hui.
Valentin MONTAGNE

Connaissez-vous Docker ?
1
Les enjeux de la conteneurisation
3
Docker Compose
Composition multi-service et cas d'usages.
5
Stratégies DevOps et CI/CD
Mise en place d'un env' de test et de déploiement.
2
Docker
Création, gestion et déploiement des images et manipulation des volumes et des networks.
4
Kubernetes / Swarm
Cluster multi-nœuds, cas d'usages dans le Cloud. (AWS, Google Cloud, Azure)
Déroulement du cours
Chaque séance débutera par la présentation d'un concept et de l'intérêt d'utilisation de celui-ci.
1
Théorie
Après la théorie, nous verrons alors la pratique en réalisant des exercices sur un repository gitlab.
2
Pratique
En fin de chaque séance, nous aurons un temps pour poser des questions sur le projet à rendre en fin de module.
3
Préparation
Déroulement des journées
Les enjeux de la conteneurisation
1.
Les conteneurs sont des environnements logiciels légers, portables et isolés qui permettent aux développeurs d'exécuter et d'empaqueter des applications avec leurs dépendances, de manière cohérente sur différentes plateformes. Ils contribuent à rationaliser les processus de développement, de déploiement et de gestion des applications, tout en garantissant que les applications fonctionnent de manière cohérente, quelle que soit l'infrastructure sous-jacente.
– Conrad Anker
Définition
- Efficiency
- Portability
- Fast startup
- Consistency
Containers
VMs or Bare Metal
- Inconsistent environments
- Inefficient resource utilization
- Slow processes and scalability issues
– Conrad Anker
Pourquoi les utiliser ?

CI / CD

Hypothesis driven & Lean

Cloud as a service

– Conrad Anker
Hypothesis Driven & Lean
Lean UX
Google Design Sprint
Course à l'itération
Accelerate!
– Conrad Anker
Scientifiquement prouvé
Corrélation entre les performances et le bien-être au travail avec le CI / CD et le Lean
Computers perform repetitive tasks; People solve problems.
Key Indicators
- Delivery lead time
- Deployment frequency
- Time to restore service
- Change fail rate
– Conrad Anker
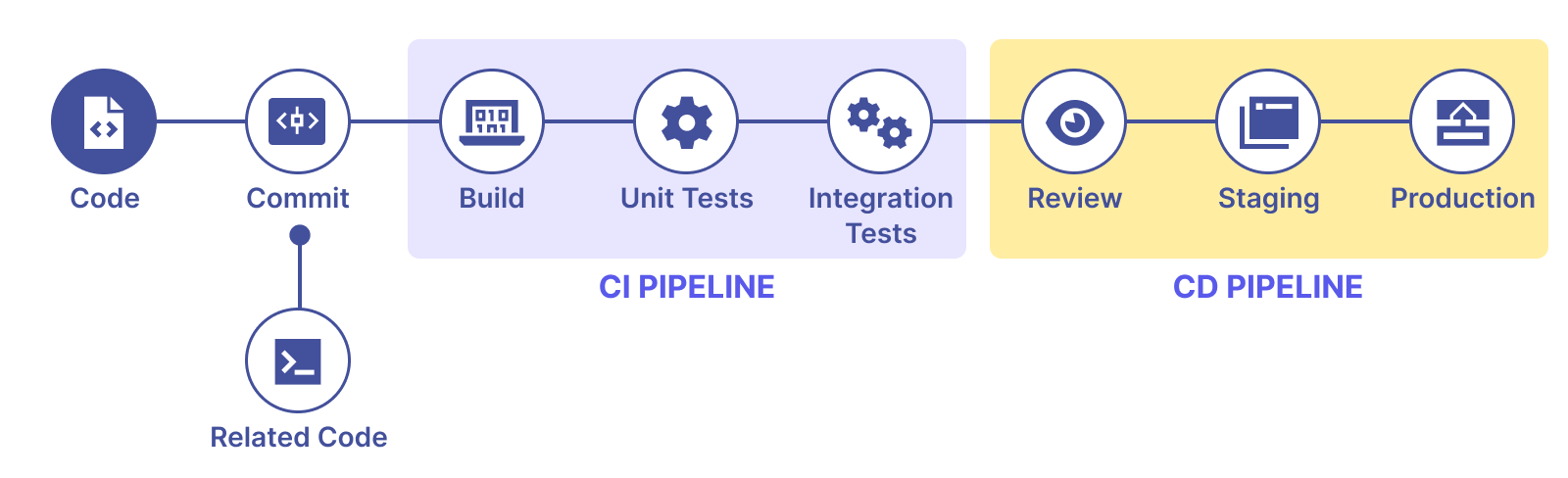
CI / CD
Build
Unit and Integration Tests
Review & Staging
Gitlab and Github Actions
– Conrad Anker
Le Workflow en CI / CD
– Conrad Anker
DORA - DevOps Status
– Conrad Anker
Cloud as a service
AWS, Google Cloud, Azure, Heroku, Vercel...
Externaliser son infrastructure
Automatiser et monitorer le déploiement des applications
Infrastructure as code (IaC)
Terraform
- Automatisé et simple
- Internationalisation
- Scalable
- Startup friendly
Cloud
- Moins cher
- Autonomie
- Plus de performance
Self-host
VS
- Coût "caché" / cher
- Complexe
- Formation à prévoir
- Coût des équipes
- Expertise forte requise
Des questions ?
Docker
2.
Docker est une plateforme open-source qui automatise le déploiement, la mise à l'échelle et la gestion des applications en les isolant dans des conteneurs légers et portables.
– Conrad Anker
Définition
– Conrad Anker
Docker et OCI
L'Open Container Initiative (OCI) est un projet de la foundation Linux.
Son objectif principal est de garantir la compatibilité et l'interopérabilité des environnements de conteneurs par le biais de spécifications techniques définies.
– Conrad Anker
Installation
Une application Desktop est disponible sur le site internet.
docker --version
Pour vérifier que Docker est installé :
– Conrad Anker
Les différents éléments

