Intégration
Continue
Computers perform repetitive tasks; People solve problems.
Accelerate, Forsgren PhD.
Master Expert Technologie de l'information EPITECH 2020.
Co-fondateur et CTO d'une startup dans l'Edtech 2019 - fin 2022. (+3 ans)
Formation PSPO-1 Agile Scrum 2022.
Co-fondateur et CTO d'une startup dans la Deeptech fin 2022 - aujourd'hui.
Valentin MONTAGNE

Déroulement du cours
1
Fondamentaux de l'intégration continue
3
Stratégies de déploiement avec CI / CD
2
Mise en pratique
4
QCM de fin de module et rendu des TPs et exercices
Chaque séance débutera par la présentation d'un concept et de l'intérêt d'utilisation de celui-ci.
1
Théorie
Après la théorie, nous verrons alors la pratique en réalisant des exercices.
2
Pratique
Nous verrons ensemble la correction des travaux pratiques. N'hésitez pas à poser vos questions.
3
Correction
Déroulement des journées
Connaissez-vous l'intégration continue ?
Rendu TP et exercices
Pour faciliter le rendu final des TPs et exercices, vous allez créer un dépôt sur Github avec le nom intégration-continue en publique et le cloner sur votre machine.
Si vous préférez le garder en privé, vous devez m'ajouter avec les droits pour voir votre dépôt avec le nom d'utilisateur :
Github :
ValentinMontagne
Gitlab :
vm-marvelab avec le rôle Developer.
Fondamentaux de l'intégration continue
1.
Qu'est-ce que Git ?
Créé par Linus Torvalds en 2005 à cause du passage de BitKeeper en payant.
Un système de gestion de version décentralisé simple et performant.
Indexe les fichiers d'après leur somme de contrôle calculée avec la fonction de hachage SHA‑1



Pourquoi utiliser Git ?
Fonctionnement en miroir, permet de collaborer sur des projets complexes comme le noyau linux.
Git est Open Source et gratuit ce qui permet d'être très fiable.
Des workflows non-linéaire pour collaborer même en asynchrone.