Image

Dockerfile
Container

# Download an image from a registry, like Docker Hub.
docker pull <image>
# Build an image from a Dockerfile, where <path> is the directory containing the Dockerfile.
docker build -t <image_name> <path>
# List all images available on your local machine.
docker image ls
# Remove an image from your local machine.
docker image rm <image>
# Run a container from an image, mapping host ports to container ports.
docker run -d -p <host_port>:<container_port> --name <container_name> <image>
# List all running containers.
docker container ls
# Stop a running container.
docker container stop <container>
# Remove a stopped container.
docker container rm <container>– Conrad Anker
Persistance des données
Docker Volumes
docker volume create volume_name
docker run --volume volume_name:/container/path image_name
docker run --mount type=bind,src=/host/path,dst=/container/path image_name
docker run --tmpfs /container/path image_nameBind Mounts
Docker tmpfs mounts
– Conrad Anker
Volume Mounts
Permettre à la donnée de persister en dehors du container.
# Creating a Volume
docker volume create my-volume
docker volume inspect my-volume
# Mounting a Volume in a Container
docker run -d -v my-volume:/data your-image
docker run -d --mount source=my-volume,destination=/data your-image
# Sharing Volumes Between Containers
docker run -d -v my-volume:/data1 image1
docker run -d -v my-volume:/data2 image2
# Removing a Volume
docker volume rm my-volume– Conrad Anker
Bind Mounts
Permet d'utiliser des données déjà présente sur la machine (Ex: traitement des logs).
Fonctionne avec le système de fichier déjà présent sur la machine.
Attention à la consistance de vos systèmes. (Windows, Linux, MacOs...)
– Conrad Anker
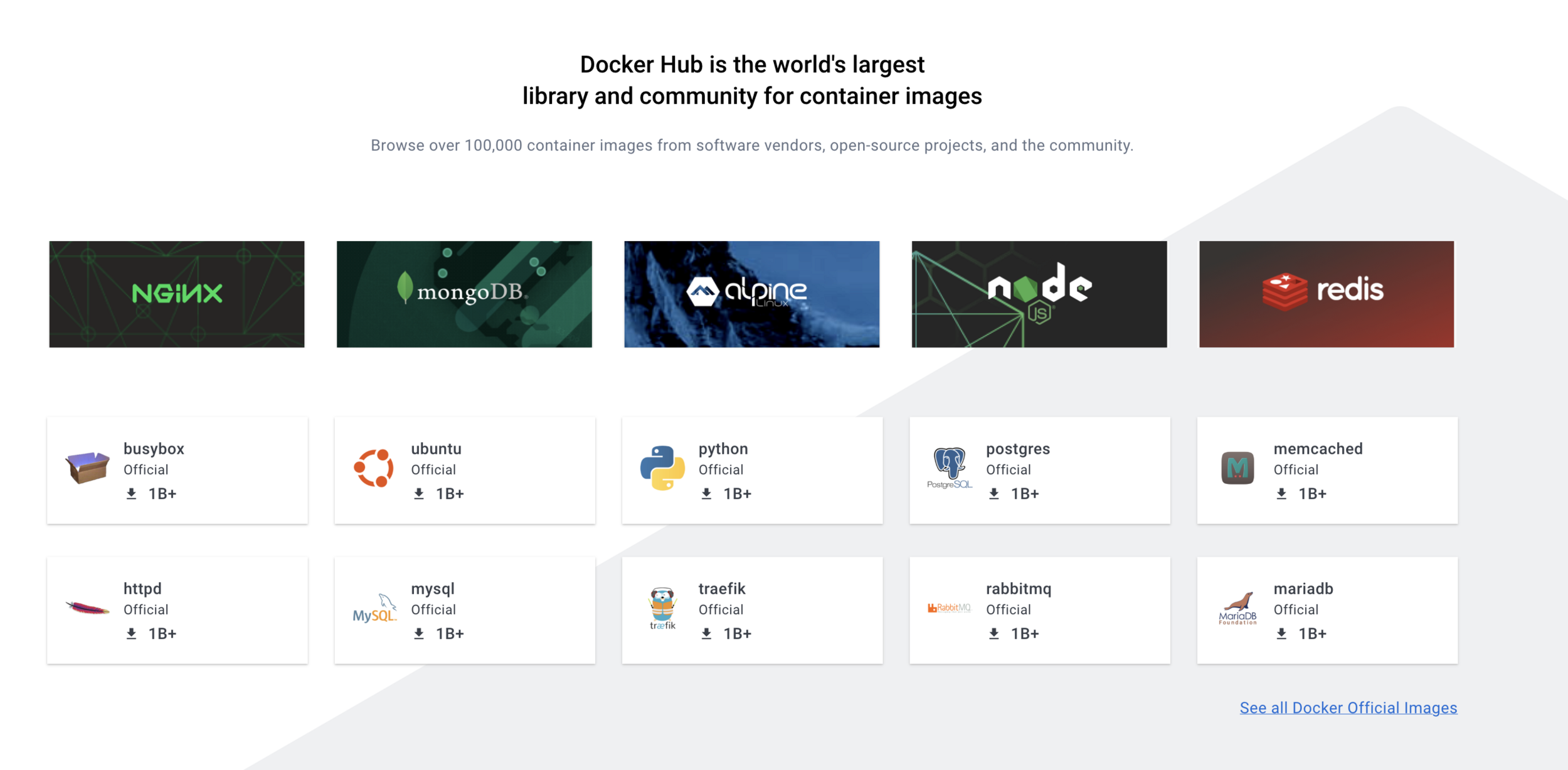
Using Third Party Images
– Conrad Anker
Using an Image in Dockerfile
FROM node:14
# Your Dockerfile's content...
Exemple utilisant l'image officielle de Node.js :
docker run -it --name <container_name> <image>– Conrad Anker
Les bases de données
Docker Hub fournit de nombreuses images préfabriquées pour les bases de données les plus courantes telles que MySQL, PostgreSQL et MongoDB.
# MySQL
docker search mysql
docker pull mysql
docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -p 3306:3306 -d mysql
# PostgresSQL
docker search postgres
docker pull postgres
docker run --name some-postgres -e POSTGRES_PASSWORD=my-secret-pw -p 5432:5432 -d postgres
# MongoDB
docker search mongo
docker pull mongo
docker run --name some-mongo -p 27017:27017 -d mongo
– Conrad Anker
Les environnements intéractifs
Docker vous permet de créer des environnements isolés et jetables qui peuvent être supprimés une fois les tests terminés.
# Here, -it flag ensures that you’re running the container in interactive mode with a tty,
# and --rm flag will remove the container once it is stopped.
docker run -it --rm python
# print("Hello, Docker!")
docker run -it --rm node
docker run -it --rm ruby
docker run -it --rm --name temp-mysql -e MYSQL_ALLOW_EMPTY_PASSWORD=yes -p 3306:3306 mysql
# This will start a temporary MySQL server. It will be removed once the container is stopped.– Conrad Anker
Créer une Image - Dockerfile
Essentiellement un script contenant des instructions sur la manière d'assembler une image Docker.
# Use an official Python runtime as a parent image
FROM python:3.7-slim
# Set the working directory to /app
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# Make port 80 available to the world outside this container
EXPOSE 80
# Define environment variable
ENV NAME World
# Run app.py when the container launches
CMD ["python", "app.py"]
# More Instructions === Bigger– Conrad Anker
Créer une Image - Building
docker build -t your-image-name .
# Inspecting Images and Layers
docker image ls
docker history your-image-name
docker inspect your-image-name
docker image rm your-image-name
# Pushing Images to a Registry
docker login
docker tag your-image-name username/repository:tag
docker push username/repository:tag
# We will see more later ;) !– Conrad Anker
Taille de l'image
# Reducing Image Size
# Use an appropriate base image
FROM node:14-alpine
# Run multiple commands in a single RUN statement
RUN apt-get update && \
apt-get install -y some-required-package
# Remove unnecessary files in the same layer
RUN apt-get update && \
apt-get install -y some-required-package && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
# Use multi-stage builds
FROM node:14-alpine AS build
WORKDIR /app
COPY package*.json ./
RUN npm install
COPY . .
RUN npm run build
FROM node:14-alpine
WORKDIR /app
COPY --from=build /app/dist ./dist
COPY package*.json ./
RUN npm install --production
CMD ["npm", "start"]
# Use a .dockerignore file to exclude unnecessary files from the build
.dockerignore :
node_modules
npm-debug.log– Conrad Anker
Sécurité de l'image
# Avoid running containers as root
RUN addgroup -g 1000 appuser && \
adduser -u 1000 -G appuser -D appuser
USER appuser
# Limit the scope of COPY or ADD instructions
COPY package*.json ./
COPY src/ src/– Conrad Anker
Container Registries
Docker Hub, AWS ECR, Google GCR, Azure ACR, Gitlab, Github GHCR, etc.
build:
image: docker:20.10.16
stage: build
services:
- docker:20.10.16-dind
script:
- docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY
- docker build -t $CI_REGISTRY/group/project/image:latest .
- docker push $CI_REGISTRY/group/project/image:latest– Conrad Anker
Tag
When tagging your image, it is recommended to follow Semantic Versioning guidelines.
<major_version>.<minor_version>.<patch>
# 3.5.11# Tag the latest
docker build -t your-username/app-name:latest .
# Be Descriptive and Consistent
# DON'T :
your-username/app-name-image
# DO :
# Use Environment and Architecture-Specific Tags
your-username/app-name:1.2.3-production-amd64
– Conrad Anker
Lancer un Container
docker run [options] IMAGE [COMMAND] [ARG...]
# Ex :
docker run -d -p 8080:80 nginx
# Listing Containers
docker container ls -a
# Accessing Containers
docker exec -it CONTAINER_ID bash
# Stopping Containers
docker container stop CONTAINER_ID
# Removing Containers
docker container rm CONTAINER_ID
# Remove all containers using the image
docker run --rm IMAGE
– Conrad Anker
Les options habituelles
--name
-p, --publish
-e, --env
-d, --detach
-v, --volume
docker run -it --name=my-ubuntu ubuntu
docker run -d --name=my-nginx -p 80:80 nginx
docker run -d --name=my-mysql -e SQL_ROOT_PASSWORD=secret -e SQL_DATABASE=mydb -p 3306:3306 mysql
docker run -d --name=my-data -v /path/on/host:/path/in/container some-image
Des questions ?
– Conrad Anker
Exercice 1 : Hello from Alpine
Le but de ce premier exercice est de lancer des containers basés sur l'image alpine
-
Lancez un container basé sur alpine en lui fournissant la commande echo hello
-
Quelles sont les étapes effectuées par le docker daemon ?
-
Lancez un container basé sur alpine sans lui spécifier de commande. Qu’observez-vous ?
– Conrad Anker
Exercice 2 : shell intéractif
Le but de cet exercice est de lancer des containers en mode intéractif
-
Lancez un container basé sur alpine en mode interactif sans lui spécifier de commande
-
Que s’est-il passé ?
-
Quelle est la commande par défaut d’un container basé sur alpine ?
-
Naviguez dans le système de fichiers
-
Utilisez le gestionnaire de package d’alpine (apk) pour ajouter un package
$ apk update $ apk add curl
– Conrad Anker
Exercice 3 : foreground / background
Le but de cet exercice est de créer des containers en foreground et en background
Lancez un container basé sur alpine en lui spécifiant la commande ping 8.8.8.8
Arrêter le container avec CTRL-C
Le container est t-il toujours en cours d’exécution ?
Note: vous pouvez utiliser la commande docker ps qui permet de lister les containers qui tournent sur la machine.
Lancez un container en mode interactif en lui spécifiant la commande ping 8.8.8.8
Arrêter le container avec CTRL-P CTRL-Q
Le container est t-il toujours en cours d’exécution ?
Lancez un container en background, toujours en lui spécifiant la commande ping 8.8.8.8
– Conrad Anker
Exercice 4 : publication de port
Le but de cet exercice est de créer un container en exposant un port sur la machine hôte
-
Lancez un container basé sur nginx et publiez le port 80 du container sur le port 8080 de l’hôte
-
Vérifiez depuis votre navigateur que la page par défaut de nginx est servie sur http://localhost:8080
-
Lancez un second container en publiant le même port
Qu’observez-vous ?
– Conrad Anker
Exercice 5 : liste des containers
Le but de cet exercice est de montrer les différentes options pour lister les containers du système
- Listez les containers en cours d’exécution
Est ce que tous les containers que vous avez créés sont listés ?
-
Utilisez l’option -a pour voir également les containers qui ont été stoppés
-
Utilisez l’option -q pour ne lister que les IDs des containers (en cours d’exécution ou stoppés)
– Conrad Anker
Exercice 6 : inspection d'un container
Le but de cet exercice est l'inspection d’un container
- Lancez, en background, un nouveau container basé sur nginx:1.14 en publiant le port 80 du container sur le port 3000 de la machine host.
Notez l'identifiant du container retourné par la commande précédente.
-
Inspectez le container en utilisant son identifiant
-
En utilisant le format Go template, récupérez le nom et l’IP du container
-
Manipuler les Go template pour récupérer d'autres information
– Conrad Anker
Exercice 7 : exec dans un container
Le but de cet exercice est de montrer comment lancer un processus dans un container existant
Lancez un container en background, basé sur l’image alpine. Spécifiez la commande ping 8.8.8.8 et le nom ping avec l’option --name
Observez les logs du container en utilisant l’ID retourné par la commande précédente ou bien le nom du container
Quittez la commande de logs avec CTRL-C
Lancez un shell sh, en mode interactif, dans le container précédent
Listez les processus du container
Qu'observez vous par rapport aux identifiants des processus ?
– Conrad Anker
Exercice 8 : cleanup
Le but de cet exercice est de stopper et de supprimer les containers existants
-
Listez tous les containers (actifs et inactifs)
-
Stoppez tous les containers encore actifs en fournissant la liste des IDs à la commande stop
-
Vérifiez qu’il n’y a plus de containers actifs
-
Listez les containers arrêtés
-
Supprimez tous les containers
-
Vérifiez qu’il n’y a plus de containers
Ex 9 : Dockerizez un serveur web
- Créer un nouveau répertoire et développez un serveur HTTP qui expose le endpoint /ping sur le port 80 et répond par PONG.
🔥 Pour gagner du temps, vous pouvez utiliser l'exemple en Node.js que je vais partager.
- Dans le même répertoire, créez le fichier Dockerfile qui servira à construire l'image de l'application. Ce fichier devra décrire les actions suivantes
- spécification d'une image de base
- installation du runtime correspondant au langage choisi
- installation des dépendances de l’application
- copie du code applicatif
- exposition du port d’écoute de l’application
- spécification de la commande à exécuter pour lancer le serveur
3. Construire l’image en la taguant pong:1.0
-
Lancez un container basé sur cette image en publiant le port 80 sur le port 8080 de la machine hôte
-
Tester l'application
-
Supprimez le container
Dockerizez un serveur web
# File pong.js
var express = require('express');
var app = express();
app.get('/ping', function(req, res) {
console.log("received");
res.setHeader('Content-Type', 'text/plain');
res.end("PONG");
});
app.listen(80);
# File package.json
{
"name": "pong",
"version": "0.0.1",
"main": "pong.js",
"scripts": {
"start": "node pong.js"
},
"dependencies": { "express": "^4.14.0" }
}
Ex 10 : Création d’une image à partir d’un container
-
Lancez une container basé sur une image alpine, en mode interactif, et en lui donnant le nom c1
-
Lancez la commande curl google.com
Qu'observez-vous ?
-
Installez curl à l’aide du gestionnaire de package apk
-
Quittez le container avec CTRL-P CTRL-Q (pour ne pas killer le processus de PID 1)
-
Créez une image, nommée curly, à partir du container c1
Utilisez pour cela la commande commit (docker commit --help pour voir le fonctionnment de cette commande)
- Lancez un shell intéractif dans un container basée sur l’image curly et vérifiez que curl est présent
Ex 11 : Créer un repository Docker Hub
-
Créez un compte sur le Docker Hub
-
Créez le repository www avec la visibilité public
-
Effectuez un login depuis la ligne commande en spécifiant vos identifiants Docker Hub
-
Utilisez une image présente en local et taggez la avec USERNAME/www:1.0 (utilisez pour cela la commande
docker image tag) -
Uploadez l’image USERNAME/www:1.0 sur le Docker Hub
-
Confirmez que l’image est bien présente depuis l'interface web
Docker Compose
3.
– Conrad Anker
Revenons sur les Volumes
# Creating a Volume
docker volume create my-volume
docker volume inspect my-volume
# Mounting a Volume in a Container
docker run -d -v my-volume:/data your-image
docker run -d --mount source=my-volume,destination=/data your-image
# Sharing Volumes Between Containers
docker run -d -v my-volume:/data1 image1
docker run -d -v my-volume:/data2 image2
# Removing a Volume
docker volume rm my-volume– Conrad Anker
Pourquoi utiliser les Volumes ?
# Creating a file in a container
docker container run --name c1 -ti alpine:3.17 sh
# In docker container
mkdir /data && touch /data/hello.txt
exit
# Get the path to data directory.
# Warn: this path is only available in the containers.
docker container inspect -f "{{ json .GraphDriver.Data.UpperDir }}" c1
docker run -it --privileged --pid=host debian nsenter -t 1 -m -u -n -i sh
ls <PATH>
# Remove the container
docker container remove c1
# Error! No folder
docker run -it --privileged --pid=host debian nsenter -t 1 -m -u -n -i sh
ls <PATH>
Demo
– Conrad Anker
Et avec un volume ?
# Creating Dockerfile (Use -v with docker command works too)
FROM alpine:3.17
VOLUME ["/data"]
# Creating docker image
docker image build -t imgvol .
# Creating container
docker container run --name c2 -dt imgvol
docker container exec c2 touch /data/hello.txt
# Check if c2 is running and get volume path in "Source"
docker container ls
docker container inspect -f "{{ json .Mounts }}" c2
docker run -it --privileged --pid=host debian nsenter -t 1 -m -u -n -i sh
ls <PATH>
# Remove the container
docker container stop c2 && docker container rm c2
# Working!
# Warn: if you run again the container, it will create another volume.
docker run -it --privileged --pid=host debian nsenter -t 1 -m -u -n -i sh
ls <PATH>
Demo
– Conrad Anker
Utiliser les volumes avec le CLI
# Get all commands for volumes
docker volume --help
# Creating docker volume `html`
docker volume create --name html
# Check if volume exists
docker volume ls
# Inspect the volume
docker volume inspect html
# Create a container based on Nginx binding the `html` volume with nginx directory
docker run --name www -d -p 8080:80 -v html:/usr/share/nginx/html nginx:1.22
# Check if volume has new files
docker run -it --privileged --pid=host debian nsenter -t 1 -m -u -n -i sh
ls <PATH>
# Open http://localhost:8080 on your browser
# Add new lines to the index.html file
cat<<END >/var/lib/docker/volumes/html/_data/index.html
HELLO !!!
END
# Refresh your browser tab, after, try to remove the container and run it again!Demo
– Conrad Anker
Les réseaux dans Docker
# Get all networks available
docker network ls
# Output
NETWORK ID NAME DRIVER SCOPE
00c616318c53 bridge bridge local
503123cf4745 host host local
1fa4dfe05685 none null localLorsqu’un container est créé, nous pourrons spécifier le network auquel il sera attaché :
none : n’aura pas de connectivité externe. (Debug, monitoring...)
host : bénéficiera de la stack network de la machine hôte.
bridge : pourra communiquer avec les autres containers attaché à ce network. Seulement entre containers sur la même machine. Utilisé par défaut.
– Conrad Anker
Les réseaux dans Docker
# Run docker container
docker container run -d --name c1 alpine:3.8 sleep 10000
# Check Network used by the container
# Bridge will be used by default
docker container inspect -f "{{ json .NetworkSettings.Networks }}" c1
# Clean
docker rm -f c1
# Run docker with Host network
docker container run -ti --name c1 --network=host alpine:3.8 sh
# List all network available in the container
ip link show
# Clean
docker rm c1
# Run docker with None network
docker container run -ti --name c1 --network none alpine:3.8 sh
# List all network available in the container
ip link show
# Ping google works?
ping 8.8.8.8
# Clean
docker rm c1Demo
– Conrad Anker
Communication entre containers
# Run first docker container
docker container run -d --name c1 alpine:3.8 sleep 10000
# Get IP of c1
docker container inspect -f "{{ .NetworkSettings.IPAddress }}" c1
# Run second docker container
docker container run -ti --name c2 alpine:3.8 sh
# Ping c1 works?
ping -c 3 <C1 IP ADDRESS>
# With the first container name?
ping -c 3 c1
# Clean
docker rm -f c1 c2Demo
– Conrad Anker
Créer nos propres networks
# Define the bnet custom network
# –-driver bridge specify from who the new network inherit its behavior
docker network create --driver bridge bnet
# Run docker container with bnet network
docker container run -d --name c1 --network bnet alpine:3.8 sleep 10000
# Get Ip from bnet custom network
docker container inspect -f "{{ json .NetworkSettings.Networks.bnet.IPAddress }}" c1
# Run second docker container with bnet network
docker container run -ti --name c2 --network bnet alpine:3.8 sh
# Ping the first container
ping -c 3 <C1 IP ADDRESS>
# With the container's name?
ping -c 3 c1
# Clean
docker rm -f c1 c2Demo
– Conrad Anker
Pourquoi Docker Compose ?



Microservice
friendly
Reproductibilité
Versions
– Conrad Anker
Créer un docker-compose.yml
# Example
version: "3.9"
services:
web:
image: nginx:latest
ports:
- "80:80"
db:
image: mysql:latest
environment:
MYSQL_ROOT_PASSWORD: mysecretpassword– Conrad Anker
Et si on lançait un Wordpress ?
# Wordpress compose from Docker repositories : https://github.com/docker/awesome-compose/blob/master/wordpress-mysql/compose.yaml
services:
db:
# We use a mariadb image which supports both amd64 & arm64 architecture
image: mariadb:10.6.4-focal
command: '--default-authentication-plugin=mysql_native_password'
volumes:
- db_data:/var/lib/mysql
restart: always
environment:
- MYSQL_ROOT_PASSWORD=somewordpress
- MYSQL_DATABASE=wordpress
- MYSQL_USER=wordpress
- MYSQL_PASSWORD=wordpress
expose:
- 3306
- 33060
wordpress:
image: wordpress:latest
ports:
- 80:80
restart: always
environment:
- WORDPRESS_DB_HOST=db
- WORDPRESS_DB_USER=wordpress
- WORDPRESS_DB_PASSWORD=wordpress
- WORDPRESS_DB_NAME=wordpress
volumes:
db_data:
– Conrad Anker
Et si on lançait un Wordpress ?
# Use docker compose to run the containers
docker compose -f wordpress.yml up
# Open your browser to set up the website
# Stop the docker compose
# Restart the docker compose
docker compose -f wordpress.yml up
# Does the website still working?
# Remove the docker compose
docker compose -f wordpress.yml rm
# Restart the docker compose
docker compose -f wordpress.yml up
# Does the website still working?
# Edit the configuration file to change the volume name
# Restart the docker compose
docker compose -f wordpress.yml up
# Does the website still working?
# Some useful commands
# Check containers status
docker compose -f wordpress.yml ps
# Check containers logs
docker compose -f wordpress.yml logs
# Build all containers images
docker compose -f wordpress.yml buildDemo
– Conrad Anker
Ex 1 : Votre premier compose
- Reprenez l'image de l'exercice précédent "Dockerizez un serveur web".
- Créez un fichier docker compose permettant de lancer deux containers avec l'image du serveur web.
- Lancez votre premier docker compose et vérifiez que vous pouvez accéder aux deux containers via votre navigateur.
– Conrad Anker
Ex 2 : Compose et env de dev
- Pour les prochains exercices, nous allons mettre en place un env de dev avec compose pour vous permettre de voir en direct vos changements.
- Créez un projet "Compose" avec la hiérarchie de fichier suivante :
- Un dossier "pong" reprenant les fichiers de l'exercice "Dockerizez un serveur web", en partant du principe que l'image pong possède le Workspace '/app'.
- Un dossier "monitoring" vide pour l'instant
- Un fichier à la racine de ce projet nommé "docker-compose.yml" vide lui aussi.
– Conrad Anker
Ex 2 : Compose et env de dev
- Ajoutez le service "pong" dans le fichier docker compose permettant de build l'image et de lancer le container sur le port 8080. (Exemple, on utilise ici "build: <path>")
- Ajoutez la configuration de la commande "watch" pour permettre à docker compose de surveiller les changements sur vos fichiers pour mettre à jour les containers (Exemple). Attention : Express charge en mémoire le comportement des routes, il faut potentiellement relancer l'instance pour que les modifications soient disponibles.
- Lancez votre docker compose, vérifiez qu'il est bien disponible sur le port 8080 et que la route /ping fonctionne.
- Modifiez la route /ping pour qu'elle réponde "PONG 2", vérifiez les changements sur le port 8080.
– Conrad Anker
Ex3: Persistence des données - 1
- Réalisez les changements suivants sur "pong" :
- Le serveur web doit maintenant créer un fichier de logs pour enregistrer toutes les requêtes sur la route /ping
- Ajoutez la définition d'un volume dans docker-compose et lier le volume au chemin "/app_output" dans le container "pong".
- Le fichier de log doit être créé en utilisant la variable d'env OUTPUT_PATH permettant d'indiquer le chemin vers le volume où créer le fichier "ping.logs".
- Chaque log doit au moins avoir le timestamp de la requête.
Un exemple du code en nodejs est disponible à la prochaine slide.
– Conrad Anker
Ex3: Persistence des données - 2
// File pong.js
const { openSync, appendFileSync } = require("node:fs");
const express = require("express");
const app = express();
app.get("/ping", function (req, res) {
console.log("received");
res.setHeader("Content-Type", "text/plain");
res.end("PONG 2");
try {
const fd = openSync(`${process.env.OUTPUT_PATH}/ping.logs`, "a");
const log = { timestamp: Date.now() };
appendFileSync(fd, `${JSON.stringify(log)}\n`);
} catch (err) {
console.error(err);
}
});
app.listen(80);
– Conrad Anker
Ex3: Persistence des données - 3
- Créez une nouvelle image en partant du serveur web qui sera le micro-service "monitoring", réalisez les changements suivants :
- Le microservice ne doit avoir qu'une route "/logs" et cette route doit retourner le contenu du fichier de logs en format JSON. (ReadFileSync)
- Le microservice doit avoir en variable d'env "LOGS_PATH" contenant le chemin vers le fichier "ping.logs".
- Vérifiez que vous récupérez les logs sur la route /logs du microservice "monitoring".
- Arrêtez le watch et supprimez les services lancés par docker compose.
– Conrad Anker
Ex 3 : Persistence des données
// File monitoring.js
const { readFileSync } = require("node:fs");
const express = require("express");
const app = express();
app.get("/logs", function (req, res) {
console.log("received");
res.setHeader("Content-Type", "text/plain");
try {
const logs = readFileSync(process.env.LOGS_PATH);
res.end(logs);
} catch (err) {
console.error(err);
}
});
app.listen(80);
– Conrad Anker
Ex 3 : Persistence des données
- Build les images et lancez le docker compose.
- Utilisez plusieurs fois la route /ping puis vérifiez les logs via la route /logs.
- Supprimez et relancez docker compose pour vérifier la persistance des données.
– Conrad Anker
Ex 4 : Sécurité réseau
- Par soucis de sécurité, on veut éviter que le service "pong" et le service "monitoring" soient capable de communiquer via le réseau, faites les changements nécessaire pour que pong ne puisse pas ping monitoring et vis-versa.
- Le niveau de sécurité monte encore, on ne veut plus que le service "monitoring" puisse accéder à internet, faites les changements nécessaire pour que la commande ping 8.8.8.8 ne marche plus sur ce service et que la route /logs ne soit accessible que par les services partageant le réseau de "monitoring". (Voir internal)
– Conrad Anker
Ex 5 : Base de donnée
- Ajoutez une base de donnée MongoDB et la lier à votre service "pong", attention la base de donnée doit persister. (Lien image Docker)
- Utilisez l'example de code suivant pour ajouter un log à une collection ping à chaque requête sur la route /ping.
const { MongoClient } = require("mongodb");
const client = new MongoClient(process.env.MONGODB_URL);
const db = client.db("example");
app.get("/ping", function (req, res) {
// Your code
const collection = db.collection("ping");
collection
.insertOne({ timestamp: Date.now() })
.then((result) => console.log("DB : ", result));
});
– Conrad Anker
Ex 5 : Base de donnée
- Vérifiez la création d'un log à chaque requête sur /ping dans les logs du service "pong".
- Vérifiez la création des logs dans la base de donnée en allant sur votre service "mongo" et en réalisant les commandes suivantes.
# Connect to mongodb with the CLI
mongosh -u <user> -p <password>
# Use the database
show databases;
use <database name>;
# Get all logs
db.ping.find();– Conrad Anker
Ex 6 : API E-commerce
Maintenant que vous savez dialoguer avec une base de donnée, nous allons maintenant créer un nouveau service "api".
Nous allons réaliser une API permettant la création, la modification, la suppression et la consultation de produits.
Le but est de réaliser une API REST en NodeJS en utilisant ExpressJS.
L'API REST doit communiquer avec la MongoDB pour stocker les produits.
N'hésitez pas à tester l'API avec un outil comme Postman ou Insomnia.
– Conrad Anker
Ex 7 : Logging de l'API E-commerce
Maintenant que l'API est fonctionnel, nous allons de nouveau écrire dans le fichier de logs toutes les requêtes qui sont réalisés sur l'API pour pouvoir vérifier les logs dans le futur.
Reprenons la même logique que dans l'exercice 3.
Pour éviter la duplication de code, n'hésitez pas à réaliser une fonction qui s'occupera de gérer le logging.
– Conrad Anker
Ex 8 : Interface E-commerce
Réalisez maintenant un nouveau service dans votre docker compose : "webapp" qui sera l'interface de votre e-commerce dans la technologie de votre choix.
Le but est d'afficher et gérer les produits en permettant à l'interface d'utiliser l'API REST.
Appelez-moi quand vous avez terminé que l'on puisse valider ensemble.
Swarm
4.
– Conrad Anker
Avant tout, installez Multipass qui sera utile pour le TP et les exercices
– Conrad Anker
Qu'est-ce qu'un Cluster ?

Un groupe de serveur relié entre eux pour répondre à des requêtes ou réaliser des calculs.
On appelle un élément du cluster un Noeud (Node).
– Conrad Anker
Pourquoi utiliser un Cluster ?

Pour répondre au concept de "haute disponibilité"
Faciliter les déploiements
Faciliter le monitoring
Gérer les zones de disponibilités
– Conrad Anker
Les stratégies de scaling

Scaling vertical et horizontal
Hardware vs Software
Adapter le cluster à la charge
Automatisations
– Conrad Anker
Les avantages du scaling horizontal

- Pas limité par le Hardware
- Déploiement silencieux
- Gestion des nodes "unhealthy" silencieuse
- Optimisation des coûts
- Limité par le Software
- Stateless obligatoire
- Grande complexité
– Conrad Anker
Comment gérer le scaling ?

Single source of truth (Stateless)
Distributed event system
Load balancing
Un orchestrateur :
AWS ECS, Kubernetes, Swarm, etc
– Conrad Anker
Comment fonctionne un orchestrateur ?

Un système de Stack
Un système de Service
Une instance Manager
Un système de Task
– Conrad Anker
Swarn vs Kubernetes
Les plus :
- Simple
- Intégré directement à Docker
Les moins :
- Limité sur des cas complexes
Les plus :
- Éprouvé par les leaders techniques
- Intégré directement aux Cloud Providers
Les moins :
- Très complexe nécessitant beaucoup d'apprentissage
– Conrad Anker
TP - Découvrons Swarm
– Conrad Anker
Create a Swarm
# Creating 3 nodes simulating a cluster
multipass launch -n node1 && multipass launch -n node2 && multipass launch -n node3
# Install Docker to each nodes
multipass exec node1 -- /bin/bash -c "curl -fsSL https://get.docker.com | sh -"
&& multipass exec node1 -- sudo usermod -aG docker ubuntu
multipass exec node2 -- /bin/bash -c "curl -fsSL https://get.docker.com | sh -"
&& multipass exec node2 -- sudo usermod -aG docker ubuntu
multipass exec node3 -- /bin/bash -c "curl -fsSL https://get.docker.com | sh -"
&& multipass exec node3 -- sudo usermod -aG docker ubuntu
# Let's create a swarm on node 1
multipass shell node1
docker swarm init
# Copy the command to join workers for later
# List all nodes of the Swarm
docker node ls
# Add node 2 and 3 as workers
multipass exec node2 -- /bin/bash -c "docker swarm join --token <token> <ip:port>"
multipass exec node3 -- /bin/bash -c "docker swarm join --token <token> <ip:port>"
# Going back on node 1
multipass shell node1
# List all nodes of the Swarm again
# Only node 1 can do this, try on node 2 and 3 to see what happens
docker node ls– Conrad Anker
Playing with nodes
# Let's inspect node2 from node1
multipass shell node1
docker node inspect node2
# We got :
# Node's status
# Node's role
# Plugins
# TLS Certificate
# As we did with docker, getting the IP address of node2
docker node inspect -f "{{ .Status.Addr }}" node2
# Promote or destitute nodes
# Promote node2 to manager role
docker node promote node2
docker node ls
# node2 is a manager but not the leader
# Demote node2
docker node demote node2
docker node ls
– Conrad Anker
Deploy a service
# Create a new service
docker service create \
--name vote \
--publish 8080:80 \
--replicas 6 \
nginx
# Or use nginx image if you are in another architecture than amd64.
# Check if our tasks are up
docker service ps vote
# No port conflicts?!
# Yes with Swarm routing mesh, distribute requests to 8080 port to each containers listening
# Every requests to any node will be distributed to everyone one by one
# Try to open on your browser using the ip address and port of the node
# Checks the container ID displayed if you use vote
# Add a visualizer
docker service create \
--name visualizer \
--mount type=bind,source=/var/run/docker.sock,destination=/var/run/docker.sock \
--constraint 'node.role == manager' \
--publish "8000:8080" dockersamples/visualizer:stable
# Or use bretfisher/visualizer image if you are in another architecture than amd64
# Try to open the visualizer on your browser with the ip address and port of the node
– Conrad Anker
Update the service
# Show all update command flags
docker service update --help
# Update image to nginx/unit to every node
docker service update --image unit vote
# During this process, each task passes through different states:
# - preparing - ready - starting - running
# Update again to nginx image but faster
# Set update parameters and run again the update
docker service update \
--update-parallelism 3 \
--update-delay 1s \
vote
docker service update --image nginx vote
# Check if Spec and Previous Spec exists by inspecting service
docker service inspect vote
– Conrad Anker
Rollback the service
# Set update parameters for the next rollback to be faster
docker service update \
--rollback-parallelism 3 \
--rollback-delay 1s \
vote
# Let's rollback!
docker service rollback vote
# Swarm can automate rollbacks with healthchecks!
docker service create --name whoami \
--replicas 3 \
--update-failure-action rollback \
--update-delay 10s \
--update-monitor 10s \
--publish 8001:80 \
traefik/whoami
# Check whoami is working
curl node1:8001/
# Change healthcheck, fail and rollback to previous spec
docker service update --health-cmd "curl -f http://localhost:80/health || false" --health-retries 1 --health-timeout 1s whoami
– Conrad Anker
Drain node and remove service
# Remove previous service whoiam
docker service rm whoami
# Check visualizer for changes
# Drain node2
docker node update --availability drain node2
# Check visualizer for changes
# Activate node2
docker node update --availability active node2
# Check visualizer for changes
# Drain node3
docker node update --availability drain node3
# Check visualizer for changes– Conrad Anker
Ex 1: Déployer Pong avec Swarm
- Récupérez les fichiers de l'exercice 5 de Docker Compose
- Dupliquez le fichier de configuration en l'appelant "docker-compose.production.yml"
- Retirez à ce fichier toute la logique de développement des attributs : "build", "command" et "develop".
- Ajoutez les images générées par Docker Compose quand vous réalisez "docker compose build" avec le fichier original dans vos services.
- Utilisez la commande "docker stack deploy --compose-file docker-compose.production.yml production" permettant de générer un Swarm en local.
- Vérifiez votre Swarm et testez les services.
– Conrad Anker
Ex 2: Déployer l'interface E-commerce avec Swarm
- Récupérez les fichiers de l'exercice 8 de Docker Compose
- Dupliquez le fichier de configuration en l'appelant "docker-compose.production.yml"
- Retirez à ce fichier toute la logique de développement des attributs : "build", "command" et "develop".
- Ajoutez les images générées par Docker Compose quand vous réalisez "docker compose build" avec le fichier original dans vos services.
- Utilisez la commande "docker stack deploy --compose-file docker-compose.production.yml production" permettant de générer un Swarm en local.
- Vérifiez votre Swarm et testez les services.
Stratégies DevOps et CI/CD
5.
– Conrad Anker
Rappel CI / CD
Stages : Validation, Build, Unit and Integration Tests
Environments : Review, Staging, Production
Corrélation entre les performances et le bien-être au travail avec le CI / CD et le Lean
Computers perform repetitive tasks; People solve problems.
Key Indicators
- Delivery lead time
- Deployment frequency
- Time to restore service
- Change fail rate
Qu'est-ce que l'intégration continue ?
Intégration fréquente des changements au code source pour éviter les régressions.
Automatiser pour éviter les erreurs humaines et la pénibilité de tâche répétitive.
Utilise une pipeline avec différentes étapes pour vérifier la qualité des changements.