Git - Les basiques
Dépôt (Repository)
Un emplacement de stockage pour le code et la documentation de votre projet. Il permet à plusieurs personnes de travailler sur le même projet sans écraser le travail des autres.
Commit
Une sauvegarde de vos progrès, un instantané de l'état actuel de votre projet.
Staging
Sert d'étape intermédiaire entre les modifications apportées au dépôt local et le commit. Permet de prévisualiser les modifications avant de les valider.
.gitignore
Permet d'ignorer certains fichiers et dossiers qui n'ont pas à être dans les versions du projet. (Par exemple, node_modules)
Git - Les basiques
# Clone Git Repository
git clone [URL]
# Managing remotes
git remote add [name] [url]
git remote -v
git remote rename [old-name] [new-name]
git remote remove [name]
# Show changes (staging)
git status
# Pushing / Pulling Changes
git push [remote] [branch]
git pull [remote] [branch]
# Only sync with remote without apply changes.
git fetch [remote] [branch]
# Branching
git checkout -b [branch-name] // Short for : git branch iss53 && git checkout iss53
# Example of commit
git commit -am 'Create new footer [issue 53]'
# Merge branch to main
# Go to the branch called main.
git checkout main
git merge [branch-name]
# Delete branch
git branch -d [branch-name]Git - Stratégie de merge
git merge
Avantages - préservation de l'historique et chronologique, maintien d'un contexte distinct pour les branches, facile à comprendre et à reverse.
Inconvénients - Crée des commits de fusion supplémentaires, peut rendre l'historique encombré.
git rebase
Avantages - Crée un historique linéaire et propre, facilite le suivi du développement des fonctionnalités, évite les commits de fusion.
Inconvénients - Réécrit l'historique*, plus complexe pour résoudre les conflits, peut être dangereux s'il n'est pas utilisé avec précaution.
Git - Stratégie de merge
git merge --squash
Avantages - Combine tous les changements en un seul commit, historique de la branche principale très propre, revues de code plus faciles, bon pour les branches de fonctionnalités.
Inconvénients - Perte de l'historique détaillé des livraisons, difficulté à debug des modifications spécifiques, impossibilité de revenir facilement sur des modifications individuelles, perte des messages de livraison individuels.
Git - Stratégie de merge
Cas d'utilisation courants
git merge : Les branches de fonctionnalités sont fusionnées dans la branche principale, en préservant l'historique.
git rebase : Branches locales avant de push, gardant les branches de fonctionnalités à jour.
git merge --squash : Branches de fonctionnalités de courte durée, PR merges où les commits atomiques ne sont pas importants.
Bonnes pratiques
- Ne jamais rebase les branches publiques/partagées car cela demande un force push.
- Utiliser le squash pour les petites fonctionnalités à but unique.
- Maintenir des messages de commit clairs quelle que soit la stratégie.
Git - Avancé
# In case of errors made with bad merges (rebase errors, bad conflicts...)
# Display all the history of git commands / actions.
git reflog
65c4afa (HEAD -> main) HEAD@{0}: commit: fix(web): issue with library, tags visualizations
541a8fb HEAD@{1}: reset: moving to HEAD
541a8fb HEAD@{2}: reset: moving to HEAD
541a8fb HEAD@{3}: pull origin main (finish): returning to refs/heads/main
541a8fb HEAD@{4}: pull origin main (pick): feat(web): adding about in database column, improving main column display and fix block scroll issue
d0863d2 (tag: v0.9.0-alpha.6) HEAD@{5}: pull origin main (start): checkout d0863d2bb13360bf822951b17986f2264d32371a
ececa4c HEAD@{6}: commit: feat(web): adding about in database column, improving main column display and fix block scroll issue
9a26949 HEAD@{7}: reset: moving to HEAD
9a26949 HEAD@{8}: reset: moving to HEAD
# Pick a hash and go to your deleted commit.
git checkout ececa4c
# Necromancy done!Qu'est-ce que l'intégration continue ?
Intégration fréquente des changements au code source pour éviter les régressions.
Automatiser pour éviter les erreurs humaines et la pénibilité de tâche répétitive.
Utilise une pipeline avec différentes étapes pour vérifier la qualité des changements.

Le principe de non-regression
La régression est un type de bug, une fonctionnalité déjà présente et fonctionnel dans la solution n'est maintenant plus utilisable.
Un autre type de régression que la régression fonctionnelle existe, on l'appelle la régression de performance. Plus précisément, la fonctionnalité consomme maintenant bien plus de ressources pour fonctionner.
C'est un principe fondamental du développement d'éviter les bugs et les régressions.
Par exemple en Agilité, chaque itération du produit doit développer le produit, jamais diminuer involontairement sa qualité ou ses fonctionnalités.
Pourquoi utiliser l'intégration continue ?
Itérer rapidement, apprendre rapidement.

Lean, Agile, Hypothesis driven.
Garder un produit fonctionnel car le déploiement est automatisable avec le Cloud as a service.