Le principe de non-regression
La régression est un type de bug, une fonctionnalité déjà présente et fonctionnel dans la solution n'est maintenant plus utilisable.
Un autre type de régression que la régression fonctionnelle existe, on l'appelle la régression de performance. Plus précisément, la fonctionnalité consomme maintenant bien plus de ressources pour fonctionner.
C'est un principe fondamental du développement d'éviter les bugs et les régressions.
Par exemple en Agilité, chaque itération du produit doit développer le produit, jamais diminuer involontairement sa qualité ou ses fonctionnalités.
Pourquoi utiliser l'intégration continue ?
Itérer rapidement, apprendre rapidement.

Lean, Agile, Hypothesis driven.
Garder un produit fonctionnel car le déploiement est automatisable avec le Cloud as a service.


Qu'est-ce que le déploiement continu ?
Le code est déployé après chaque modification.
Au vu de la fréquence, on automatise alors le déploiement.
Plusieurs stratégies de déploiement existent. (Blue / Green, Feature Flag, Canary...)

Pourquoi utiliser le déploiement continue ?
Gérer correctement les différents environnements de la solution.
Identifier et corriger rapidement les bugs et régressions.
Améliorer la stabilité de la solution et revenir rapidement à la version d'avant.



Externaliser son infrastructure
Automatiser et monitorer le déploiement des applications
Cloud as a service
Code as Infrastructure
Définir toute son infrastructure via des fichiers de configuration.
Automatiser la création, l'édition et la suppression des ressources de l'infrastructure dans le cloud.
Suivre les différentes versions de l'infrastructure en fonction de la solution.


Automatise le déploiement sur tous les grands Clouds.
Est capable de gérer des grands cluster avec Kubernetes.
S'intègre facilement dans les pipelines CI / CD.

Terraform a été mis en open-source en 2014 sous la Mozilla Public License (v2.0).
Puis, le 10 août 2023, avec peu ou pas de préavis, HashiCorp a changé la licence pour Terraform de la MPL à la Business Source License (v1.1), une licence non open source.
OpenTofu est un fork de la version Open source de Terraform et est géré par la fondation Linux. C'est donc une bonne alternative à Terraform aujourd'hui.
La migration à OpenTofu est extrêmement simple car il n'y a pas de différence de fonctionnement avec Terraform.
Stratégies de déploiement
Blue / Green
Feature Flag
Canary



1. Comment déployer fréquemment sans interrompre les utilisateurs ?
2. Comment déployer fréquemment sans bugs ou régressions pour les utilisateurs ?
3. Comment tester les changements avec de vrais utilisateurs ?
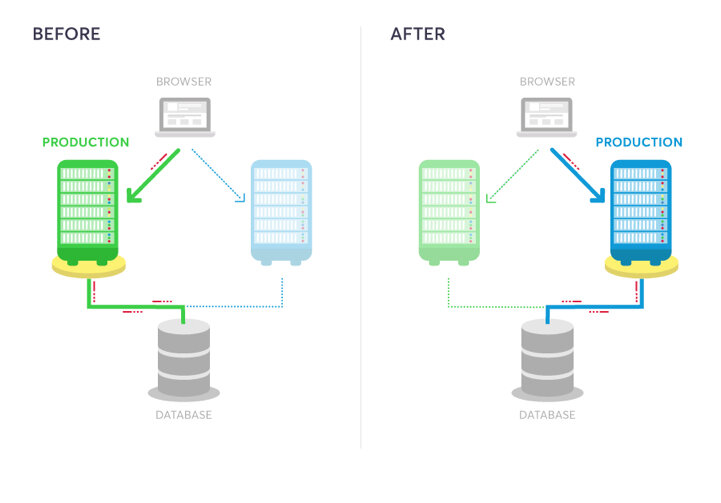
Stratégie Blue / Green
On crée deux environnements distincts mais identiques. Un environnement (Blue) exécute la version actuelle de l'application et un environnement (Green) exécute la nouvelle version de l'application.
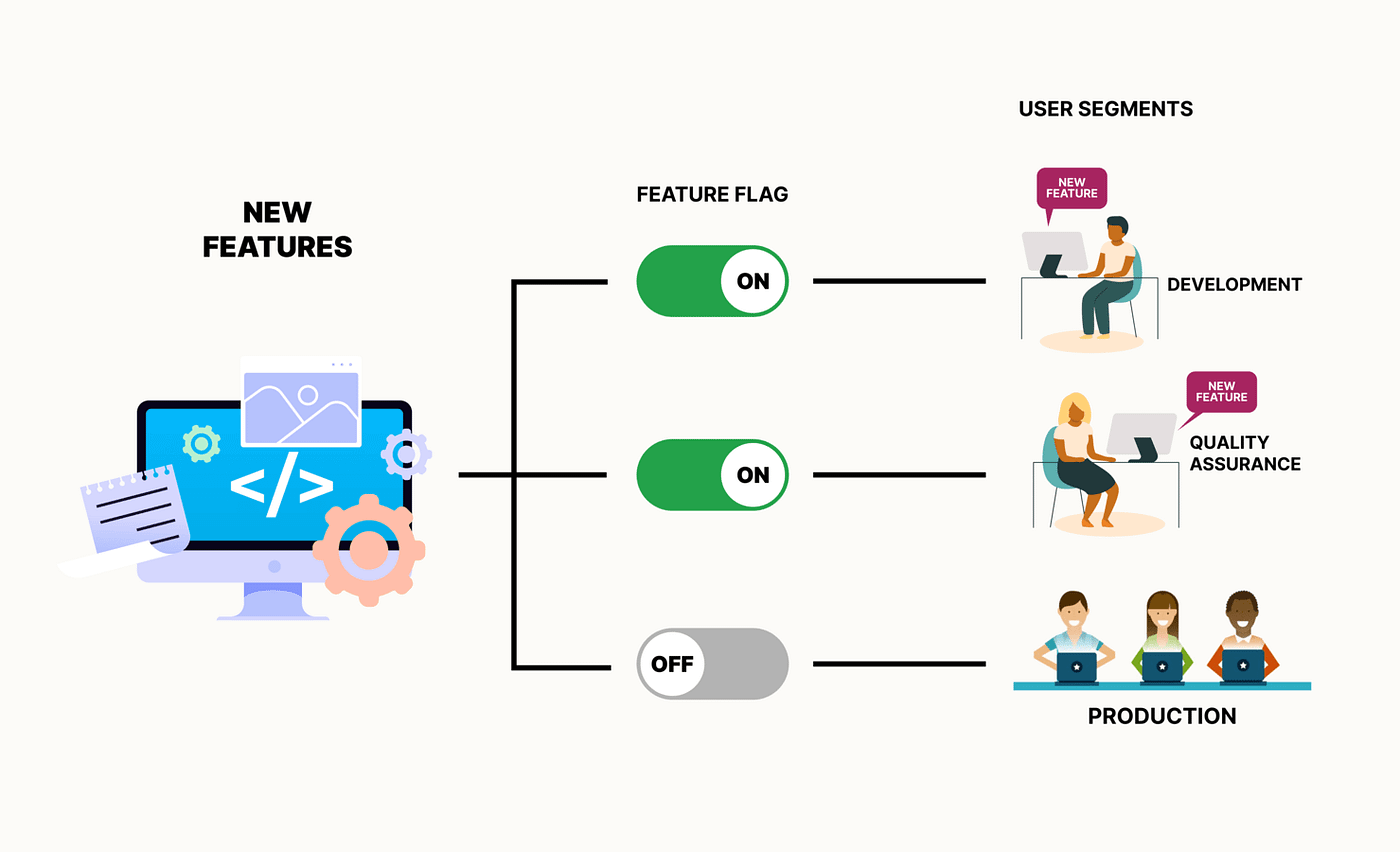
Stratégie Feature Flag
Gère les fonctionnalités dans le code source. Une condition dans le code permet d'activer ou de désactiver une fonctionnalité pendant l'exécution. Voir Unleash.
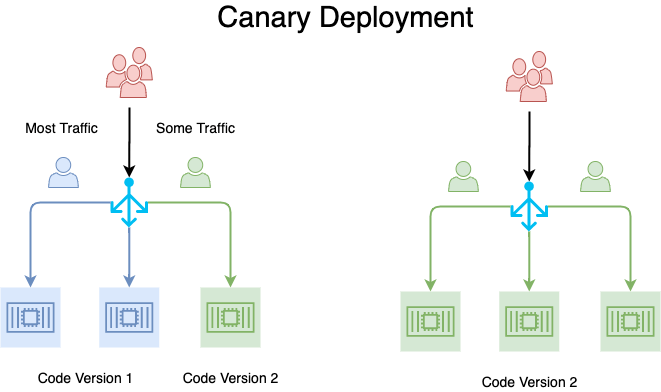
Stratégie Canary
Redirige le trafic d'une portion des utilisateurs en fonction de critères ou d'un simple pourcentage vers la nouvelle version. Après un certain temps ou d'une condition, l'ensemble du trafic est rédirigé.
Mise en place des stratégies avec Gitlab CI
– Conrad Anker
Comment fonctionne Gitlab ?
Gitlab utilise le fichier à la racine de votre dépôt .gitlab-ci.yml qui contient toutes les instructions pour votre pipeline CI / CD. Lors d'évènement comme un commit ou une pull request (ou merge request), la pipeline s'execute grâce à des runners.
Les runners peuvent être hébergé par l'équipe (personnalisé) ou directement par Gitlab (partagé). Ils s'executent sur des machines physiques, virtuelles ou des conteneurs Docker.
– Conrad Anker
Pour aller plus loin
# The configuration for the `remote` backend.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.16"
}
}
required_version = ">= 1.2.0"
}
provider "aws" {
region = var.aws_region
}
# AWS EC2 instance
resource "aws_instance" "example" {
ami = var.ec2_ami
instance_type = var.ec2_instance_type
key_name = var.ec2_key_name
tags = {
Name = "ExampleInstance"
}
user_data = <<-EOF
#!/bin/bash
sudo yum update -y
sudo yum install -y docker
sudo service docker start
# Pull and run your Docker image here
docker run -d -p 80:80 valentinmontagne/nginx-web-example:${var.docker_image_version}
EOF
}Création d'une pipeline CI
Création du compte Gitlab
Si vous n'avez pas encore de compte Gitlab, je vous invite pour la suite du TP et des exercices à créer un compte avec votre adresse étudiante.
Récupérer le projet de base
Maintenant que vous avez un compte Gitlab, vous pouvez "Fork" directement le projet ou le cloner sur votre machine et créer un nouveau projet vide pour récupérer le contenu du projet de base pour réaliser ce TP :
https://gitlab.com/vm-marvelab/ci-cd
(Tous les fichiers sont à mettre à la racine de votre dépôt.)
Auth API
Le projet de base est une API très simple en NodeJS, elle utilise Express pour lancer un serveur qui écoute les requêtes sur des routes définies.
N'hésitez pas à lire le README pour comprendre comment fonctionne la route /auth.
Utilisez la commande pour installer les dépendances du projet :
npm install
Ensuite utilisez la commande pour lancer l'API :
npm start
Configuration pipeline CI - 1
Maintenant que notre projet de base fonctionne, nous allons commencer à intégrer notre pipeline CI.
Pour cela, créez à la racine du projet le fichier .gitlab-ci.yml
N'hésitez pas à installer une extension sur votre IDE pour vous aider avec le format du fichier.
Passons à la prochaine étape.
Configuration pipeline CI - 2
Nous devons spécifier avec quel image notre Runner doit s'executer pour lancer notre pipeline CI, étant une API en nodejs, nous allons utiliser une image nodejs.
Nous allons ajouter des informations sur le cache pour éviter qu'à chaque Job de chaque Stage que nous soyons obliger de réinstaller les dépendances.
# .gitlab-ci.yml file
image: node:latest
cache:
key:
files:
- package-lock.json
paths:
- node_modules/
- .npm/
Configuration pipeline CI - 3
Comme vu ensemble, un Job est une étape spécifique du processus, comme exécuter des tests, compiler du code, ou déployer une application. Un job peut être configuré avec des scripts, des environnements d'exécution, et des conditions spécifiques (par exemple, quand il doit être exécuté). Plusieurs jobs peuvent s'exécuter en parallèle ou en séquence, en fonction des dépendances et de la structure du pipeline.
Un Stage est un groupe de Job et permet d'organiser la pipeline, ils s'exécutent dans l'ordre dont ils sont définis.
Configuration pipeline CI - 4
Définissons nos Stages et réalisons notre premier Job qui sera l'installation des dépendances à la suite du fichier :
stages:
- validate
- test
- build
- release
- deploy
install:
stage: .pre
script:
# define cache dir & use it npm!
- npm ci --cache .npm --prefer-offline
Ici le stage .pre est un Stage déjà créé par Gitlab, il est obligatoirement le premier à être lancé.
Nos Stages sont les étapes habituelles d'une pipeline de CI / CD.
Configuration pipeline CI - 5
Une fois ajouté, réaliser un git commit et un git push pour envoyer les changements à votre dépôt sur Gitlab.
Une fois fait, allez dans la section Build dans la barre à gauche du dépôt sur gitlab.com et cliquez sur Pipelines, il n'y a pas encore de Pipeline lancée, c'est parce que nous n'avons pas encore de Job hors installation.
Passons à l'étape suivante pour réaliser notre Stage validate.
Configuration pipeline CI - 6
Ajoutons maintenant le Stage de validation, pour cela nous allons ajouter les outils Eslint pour vérifier la qualité de notre code NodeJS :
npm init @eslint/config@latest
Choisissez les options "Style et problems", puis "CommonJS", "None of these", "No" pour Typescript et cochez "Node".
Un nouveau fichier eslint.config.mjs est apparu, passons à l'étape suivante.
Configuration pipeline CI - 7
Changez la configuration du fichier pour ignorer les fichiers de tests et ajouter des règles comme ici ne pas avoir de variables inutilisés, de variable non défini ou de console.log dans le code.
// eslint.config.mjs
import globals from "globals";
import pluginJs from "@eslint/js";
export default [
{
ignores: ["**/*.test.js"],
files: ["**/*.js"],
languageOptions: { sourceType: "commonjs" },
},
{ languageOptions: { globals: globals.node } },
pluginJs.configs.recommended,
{
rules: {
"no-unused-vars": "error",
"no-undef": "error",
"no-console": "error",
},
},
];
Configuration pipeline CI - 8
Ajoutons maintenant le script "lint" au package.json pour pouvoir lancer la commande :
npm run lint
// package.json
// ...
"scripts": {
"start": "node src/index.js",
"lint": "eslint src --max-warnings=0"
},
// ...
Configuration pipeline CI - 9
Ajoutons maintenant un console.log que l'on a "oublié" dans une route de notre API dans le fichier index.js qui affiche la variable secret et qui ne devrait pas être dans nos logs !
const express = require("express");
const auth = require("./modules/authentication");
const app = express();
const port = process.env.PORT || 3000;
app.get("/", (req, res) => {
res.send("Hello World!");
});
app.get("/auth/:secret", (req, res) => {
const { secret } = req.params;
const response = auth(secret);
console.log(secret);
res.status(response.status).send(response.message);
});
app.listen(port, () => {
// eslint-disable-next-line no-console
console.log(`Example app listening on http://localhost:${port}`);
});
Configuration pipeline CI - 10
Lancez la commande npm run lint vous devriez maintenant avoir une erreur.
Ajoutons maintenant un Job dans notre pipeline CI pour lancer cette commande automatiquement. A la suite du fichier .gitlab-ci.yml, ajoutez le Job lint dans le Stage validate.
// .gitlab-ci.yml
// ...
install:
stage: .pre
script:
# define cache dir & use it npm!
- npm ci --cache .npm --prefer-offline
lint:
stage: validate
script:
- npm run lint
Configuration pipeline CI - 11
Faites un nouveau commit et faites un push sur la branch main à nouveau et retournez voir les Pipelines de votre dépôt pour voir le résultat.
La même erreur est détecté automatiquement par votre CI maintenant. Enlevez le console.log et faites de nouveau un push pour corriger le problème.
Mais cela serait plus fiable si l'on détectait ce genre de problème avant qu'il n'arrive sur notre pipeline non ?
Mettons en place notre Git hooks à l'étape suivante.
Installation des Git hooks - 1
Maintenant nous allons installer Husky à notre projet, qui permet de mettre en place les Git hooks pour nous permettre d'executer notre validation ou nos tests avant chaque commit. Cela rentre totalement dans l'intégration continue pour éviter de commit du code qui n'est pas fonctionnel ou de mauvaise qualité.
Lancez la commande :
npm install --save-dev husky && npx husky init
Husky génère alors un dossier .husky, ouvrez le fichier pre-commit dans ce dossier et changez npm test par npm run lint.
Installation des Git hooks - 2
Essayez de commit, vous allez maintenant avoir npm run lint qui s'execute automatiquement. Essayez d'oublier à nouveau un console.log dans le code, lors de la tentative de commit vous devriez être bloqué par l'echec de la commande npm run lint.
Maintenant ajoutons les tests à notre pipeline à l'étape suivante.
Ajout des tests - 1
Pour réaliser l'étape des tests, nous allons installer Vitest :
npm install -D vitest
Ensuite, ajoutons dans package.json la commande "test".
// package.json
// ...
"scripts": {
"start": "node src/index.js",
"lint": "eslint src --max-warnings=0",
"prepare": "husky",
"test": "vitest run"
},
"devDependencies": {
// ...
Vérifiez que tout est fonctionnel avec la commande :
npm test
Ajoutez ensuite cette commande au Git hooks.
Ajout des tests - 2
Ensuite, ajoutons notre Job unit-test qui sera dans notre Stage test.
// .gitlab-ci.yml
// ...
install:
stage: .pre
script:
# define cache dir & use it npm!
- npm ci --cache .npm --prefer-offline
lint:
stage: validate
script:
- npm run lint
unit-test:
stage: test
script:
- npm test
Faites un push à nouveau et vérifiez que le job apparait bien dans votre pipeline et qu'il lance les tests.
Variables d'environnement et Rules - 1
Nous allons maintenant permettre de release une version de notre API via notre Pipeline. Ce Job doit alors être manuel pour nous laisser la possibilité d'activer la release au bon moment.
Par sécurité nous allons ajouter des Rules pour éviter que le Job Release se lance sur d'autres branches que main.
Pour créer une nouvelle version nous allons utiliser Release-it :
npm init release-it
Choisissez les réponses "Yes" et "package.json" à l'installation.
Variables d'environnement et Rules - 2
Ajoutez dans le package.json dans le champ "release-it" les informations "git" suivantes :
Voir à l'étape suivante l'ajout au .gitlab-ci.yml du Stage Release.
// package.json
// ...
"dependencies": {
"express": "^4.18.2"
},
"release-it": {
"$schema": "https://unpkg.com/release-it/schema/release-it.json",
"gitlab": {
"release": true
},
"git": {
"commitMessage": "chore: release v${version}"
}
}
// ...Variables d'environnement et Rules - 3
// .gitlab-ci.yml
// ...
unit-test:
stage: test
script:
- npm test
release:
stage: release
when: manual
rules:
- if: '$CI_COMMIT_BRANCH == "main"
&& $CI_COMMIT_TAG == null
&& $CI_COMMIT_TITLE !~ /^chore: release/'
before_script:
- git config user.email $GITLAB_USER_EMAIL
- git config user.name $GITLAB_USER_NAME
- git remote set-url origin
"https://gitlab-ci-token:$GITLAB_TOKEN@$CI_SERVER_HOST/$CI_PROJECT_PATH.git"
- git checkout $CI_COMMIT_BRANCH
- git pull origin $CI_COMMIT_BRANCH --rebase
script:
- npx --yes release-it --ciVariables d'environnement et Rules - 4
// Permet de spécifier que ce Job sera activé manuellement.
when: manual
// Permet d'ajouter des rules au Job pour l'afficher ou non grâce au if.
// Ici le commit doit être sur la branche main, cela ne doit pas être un tag
// et le title du commit doit être différent de ce format.
rules:
- if: '$CI_COMMIT_BRANCH == "main"
&& $CI_COMMIT_TAG == null
&& $CI_COMMIT_TITLE !~ /^chore: release/'Quelques explications :
Variables d'environnement et Rules - 5
Ensuite, pour fonctionner, Release-it a besoin d'une variable d'environnement GITLAB_TOKEN. Pour cela nous allons devoir l'ajouter manuellement, mettez votre souris sur Settings et cliquez sur CI / CD, ensuite ouvrez le menu Variables. Ouvrez sur une autre page vos Access Tokens en mettant votre souris sur votre profil en haut à gauche, puis en cliquant sur Préférences, là vous devez cliquer sur Access Tokens et générer un nouveau Token avec les droits api.
Ajoutez ce token dans une nouvelle variable CI / CD de votre projet GITLAB_TOKEN.
Faites un push et lancez la release.
Appelez-moi quand vous avez terminé pour que l'on valide ensemble le TP.
Exercice 1 - Retirez des étapes
Nous avons un problème, ici après la release, deux pipelines se lancent, cela est inutile.
Vous devez retirer les étapes validate et test en ajoutant des rules aux Jobs pour qu'ils ne se lancent pas lorsqu'un tag est créé ou que le commit est le commit de release "chore: release".
Appelez-moi pour que l'on puisse valider ensemble.
Documentation :
Exercice 2 - Ajouter une étape
Préparons un nouveau Job e2e-test dans le Stage test, pour l'instant il ne doit juste réaliser la commande suivante :
echo "Hello E2E !"
Il doit être visible uniquement dans les Merge Requests (Pull Requests).
Appelez-moi pour que l'on puisse valider ensemble.
Exercice 3 - Ajouter une variable d'environnement
Préparons un nouveau Job only-canary dans le Stage validate, qui ne doit se lancer que quand l'on lance la pipeline pour l'environnement Canary, pour cela, nous allons créer une variable d'environnement "ENV_TARGET" qui doit être égale à "canary" pour que le Job se lance.
Pour l'instant il ne doit juste réaliser la commande suivante :
echo "Hello Only Canary !"
Appelez-moi pour que l'on puisse valider ensemble.
Documentation :
Exercice 4 - Ajouter des dépendances
Préparons un nouveau Job integration-test dans le Stage test, qui ne doit se lancer que quand le Job unit-test réussi, de même pour e2e-test qui ne doit maintenant se lancer que quand integration-test réussi.
Pour l'instant il ne doit juste réaliser la commande suivante :
echo "Hello Integration !"
Appelez-moi pour que l'on puisse valider ensemble.
Documentation :
Exercice 5 - Enlevons la duplication de code
Durant les derniers exercices, nous avons souvent appliqué le même comportement à plusieurs Jobs. Pour éviter la duplication de code et que le fichier soit plus maintenable, utilisons les Anchors en YAML pour pouvoir faire hériter à nos Jobs une configuration.
Appelez-moi pour que l'on puisse valider ensemble.
TP - Déployer Docker
Maintenant que vous avez terminé l'intégration continue, nous allons maintenant voir le côté déploiement continu.
Pour cela, nous allons rajouter les étapes de builds pour l'image Docker et du déploiement de celle-ci.
Vous devez réaliser un fichier Dockerfile pour build le projet.
Ajouter l'étape suivante build-image :
# If your language needs to build you can create another build job before
# Add docker job to build the image
# Only for testing purpose, you can add a docker run + command to check health
# Gitlab has a lot of variables to use in the pipeline
# Here we are using $CI_REGISTRY_IMAGE and $CI_COMMIT_SHORT_SHA
build-image:
stage: build
image: docker:20.10.16
services:
- docker:20.10.16-dind
variables:
IMAGE_TAG: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA
script:
- docker image build -t $IMAGE_TAG .
TP - Déployer Docker - 2
Ici, nous utilisons un service spécial docker:20.10.16-dind pour permettre l'utilisation de Docker dans un container Docker.
On pourrait ici build plusieurs images si besoin durant cette étape.
Vérifiez que cette étape fonctionne en réalisant un push sur votre branche.
Ajoutez ensuite l'étape deploy-image :
deploy-image:
needs:
- release
image: docker:20.10.16
stage: deploy
rules:
- if: '$CI_COMMIT_BRANCH == "main" && $CI_COMMIT_TAG == null && $CI_COMMIT_TITLE !~ /^chore: release/'
services:
- docker:20.10.16-dind
variables:
IMAGE_TAG: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA
script:
- docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY
- docker image build --platform=linux/amd64 -t $IMAGE_TAG -t $CI_REGISTRY_IMAGE:latest .
- docker push $CI_REGISTRY_IMAGE --all-tags
environment: productionTP - Déployer Docker - 3
Vérifiez après avoir push à nouveau les changements que votre image est bien ajoutée dans votre Container Registry en allant dans le menu Deploy sur votre dépôt Gitlab. C'est terminé !
Voici un exemple pour déployer sur un serveur distant, ceci n'est pas la meilleure méthode mais elle est très simple, nous verrons après comment déployer proprement sur le Cloud.
deploy:
needs:
- deploy-image
stage: deploy
rules:
- if: '$CI_COMMIT_BRANCH == "main" && $CI_COMMIT_TAG == null && $CI_COMMIT_TITLE !~ /^chore\(release\): publish/ && $CI_COMMIT_TITLE !~ /^chore\(pre-release\): publish/'
before_script:
- 'which ssh-agent || ( apt-get update -y && apt-get install openssh-client -y )'
- mkdir -p ~/.ssh
- eval $(ssh-agent -s)
script:
- ssh-add <(echo "$SSH_PRIVATE")
- ssh -o StrictHostKeyChecking=no "$SSH_SERVER" 'which docker || (sudo yum update -y && sudo yum install -y docker && sudo service docker start)'
- <SAME> "sudo docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY"
- <SAME> "(sudo docker rm -f example || true) && sudo docker run -p 80:3000 -d --name example registry.gitlab.com/vm-marvelab/docker-cicd:$CI_COMMIT_SHORT_SHA"
environment: production– Conrad Anker
Ex 1 : Créer une pipeline CI/CD
- Récupérez les fichiers de l'exercice 1 de Docker Swarm.
- Créer un repository sur Gitlab pour créer une CI / CD en y ajoutant les fichiers.
- Réaliser l'étape de validation de la CI.
- Réaliser l'étape de build de l'image Docker de la CI.
- Réaliser l'étape de release de la CD.
- Réaliser l'étape de publication de l'image Docker de la CD.
– Conrad Anker
Ex 2 : Créer une pipeline CI/CD pour l'interface E-commerce
- Récupérez les fichiers de l'exercice 2 de Docker Swarm.
- Créer un repository sur Gitlab pour créer une CI / CD en y ajoutant les fichiers.
- Réaliser l'étape de validation et tests de la CI.
- Réaliser l'étape de build des images Docker de la CI.
- Réaliser l'étape de publication des images Docker de la CD.
– Conrad Anker
Ex 3 : Déployer en production
Pour réaliser cet exercice, vous allez avoir besoin d'un VPS ou serveur fourni par l'école. Faites la demande si vous n'en avez pas encore un.
Ensuite, modifiez votre pipeline CI / CD pour ajouter l'étape du déploiement de votre Pong avec l'exemple ci-dessous :
Pour cela, assurez-vous d'avoir Docker d'installé sur votre VPS.
Kubernetes
6.
L'historique de Kubernetes
Créé par Google, nommé en interne Borg pour déployer et gérer des milliers d’applications.
En 2014, Google décide de rendre Open source le projet pour accélérer son développement.
En 2015, transfert à la Cloud Native Computing Foundation pour être adopté très rapidement par l'industrie.