Lean, Agile...
Beaucoup de méthode de gestion d'entreprise, de projet ou de produit se base sur une itération continue où l'apprentissage est la clé.
Lean et Agile
Google Design Sprint
Grâce au Sprint Design, Google est capable de tester une nouvelle fonctionnalité en 5 jours ouvrés.
Course à l'itération !
Pour cela, les équipes ont besoin de méthodes pour éviter les régressions et augmenter la rapidité des livraisons.
Scientifiquement prouvé
Corrélation entre les performances et le bien-être au travail avec le CI / CD et le Lean
Computers perform repetitive tasks; People solve problems.
Key Indicators
- Delivery lead time
- Deployment frequency
- Time to restore service
- Change fail rate
DORA - DevOps Status
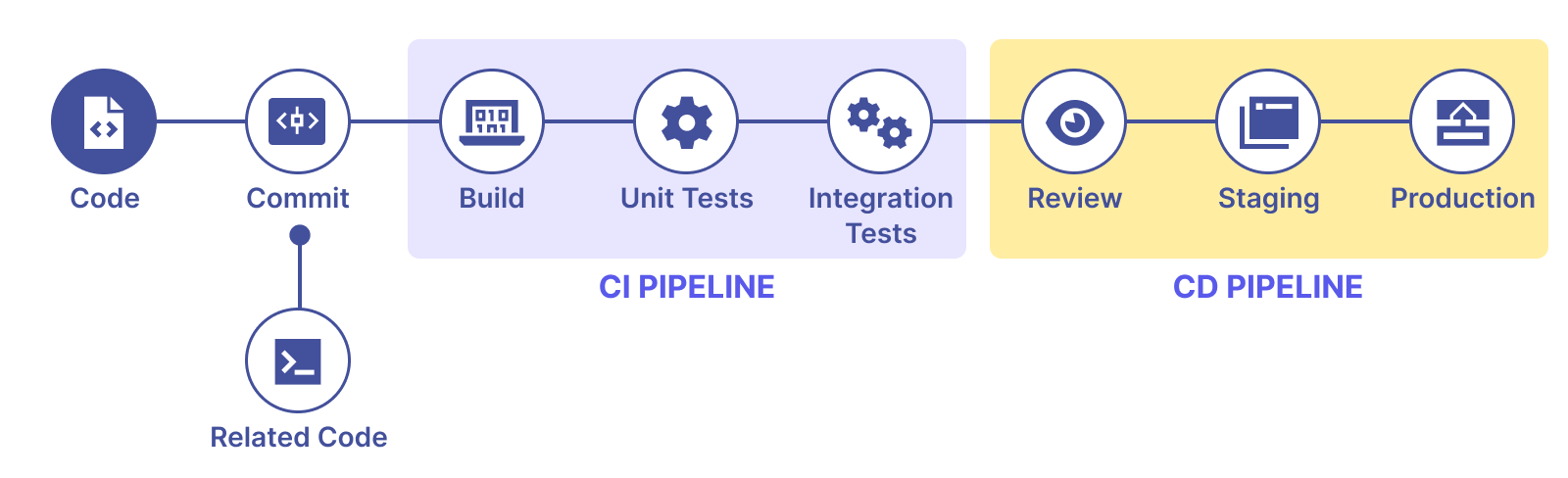
Le Workflow en CI / CD
Pourquoi se soucier de la qualité ?
Protéger l'entreprise d'incidents techniques
Créer un lien de confiance et garder les utilisateurs
Augmenter la productivité et le bien-être des équipes techniques



Pourquoi automatiser l'intégration ?
Réduire le temps et le coût de la validation des changements.
Les tâches pénibles et répétitives sont facilement ignorées.
Éviter les régressions à la source au lieu de les corriger après déploiement.