Validé par les plus grands
Depuis son lancement, Kubernetes a évolué rapidement grâce à une communauté active et une forte adoption par des entreprises de toutes tailles. Les contributions de divers acteurs de l’industrie, y compris des géants de la technologie comme IBM, Microsoft, Red Hat et d’autres, ont enrichi le projet en ajoutant des fonctionnalités avancées et en améliorant sa stabilité et sa performance.
Le projet permet de fluidifier la collaboration entre équipes et de garantir des applications scalables, résilientes et sécurisées.
Pourquoi utiliser Kubernetes ?
Centraliser la gestion des conteneurs : déployer, surveiller et automatiser l'adaptation.
Garantir la haute disponibilité des applications : redondance, self-healing et load balancing.
Simplifier la scalabilité qu'elle soit verticale ou horizontale en automatisant le déploiement de Pods.


Pourquoi utiliser Kubernetes ?
Automatiser les déploiements et les mises à jour : rolling updates, rollbacks, canary releases.
Optimiser les ressources en attribuant les conteneurs aux nœuds disponibles en tenant compte de leurs ressources.
Intégrer la sécurité dans les processus : isolation des workloads, gestion fine des accès, chiffrement.



Comment fonctionne Kubernetes ?
Le plan de contrôle (Control Plane)
C’est le cerveau de Kubernetes. Il orchestre toutes les actions dans le cluster.
Les nœuds de travail (Worker Nodes)
Ce sont les muscles. Ils exécutent les conteneurs et assurent leur bon fonctionnement.

L'architecture d'un Cluster Kubernetes
Cluster
Control Panel
Worker 1
C1
C2
C3
Worker 2
C1
C2
C3
Worker X
C1
C2
C3
Le Control Panel
Cluster
Control Panel
Worker 1
C1
C2
C3
Worker 2
C1
C2
C3
Worker X
C1
C2
C3
Controller Manager
Scheduler
ETCD
API
Le rôle central du control plane
Décision : où et comment les applications doivent être déployées dans le cluster ?
Gestion de l’état : s’assurer de la santé des applications et corriger les écarts si nécessaire.
Exposition : fournir aux utilisateurs et aux outils une interface pour interagir avec le cluster.



API Server : le point d’entrée
Valide les requêtes : vérifie les demandes, que les utilisateurs sont autorisés à les exécuter.
Exécute les actions : envoie les requêtes aux autres composants pour qu’ils les exécutent.
Expose l’état du cluster : permet le monitoring sur des objets Kubernetes
(Pods, Services, etc.).



ETCD : la mémoire du cluster
etcd est une base de données clé-valeur distribuée qui stocke toutes les informations critiques du cluster. C’est dans etcd que réside la vérité sur :
- La configuration du cluster.
- L’état des ressources (comme les Pods, les nœuds, etc…).
- Les secrets et autres données sensibles.
Pourquoi etcd est-il si important ?
Parce qu’il garantit que le cluster est toujours synchronisé. Si un composant a besoin de savoir quelle est la configuration actuelle, il interroge etcd.
Scheduler : le planificateur
Le scheduler est le composant chargé de décider où déployer chaque Pod. Pour cela, il analyse :
- Les besoins des Pods (mémoire, CPU, stockage, etc.).
- Les ressources disponibles sur chaque nœud.
Le scheduler ne fait qu’une chose, mais il la fait bien : il trouve le nœud idéal pour chaque Pod. Son rôle est essentiel pour garantir une utilisation optimale des ressources et éviter les surcharges.
Controller Manager : le chef d’orchestre
Node Controller : détecte quand un nœud est hors ligne et met à jour l’état du cluster en conséquence.
Replication Controller : vérifie le nombre de réplicas pour chaque déploiement.
Endpoints Controller : met à jour les endpoints des Services en fonction des Pods disponibles.


Cloud Controller Manager : l’intégrateur cloud
Ce composant est facultatif et uniquement utilisé si le cluster est déployé sur un cloud provider. Il permet de gérer les fonctionnalités spécifiques au cloud, comme :
- La création automatique de load balancers.
- La gestion des volumes de stockage cloud.
- L’intégration des services réseau natifs du provider.
Le cloud controller manager facilite l’intégration entre Kubernetes et les infrastructures cloud.
Qu'est-ce qu'un Worker Node ?
Un Worker Node est une machine (physique ou virtuelle) qui s’occupe d’exécuter les Pods, les unités de base de Kubernetes.
Chaque nœud contient plusieurs composants qui collaborent pour gérer les conteneurs et maintenir la communication avec le Control Plane via l'API Server.
Cluster
Control Panel
Worker 1
C1
C2
C3
Worker 2
C1
C2
C3
La gestion du réseau
Les plugins CNI comme Calico ou Flannel, pour différentes stratégies côté réseau.
Chaque pod possède une IP et peut communiquer directement avec les autres pods sans NAT.
Kube Proxy configure les règles réseau pour assurer la communication entre les services et les pods.

Les Worker Nodes
kubelet
Reçoit des instructions et assure la création, la suppression et la gestion des Pods.
kube-proxy
Gère le réseau local des Pods pour permettre aux services de communiquer entre eux.
Runtime des conteneurs
Gère les images des conteneurs, leur démarrage et leur arrêt.

Que se passe-t-il quand on lance un nouveau Pod ?
kubectl apply -f mon-pod.yaml- L’API Server reçoit la requête et valide son contenu.
- Il enregistre ensuite ces informations dans Etcd, qui conserve l’état souhaité du cluster.
- L’API Server notifie alors le Scheduler qu’un nouveau pod doit être créé.
Etcd est le référentiel source de vérité : il stocke en permanence la configuration et l’état du cluster.
Le Scheduler attribue un nœud au pod
- Le Scheduler analyse les ressources disponibles sur les nœuds (CPU, RAM, affinité…).
- Il sélectionne le meilleur nœud disponible pour exécuter le pod.
- L’API Server informe le Kubelet du nœud choisi qu’un nouveau pod doit être déployé.
Kubernetes ne lance pas directement les conteneurs, il planifie leur exécution en fonction des ressources disponibles.
Le Kubelet démarre le conteneur
- Le Kubelet sur le nœud sélectionné récupère les spécifications du pod.
- Il demande alors au runtime de conteneurs (ex. Docker, containerd, Podman) d’exécuter le conteneur.
- Une fois le conteneur lancé, Kubelet met à jour son état et le transmet à l’API Server.
Le Kubelet est l’agent qui assure le bon fonctionnement des pods sur chaque nœud.
Configuration du réseau par Kube Proxy
- Kube Proxy configure les règles réseau nécessaires pour permettre aux pods et aux services de communiquer entre eux et avec l’extérieur.
- Kubernetes utilise un modèle réseau plat, où chaque pod possède une adresse IP unique accessible sans NAT.
Grâce à Kube Proxy, les pods peuvent échanger des données sans nécessiter de configurations réseau complexes.
Auto-réparation en cas de panne
- Si un pod tombe en panne (exemple : crash du conteneur ou nœud défaillant), le Controller Manager détecte une divergence entre l’état actuel et l’état souhaité du cluster.
- Il demande alors au Scheduler de redéployer le pod sur un autre nœud disponible.
- Le Kubelet du nouveau nœud prend le relais et redémarre le pod.
C’est grâce à ce mécanisme de réconciliation automatique que Kubernetes garantit une haute disponibilité des applications.
Synthèse
| Composant | Rôle |
|---|---|
| API Server | Point d’entrée pour toutes les interactions avec Kubernetes |
| Etcd | Stocke l’état souhaité du cluster |
| Scheduler | Assigne les pods aux nœuds disponibles |
| Kubelet | Gère l’exécution des conteneurs sur chaque nœud |
| Kube Proxy | Configure la communication réseau entre les pods et services |
| Controller Manager | Détecte les anomalies et corrige les écarts avec l’état souhaité |
Les boucles de réconciliation : un contrôle constant
- L’état souhaité : suit votre configuration.
- L’état actuel : Kubernetes surveille en permanence l’état réel des ressources. Si un pod manque ou si un nœud tombe en panne, il détecte une divergence entre l’état actuel et l’état souhaité.
- Réconciliation : Kubernetes déclenche une boucle pour corriger cette divergence. Par exemple, s’il manque un pod, il en déploie un nouveau.
Ce processus est continu : Kubernetes compare l’état souhaité et l’état réel à intervalles réguliers, et corrige tout écart.
Les ressources
Les Namespaces : Isoler et organiser vos ressources
Dans un cluster Kubernetes, toutes les ressources (Pods, Services, ConfigMaps, etc.) sont créées par défaut dans un espace commun appelé namespace “default”.
Cependant, pour une meilleure organisation et isolation, Kubernetes permet de créer plusieurs Namespaces.
Chaque Namespace agit comme un compartiment isolé, où les ressources ne peuvent pas interagir directement avec celles d’un autre Namespace, sauf configuration explicite.
Pourquoi utiliser les namespaces dans Kubernetes ?
Organisation : segmenter en namespaces permet de gérer et de superviser les déploiements.
Isolation des ressources entre différentes équipes ou projets, évitant ainsi les conflits.
Gestion des accès : applique des politiques de sécurité spécifiques à chaque espace.

Namespace en mode impératif
# Créer un namespace en mode impératif
kubectl create namespace mon-namespace
# Lister tous les namespaces
kubectl get namespaces
# Voir les détails d'un namespace
kubectl describe namespace mon-namespace
# Supprimer un namespace
kubectl delete namespace mon-namespace
Attention : La suppression d’un namespace entraîne également la suppression de toutes les ressources qu’il contient (pods, services, configmaps…).
Namespace en mode déclaratif
# Exemple d'un fichier YAML pour un namespace
apiVersion: v1
kind: Namespace
metadata:
name: mon-namespace
labels:
environment: test
# Appliquer un namespace en mode déclaratif
kubectl apply -f mon-namespace.yaml
Cette approche est recommandée pour une gestion versionnée des namespaces et pour les environnements de production.
Spécifier un namespace
# Lister les pods dans un namespace spécifique
kubectl get pods -n mon-namespace
# Créer un pod directement dans un namespace
kubectl run nginx --image=nginx -n mon-namespace
# Consulter les événements d’un namespace
kubectl get events -n mon-namespace
# Changer le namespace par défaut de la session actuelle
kubectl config set-context --current --namespace=mon-namespace
Par défaut, toutes les commandes kubectl s’exécutent dans le namespace default. Pour interagir avec un autre namespace, on utilise l’option -n (ou --namespace).
Toujours utiliser des namespaces dédiés pour chaque projet ou environnement.
Les Pods
Les pods sont éphémères et peuvent être créés, détruits ou redéployés à tout moment, ce qui en fait une ressource flexible pour vos applications.

Les pods sont les unités de base dans Kubernetes.
Ils regroupent un ou plusieurs conteneurs qui partagent des ressources et un cycle de vie commun.
Qu'est-ce qu'un Pod ?
Un pod est une enveloppe logique qui regroupe un ou plusieurs conteneurs partageant un même environnement d’exécution. Chaque pod possède :
- Une adresse IP unique dans le cluster, ce qui permet aux conteneurs qu’il héberge de communiquer facilement entre eux.
- Un espace de stockage partagé à travers des volumes Kubernetes, ce qui facilite l’échange de données entre les conteneurs du pod.
- Un ensemble de métadonnées définissant son comportement, ses règles d’affinité et ses ressources allouées.
Un pod peut contenir un ou plusieurs conteneurs, mais dans la majorité des cas, il n’héberge qu’un seul conteneur principal.
Création de Pod en mode impératif
# Exemple de création d’un Pod exécutant un serveur Nginx
kubectl run mon-pod --image=nginx
# Vérifier l’état d’un Pod
kubectl get pods
# Afficher les détails d’un Pod
kubectl describe pod mon-pod
# Supprimer un Pod
kubectl delete pod mon-pod
Un Pod étant immuable, il n’est pas possible de modifier directement ses paramètres.
Pour mettre à jour un Pod :
- Je supprime l’ancien Pod.
- Je redéploie un nouveau Pod avec les modifications.
Création de Pod en mode déclaratif
# Exemple de définition d’un Pod exécutant un serveur Nginx (YAML)
apiVersion: v1
kind: Pod
metadata:
name: mon-pod
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 8080
# Appliquer le Pod
kubectl apply -f mon-pod.yaml
Cette approche est recommandée pour une gestion versionnée des namespaces et pour les environnements de production.
Intéractions avec un Pod
# Afficher les logs d'un pod
kubectl logs mon-pod
# D'un container d'un Pod
kubectl logs mon-pod -c mon-container
# En temps réel
kubectl logs -f mon-pod
# Accéder à un shell interactif dans un Pod
kubectl exec -it mon-pod -- bash
# Ou pour des environnements avec seulement un sh comme Alpine
kubectl exec -it mon-pod -- /sh
# Inspecter les évènements liés à un Pod
kubectl get events
# Analyser les ressources utilisées d'un Pod
kubectl top pods
# Ce qui donne
NAME CPU(cores) MEMORY(bytes)
mon-pod 250m 150Mi
# Debug un Pod
kubectl debug mon-pod -it --image=busybox
TP 1 - Pods
– Conrad Anker
TP 1 - Pods - Installation
Nous allons commencer ce TP en installant tous les outils nécessaire à l'utilisation de Kubernetes. Pour cela nous allons utiliser Minikube pour nous permettre de simuler un cluster en local sur notre machine.
Pour Windows :
Télécharger le fichier .exe depuis le site officiel.
Pour MacOs :
brew install minikube
Pour Linux, voir la slide d'après.
– Conrad Anker
TP 1 - Pods - Installation
Installation pour Linux :
# Avec un script automatique
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
# Avec un package manager (Debian/Ubuntu)
sudo apt update && sudo apt install -y curl
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
Ensuite, liez Kubernetes à Docker pour la création des containers :
minikube start --driver=docker
N'oubliez pas que Docker doit être lancé.
Vérifiez ensuite le bon fonctionnement :
minikube status
kubectl get nodes
– Conrad Anker
TP 1 - Pods
Maintenant que l'installation est terminée, on va déployer un premier Pod manuellement et explorer les différentes façons de gérer les Pods.
Testons un premier Pod avec une image Nginx :
kubectl run mon-pod --image=nginx
Puis, vérifions son état :
kubectl get pods
On veut plus de détails pour voir ce qu'il se passe sur le Pod :
kubectl describe pod mon-pod
Attendez que le Pod soit en statuts Running avant de passer à la prochaine étape.
– Conrad Anker
TP 1 - Pods
Maintenant que votre Pod est en Running, nous allons vérifier que Nginx marche correctement en utilisant la commande :
kubectl exec mon-pod -it -- bash
Sur le bash du Pod, réaliser la commande :
curl localhost:80
Vous devriez alors avoir la réponse de Nginx.
On peut maintenant supprimer le pod :
kubectl delete pod mon-pod
Nous allons maintenant créer un Pod en déclaratif.
– Conrad Anker
TP 1 - Pods
Créez un fichier pod-nginx.yml et ajoutez le code suivant :
apiVersion: v1
kind: Pod
metadata:
name: mon-pod
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80Appliquez le fichier avec la commande :
kubectl apply -f pod-nginx.yml
Maintenant vérifiez son état comme précédemment.
Consultez maintenant les logs du Pod :
kubectl logs mon-pod
Supprimez le Pod :
kubectl delete -f pod-nginx.yml
– Conrad Anker
Exercice 1 - Pods - Plusieurs containers
Maintenant que vous êtes plus à l'aise avec les Pods, vous allez devoir trouver le moyen de rajouter un container de plus dans notre Pod.
Pour cela, ajoutez un container busybox pour lancer un container linux avec des outils de base pour réaliser des tests avec wget.
Ensuite, tentez de faire une requête du container busybox vers le container nginx avec la commande :
wget -qO- http://localhost
– Conrad Anker
Exercice 2 - Pods - Redis
Pour continuer à tester la communication entre containers d'un Pod, vous devez déployer sur un Pod une image de Redis et d'un autre container de test avec une image Redis.
Utilisez l'autre instance redis et testez la commande ping sur l'autre instance grâce au redis-cli.
Maintenant, ajoutez une nouvelle clé / valeur dans le Redis qui s'appelle "hello" et qui doit avoir comme valeur "world".
Testez de récupérer la valeur via la clé "hello".
Appelez-moi pour qu'on puisse valider ensemble.
TP 2 - Namespaces
– Conrad Anker
TP 2 - Namespaces : Découverte
Dans Kubernetes, un Namespace est une ressource qui permet de partitionner un cluster en plusieurs environnements isolés. Il offre une séparation logique des ressources pour mieux organiser les déploiements et les services.
Listez les namespaces déjà présents avec la commande :
kubectl get namespaces
Afficher les ressources d’un Namespace spécifique :
kubectl get pods -n kube-system
– Conrad Anker
TP 2 - Namespaces : Création et utilisation - 1
Nous allons maintenant créer un environnement dev qui contiendra toute l'infrastructure pour développer notre solution :
kubectl create namespace dev
Vérifiez sa création :
kubectl get namespaces
Définir dev comme Namespace par défaut pour éviter de le préciser à chaque commande. Pour cela, utilisez la gestion des contextes :
kubectl config set-context --current --namespace=dev
– Conrad Anker
TP 2 - Namespaces : Création et utilisation - 2
Vérifiez que le contexte est bien actif :
kubectl config view --minify | grep namespace
Nous allons maintenant déployer des ressources dans ce namespace. Créez le fichier pod-nginx.yml :
apiVersion: v1
kind: Pod
metadata:
name: mon-pod
namespace: dev
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80Lancez le déploiement : kubectl apply -f pod-nginx.yml
Vérifiez que le contexte est bien actif :
kubectl config view --minify | grep namespace
Nous allons maintenant déployer des ressources dans ce namespace. Créez le fichier pod-nginx.yml :
– Conrad Anker
TP 2 - Namespaces : Création et utilisation - 3
Vérifiez que les Pods ont bien été créé dans le contexte dev :
kubectl get pods -n dev
Vous avez réussi à créer un environnement grâce à un namespace, un contexte et à déployer automatiquement dans l'environnement !
– Conrad Anker
Exercice 1 - Namespaces - Nettoyer un Namespace entier
Maintenant qu'on a créé un environnement dev, trouvez la commande permettant de supprimer tout l'environnement en une fois.
– Conrad Anker
Exercice 2 - Namespaces - Naviguer dans les contextes
Créez deux environnements : dev et prod.
L'environnement dev doit avoir un Pod avec deux containers : un nginx et un busybox.
L'environnement prod doit avoir un Pod avec deux containers : un redis et un busybox.
Naviguez d'un contexte à l'autre pour déployer automatiquement dans le bon environnement sans avoir à spécifier dans la commande le namespace.
Vérifiez avec une commande les pods de l'environnement dev.
Ensuite, vérifiez pour l'environnement prod.
– Conrad Anker
Exercice 3 - Namespaces - Isolation
Créez un namespace isolated pour vérifier que les Pods déployé à l'intérieur ne sont pas accessibles dans un autre :
Créez un autre Pod dans le namespace default et un autre dans isolated, essayez de curl le Pod du serveur web avec l'un et l'autre.
Appelez-moi pour que l'on valide ensemble.
kubectl create namespace isolated
# Créez le Pod hébergeant un serveur web :
kubectl run webserver --image=httpd --namespace=isolated --port=80
# Exposez le Pod via un Service :
kubectl expose pod webserver --namespace=isolated --port=80 --target-port=80 --name=web-service– Conrad Anker
Exercice 4 - Namespaces - k9s
Les services
Les services : Exposer et connecter vos pods
Les services sont une ressource essentielle de Kubernetes qui permet de connecter vos pods entre eux ou de les rendre accessibles à l’extérieur du cluster.
Alors que les pods sont éphémères et peuvent être recréés à tout moment, les services offrent un point d’accès stable et persistent, facilitant la communication dans vos applications.
Pourquoi utiliser les services ?
Une communication stable entre les pods, assigne une adresse IP fixe et un nom DNS aux pods qu’il gère.
L’équilibrage de charge, réparti le trafic entre plusieurs pods pour optimiser la performance et la résilience de l’application.
L’exposition des applications, rends accessibles des applications à l’extérieur du cluster (Port, Load balancer, Ingress).
Exemple d'utilisation
Imaginons une application web avec :
- Un frontend (React, Angular, etc.),
- Un backend (API en Node.js, Python, etc.),
- Une base de données (PostgreSQL, MySQL, etc.).
Le backend doit communiquer avec la base de données, mais celle-ci tourne dans un pod dont l’IP change régulièrement. Grâce aux services Kubernetes, le backend peut simplement appeler database-service:5432 au lieu de chercher dynamiquement l’IP du pod contenant la base de données.
Les services Kubernetes garantissent ainsi une communication robuste et fiable entre les composants d’une application, en assurant une connectivité dynamique et transparente dans un environnement distribué.
Comment lier les pods à un service ?
Dans Kubernetes, les services utilisent un mécanisme puissant pour cibler les pods qu’ils doivent gérer : les labels et les selectors.
Les labels sont des paires clé-valeur associées aux objets Kubernetes (comme les pods) pour les identifier et les organiser.
Les selectors permettent aux services de sélectionner dynamiquement les pods à inclure en fonction de ces labels.
Pourquoi utiliser les labels et selectors ?
Grouper des pods ayant une même fonction (ex: tous les pods d’une API backend).
Distinguer différentes versions d’une application (version=beta et stable).
Appliquer des règles de routage avancées sans modifier la configuration du service.