Git Workflows - Git Flow

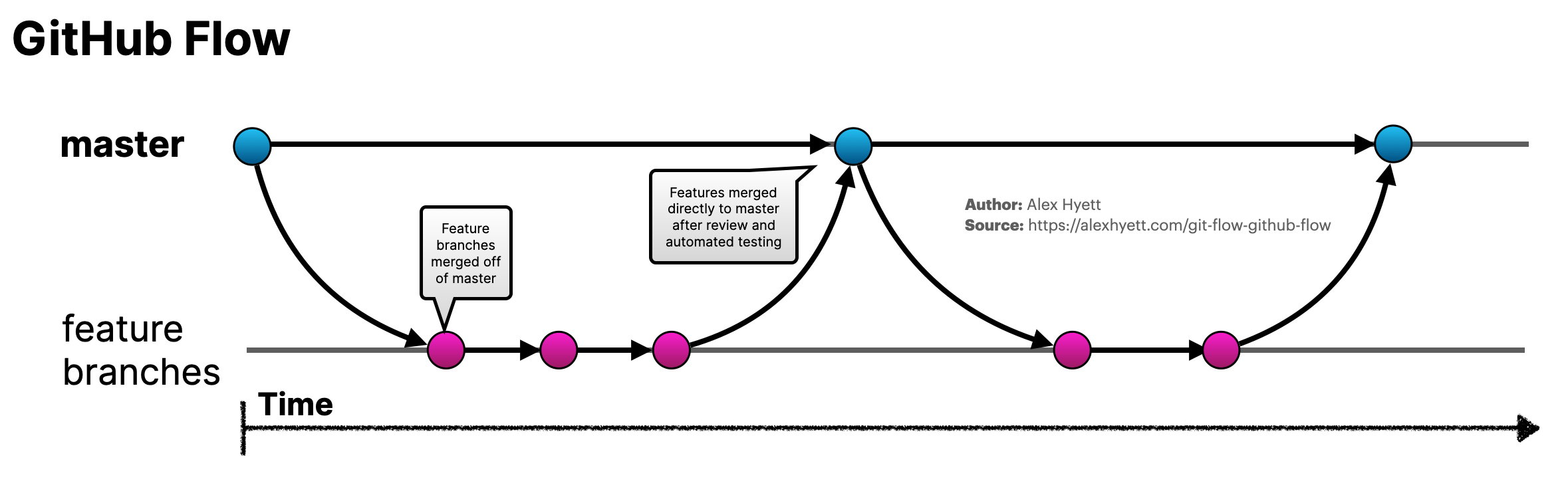
Git Workflows - Github Flow
Git Workflows - Trunk-based Development
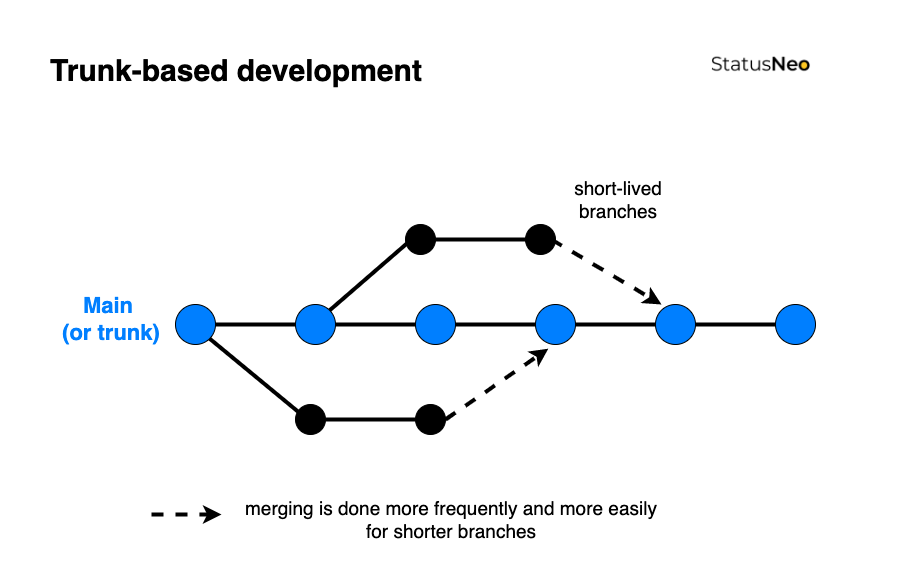
Git Workflows - Trunk-based Development
Le but ici est de ne créer des branches seulement pour réaliser une Pull Request et qui ne doit vivre au maximum qu'un jour.
L'objectif de la méthode est de merge au moins une fois par jour et la branche principale (Le tronc) doit être déployé à tout moment.
Une Pull Request est une proposition de merge d'une branche dans une autre en affichant les changements entre les deux. C'est un outil de collaboration pour permettre la revue du code.
Git Workflows
Git Flow
Avantages - bien pour les projets complexes, séparation claire des versions, des fonctionnalités, des correctifs, bon pour la gestion de versions multiples.
Inconvénients - Complexe et lourd, cycles de déploiement plus lents, plus de merge conflicts.
Github Flow
Parfait pour les projets où la collaboration se fait de manière lente et asynchrone et très simple. (Open Source)
Trunk-Based Development
Avantages - Workflow le plus simple, cycles d'intégration rapides, réduction des merge conflicts, idéal pour CI/CD, boucle de feedback rapide.
Inconvénients - CI / CD obligatoire et automatisé.
Git Workflows
En résumé :
Git Flow
Grands projets, versions multiples.
GitHub Flow
Applications Web simple, projet open source, déploiement continu.
Trunk-Based Development
Équipes modernes avec CI/CD solide, microservices.
Les outils - Git Hooks
Les hooks sont des scripts qui s'exécutent automatiquement à des moments précis du Workflow Git, par exemple lors d'un commit, pull ou push des modifications d'un dépôt. Ces scripts peuvent être utilisés pour effectuer diverses tâches, comme la validation du code, le formatage des fichiers ou même l'envoi de notifications.
Il existe deux types de hooks Git :
Côté client : Ils sont exécutés sur votre machine locale avant d'effectuer des modifications.
Côté serveur : Ils sont exécutés sur le serveur distant lorsque vous transférez des modifications.
Nous allons utiliser cet outil côté client pour éviter qu'un développeur ne commit du code qui n'est pas validé par notre CI.
Les outils - Jenkins
Créé par Kohsuke Kawaguchi en 2011 avec Oracle car réalisé en Java.
Open source, s'interface avec des systèmes de versions comme Git.
Automatise le build, les tests et le déploiement.
Les outils - Gitlab CI
Créé par Gitlab Inc. en 2014, open source avec une version Entreprise.
Solution tout-en-un du CI / CD avec gestion des issues et pipelines liés aux projets.
Permet d'héberger une version de Gitlab directement sur les serveurs de l'entreprise.