Définir des labels sur un Pod
# Exemple de déploiement d’un pod avec un label
apiVersion: v1
kind: Pod
metadata:
name: backend-pod
labels:
app: backend
version: v1
spec:
containers:
- name: backend
image: my-backend:latest
# Ici, le pod backend-pod possède deux labels :
# app: backend (pour identifier le service)
# version: v1 (pour distinguer différentes versions)Dans un fichier YAML, un label est défini dans la section metadata.labels.
Sélectionner des pods avec un selector
# Exemple d'un service qui select le label app=backend.
apiVersion: v1
kind: Service
metadata:
name: backend-service
spec:
selector:
app: backend
ports:
- protocol: TCP
port: 80
targetPort: 8080
# Plusieurs labels à la fois
selector:
matchLabels:
app: my-app
env: production
# Un label ou un autre label
selector:
matchExpressions:
- { key: app, operator: In, values: [backend, api] }Un service doit savoir quels pods il doit gérer. Pour cela, il utilise un selector qui cible les pods ayant des labels correspondants
Type de service - ClusterIP
apiVersion: v1
kind: Service
metadata:
name: backend-service
spec:
selector:
app: backend
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: ClusterIPPar défaut, un service Kubernetes est de type ClusterIP. Il crée une adresse IP interne accessible uniquement depuis les autres pods du cluster.
Cas d’utilisation :
- Communication entre microservices (exemple : un backend API qui interagit avec une base de données).
- Services internes non accessibles depuis l’extérieur.
Type de service - NodePort
apiVersion: v1
kind: Service
metadata:
name: backend-service
spec:
type: NodePort
selector:
app: backend
ports:
- protocol: TCP
port: 80
targetPort: 8080
nodePort: 30080Avec NodePort, Kubernetes expose le service sur un port spécifique de chaque nœud du cluster. Il devient ainsi accessible depuis l’extérieur via http://<NodeIP>:<NodePort>.
Cas d’utilisation :
- Tester un service en local avant d’utiliser un LoadBalancer.
- Exposer un service de manière simple sans configurer un équilibreur de charge.
Type de service - LoadBalancer
apiVersion: v1
kind: Service
metadata:
name: backend-service
spec:
type: LoadBalancer
selector:
app: backend
ports:
- protocol: TCP
port: 80
targetPort: 8080Le service LoadBalancer s’appuie sur l’infrastructure cloud pour exposer un service à Internet via un équilibreur de charge externe. Il répartit les requêtes entre les pods disponibles.
Cas d’utilisation :
- Exposer une API ou une application web à Internet.
- Gérer automatiquement l’équilibrage de charge pour un service critique.
Type de service - ExternalName
apiVersion: v1
kind: Service
metadata:
name: external-db
spec:
type: ExternalName
externalName: database.example.comLe type ExternalName ne crée pas de proxy réseau, mais redirige les requêtes vers un nom de domaine externe (ex: API tierce, base de données SaaS).
Cas d’utilisation :
- Connecter une application Kubernetes à un service externe (ex: une base de données gérée).
- Simplifier la configuration en utilisant un DNS interne.
Création et gestion des services Kubernetes
# Créer un service en déclaratif (ou le modifier si déjà existant)
kubectl apply -f my-service.yaml
# Créer un service en impératif
kubectl expose deployment my-app --type=ClusterIP --port=80 --target-port=8080
# Vérifier l'état des services
kubectl get services
# Inspecter un service
kubectl describe service my-service
# Supprimer un service
kubectl delete service my-service
# Lister les endpoints des services
kubectl get endpoints my-service
# Lister les pods par labels
kubectl get pods --show-labels
# Tester l'accessibilité d'un service via un Pod
kubectl exec -it my-pod -- curl my-service:80Comment accéder aux services Kubernetes ?
# Résolution DNS par défaut
# Par défaut, un service appelé backend-service dans le namespace default sera accessible via le DNS interne
backend-service.default.svc.cluster.local
# Depuis un pod situé dans le même namespace (default), il suffit d’utiliser le nom court
curl http://backend-service
# Résolution DNS entre namespaces
curl http://backend-service.autre-namespace.svc.cluster.local
# Vérifier la résolution DNS
kubectl exec -it mon-pod -- nslookup backend-service
# Sécuriser les accès aux services
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: backend-policy
spec:
podSelector:
matchLabels:
app: backend
ingress:
- from:
- podSelector:
matchLabels:
app: frontendReplicaSets
Un ReplicaSet est une ressource Kubernetes qui assure qu’un nombre défini de Pods identiques est toujours en cours d’exécution. Si un Pod est supprimé ou tombe en panne, le ReplicaSet le remplace automatiquement.
Un ReplicaSet est défini par :
-
replicas: le nombre de Pods à maintenir. -
selector: une règle permettant d’identifier les Pods gérés. -
template: le modèle de Pod utilisé pour créer de nouveaux Pods si nécessaire.
Définir un ReplicaSet
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: echo-replicaset
spec:
replicas: 3
selector:
matchLabels:
app: echo
template:
metadata:
labels:
app: echo
spec:
containers:
- name: echo-container
image: hashicorp/http-echo:0.2.3
args:
- "-text=Hello from ReplicaSet"
ports:
- containerPort: 5678Voici un exemple de ReplicaSet qui exécute une application simple basée sur hashicorp/http-echo, un serveur HTTP minimaliste qui affiche un message personnalisé.
Définir un ReplicaSet
# Déployer le ReplicaSet
kubectl apply -f replicaset.yaml
# Vérifier les pods créés
kubectl get pods -l app=echo
# Supprimer un pod pour vérifier le ReplicaSet
kubectl delete pod <podId>
# Vérifier qu'un nouveau pod a été automatiquement créé
kubectl get pods -l app=echo -w
# Gérer les ReplicaSets
# Modifier le scaling
kubectl scale rs echo-replicaset --replicas=5
# Vérifier l'état d'un ReplicaSet
kubectl get rs
# Forcer la suppression d'un ReplicaSet
kubectl delete rs echo-replicasetVoici un exemple de ReplicaSet qui exécute une application simple basée sur hashicorp/http-echo, un serveur HTTP minimaliste qui affiche un message personnalisé.
Comment mettre à jour ?
# Si vous modifier la configuration d'un ReplicaSet
containers:
- name: echo-container
image: hashicorp/http-echo:1.0.0 # Nouvelle version de l'image
# Et que vous l'appliquez de nouveau
kubectl apply -f replicaset.yamlAttention, un ReplicaSet ne gère pas les mises à jour des Pods.
Vous n'aurez que les nouveaux Pods qui seront avec la nouvelle version, les anciens ne sont pas mis à jour.
C'est pour cela que nous avons besoin des Deployments.
Les deployments : Gérer vos applications à grande échelle
Les deployments sont une abstraction essentielle de Kubernetes, conçue pour déployer et gérer vos pods de manière déclarative et automatisée.
Ils offrent des fonctionnalités avancées comme le scaling, les mises à jour progressives et la tolérance aux pannes, simplifiant la gestion de vos applications.
Pourquoi utiliser un Deployment ?
Automatisation déploiements, crée et gère les pods via les règles définies.
Mises à jour progressives : les nouvelles versions sont déployées sans interruption.
Rollback simplifié : on peut revenir rapidement à une version précédente.
Définir un Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo-server
labels:
app: echo
spec:
replicas: 3
selector:
matchLabels:
app: echo
template:
metadata:
labels:
app: echo
spec:
containers:
- name: echo-container
image: hashicorp/http-echo:0.2.3
args:
- "-text=Hello Kubernetes!"
ports:
- containerPort: 5678Un deployment est généralement défini à l’aide d’un fichier YAML. Voici un exemple de définition pour une application web défini avec le fichier mon-deployment.yaml :
Gérer les Deployments
# Déployer une application
kubectl apply -f mon-deployment.yaml
# Vérifier l'état du déploiement
kubectl get deployments
# Vérifier les replicas
kubectl get rs
# Vérifier les pods
kubectl get pods -l app=echo
# Mettre à jour un deployment
kubectl set image deployment/echo-server echo-container=hashicorp/http-echo:1.0.0Lorsqu’une mise à jour est effectuée, Kubernetes ne met pas à jour les Pods existants, mais crée un nouveau ReplicaSet. L’ancien est conservé jusqu’à ce que tous les nouveaux Pods soient prêts.
# Vérifier et suivre une mise à jour
kubectl rollout status deployment/echo-server
# Voir l'historique des mises à jour
kubectl rollout history deployment/echo-server
# Annuler une mise à jour
kubectl rollout undo deployment/echo-server
# Annuler jusqu'à une version spécifique
kubectl rollout undo deployment/echo-server --to-revision=2Gérer les Deployments - 2
# Changer le nombre de Pods
kubectl scale deployment/echo-server --replicas=5
# Supprimer un deployment
kubectl delete deployment mon-app-deploymentUn deployment Kubernetes permet de gérer les mises à jour des applications sans interruption de service. Kubernetes propose plusieurs stratégies de déploiement adaptées aux besoins de disponibilité et de contrôle des mises en production :
-
Rolling Update (Mise à jour progressive)
-
Recreate (Redémarrage total)
-
Blue-Green Deployment (Déploiement en parallèle)
-
Canary deployment (Déploiement progressif)
Les stratégies de déploiement
| Stratégie | Interruption | Facilité de rollback | Conso. de ressources |
|---|---|---|---|
| Rolling Update | Non | Oui | Standard |
| Recreate | Oui | Non | Faible |
| Blue-Green | Non | Oui (instantané) | Élevée (2 versions en parallèle) |
| Canary | Non | Oui (progressif) | Élevée (2 versions en parallèle) |
TP 3 - ReplicaSets
– Conrad Anker
TP 3 - ReplicaSets : Vérifier l’environnement
Maintenant nous allons tester les ReplicaSets, pour cela nous allons vérifier que l'environnement dev est bien celui par défaut :
kubectl get namespaces
Si non, définissez le contexte par défaut comme celui de dev :
kubectl config set-context --current --namespace=dev
Nous allons pouvoir créer notre premier ReplicaSet.
– Conrad Anker
TP 3 - ReplicaSets : Création - 1
Un ReplicaSet garantit qu’un nombre précis de Pods est toujours en cours d’exécution. Contrairement à un Déployment, il ne gère pas les mises à jour des Pods.
Créez le fichier nginx-replicaset.yml :
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-replicaset
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80– Conrad Anker
TP 3 - ReplicaSets : Création - 2
Appliquez le ReplicaSet :
kubectl apply -f nginx-replicaset.yml
Vérifiez que les Pods ont bien été créés :
kubectl get pods -n dev
Vous devriez voir 3 Pods créés, maintenant, nous allons tester la résilience du ReplicaSet, pour cela supprimez un des Pods :
kubectl delete pod <nom du pod>
Vérifiez le comportement du ReplicaSet, que s'est-il passé ?
– Conrad Anker
TP 3 - ReplicaSets : Modifier le nombre de réplicas
Nous avons besoin de plus de réplicas pour tenir la charge d'utilisation de la solution, nous allons faire passer le nombre de réplicas à 5 :
kubectl scale rs nginx-replicaset --replicas=5
Vérifiez le nombre de Pods.
Maintenant, réalisez la modification directement dans le fichier nginx-replicaset.yml pour passer à 2 réplicas.
Appliquez à nouveau et vérifiez le nombre de Pods à nouveau.
– Conrad Anker
TP 3 - ReplicaSets : Les limites
Nous avons une nouvelle version de la solution, mettez à jour l'image de nos containers :
kubectl set image rs nginx-replicaset nginx=nginx:1.23
Vérifiez les Pods, que remarquez-vous ?
Supprimez maintenant tous les anciens Pods et vérifiez à nouveau, que remarquez-vous ?
En conclusion, les modifications ne seront réalisées que sur les nouveaux Pods, c'est la limite du ReplicaSet, c'est pour cela que nous avons les Deployments pour régler ce problème.
– Conrad Anker
Exercice 1 - ReplicaSets - Scan
Installez l'outil kube-score permettant de facilement vérifier vos fichiers Kubernetes en terme de sécurité, de performance et de bonnes pratiques.
Lancez kube-score sur un fichier de pod.
Appelez-moi pour que l'on valide ensemble.
TP 4 - Deployments
– Conrad Anker
TP 4 - Deployments : Vérifier l’environnement
Dans Kubernetes, un Déployment est une ressource qui permet de gérer les mises à jour des Pods de manière contrôlée. Contrairement aux ReplicaSets, les Déployments facilitent les mises à jour progressives des applications en créant de nouveaux Pods tout en supprimant les anciens.
Nous allons vérifier à nouveau que nous sommes bien sur le contexte de dev et nous allons nettoyer les ressources des anciens TPs et exercices :
# Vérifier que l'on est sur le context dev
kubectl get namespaces
kubectl config set-context --current --namespace=dev
# Nettoyez les ressources des anciens TPs / Exercices
kubectl get all
kubectl delete <ressource> <name>– Conrad Anker
TP 4 - Deployments : Création d'un Deployment
Créez un fichier nginx-deployment.yml :
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80Puis appliquez le déploiement et vérifiez la création des Pods.
– Conrad Anker
TP 4 - Deployments : Tester la résilience du déploiement
Supprimez un Pod :
kubectl delete pod <nom du pod>
Vérifiez vos Pods, que remarquez-vous ?
Maintenant, essayons à nouveau d'augmenter le nombre de Replicas :
kubectl scale deployment nginx-deployment --replicas=5
Vérifiez à nouveau vos Pods, que remarquez-vous ?
Essayez à nouveau en modifiant le nombre à 2 replicas dans votre fichier directement, appliquez et vérifiez les changements.
– Conrad Anker
TP 4 - Deployments : Mise à jour progressive
Maintenant, nous allons vérifier qu'un déploiement met à jour progressivement une nouvelle image sur nos containers.
Modifiez l'image utilisée par le Deployment :
kubectl set image deployment/nginx-deployment nginx=nginx:1.23
Suivez la mise à jour des Pods :
kubectl rollout status deployment nginx-deployment
Vérifiez vos Pods et l'image de votre déploiement actif :
kubectl get pods -n dev
kubectl describe deployment nginx-deployment | grep Image
– Conrad Anker
Exercice 1 - Deployments - Tester un rollback
Nous allons maintenant essayer un cas d'erreur et faire notre premier rollback.
Changer l'image de nginx dans le fichier .yml pour y mettre une version qui n'existe pas "nginx:test" par exemple.
Vérifiez le comportement de Kubernetes en suivant la mise à jour, en vérifiant les Pods et en annulant votre déploiement (Rollback).
Appelez-moi pour que l'on valide ensemble.
TP 5 - Services
– Conrad Anker
TP 5 - Services : Vérifier l’environnement
Dans Kubernetes, un Service est une ressource qui permet de découvrir et d’accéder aux applications déployées dans un cluster. Il assure la communication entre les Pods et expose les applications de manière stable et sécurisée.
Vérifiez que vous avez toujours votre déploiement en cours d'exécution, sinon ré-appliquez le déploiement du TP précédent.
– Conrad Anker
TP 5 - Services : Création d'un service ClusterIP
Un Pod a une IP interne éphémère, ce qui empêche d’autres Pods d’y accéder de manière stable. Un ClusterIP permet d’attribuer une IP fixe pour rendre l’application accessible aux autres Pods du cluster. Créez le fichier nginx-clusterip-service.yml :
apiVersion: v1
kind: Service
metadata:
name: nginx-clusterip-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80Puis appliquez le service et vérifiez les services disponibles :
kubectl get services
– Conrad Anker
TP 5 - Services : Tester l'accessibilité
Nous allons maintenant vérifier qu'un autre Pod puisse accéder à notre service nginx-clusterip-service, créez un nouveau Pod pour tester :
kubectl run test-pod --image=busybox --restart=Never -- sleep 3600
Lancez un terminal dans ce Pod :
kubectl exec -it test-pod -- sh
Testez la connexion à notre service :
wget -qO- http://nginx-clusterip-service
Vous devriez avoir la page d'accueil de Nginx.
– Conrad Anker
TP 5 - Services : Exposition en dehors du Cluster
Supprimons l'ancien Pod et Service :
kubectl delete pod test-pod
kubectl delete -f nginx-clusterip-service.yaml
Créez le fichier nginx-nodeport-service.yml :
apiVersion: v1
kind: Service
metadata:
name: nginx-nodeport-service
spec:
type: NodePort
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30007 # Doit être entre 30000 et 32767– Conrad Anker
TP 5 - Services : Exposition en dehors du Cluster
Appliquez le service et utilisez la commande :
minikube service nginx-nodeport-service
Il est possible que vous ayez besoin d'utiliser -n si vous avez réaliser le service dans un namespace spécifique.
Testez l'accès à l'application depuis votre machine en suivant les instructions dans votre terminal.
Vous devriez avoir la page d'accueil de Nginx.
Appelez-moi pour que l'on puisse valider ensemble.
Exercices
– Conrad Anker
Exercice 1 - Pong
Déployez votre première image Pong avec Kubernetes via Minikube.
Appelez-moi pour que l'on valide ensemble.
– Conrad Anker
Exercice 2 - E-commerce
Déployez votre infrastructure d'E-commerce que vous avez réalisé en Docker Compose précédemment en Kubernetes via Minikube avec les services nécessaire pour accéder au Frontend de votre solution.
Appelez-moi pour que l'on valide ensemble.