Les outils - Github Actions
Après l'impulsion du rachat par Microsoft, créations de la partie Actions de Github en 2018.
Leader dans le stockage de dépôt de code et développement de projet Open Source, grande communauté.
Plus limité que Gitlab CI sur la partie DevOps / Docker.



Des questions ?
Mise en pratique
2.
Comment fonctionne Gitlab ?
Gitlab utilise le fichier à la racine de votre dépôt .gitlab-ci.yml qui contient toutes les instructions pour votre pipeline CI / CD. Lors d'évènement comme un commit ou une pull request (ou merge request), la pipeline s'execute grâce à des runners.
Les runners peuvent être hébergé par l'équipe (personnalisé) ou directement par Gitlab (partagé). Ils s'executent sur des machines physiques, virtuelles ou des conteneurs Docker.
# .gitlab-ci.yml File
# Configure the global image and cache for every stage
image: node:latest
cache:
key:
files:
- package-lock.json
paths:
- node_modules/
- .npm/
# Define all the stages used for the pipeline
stages:
- validate
- test
- build
- release
- deploy
# Add first job using the '.pre' stage defined by Gitlab, could be a defined stage too
# .pre is always run as the first stage
install:
stage: .pre
script:
# define cache dir & use it npm!
- npm ci --cache .npm --prefer-offline
Exemple de Pipeline CI / CD
Des questions ?
TP - Auth API
Gitlab CI
Création d'une pipeline CI
Création du compte Gitlab
Si vous n'avez pas encore de compte Gitlab, je vous invite pour la suite du TP et des exercices à créer un compte avec votre adresse étudiante.
Récupérer le projet de base
Maintenant que vous avez un compte Gitlab, vous pouvez "Fork" directement le projet ou le cloner sur votre machine et créer un nouveau projet vide pour récupérer le contenu du projet de base pour réaliser ce TP :
https://gitlab.com/vm-marvelab/ci-cd
(Tous les fichiers sont à mettre à la racine de votre dépôt.)
Auth API
Le projet de base est une API très simple en NodeJS, elle utilise Express pour lancer un serveur qui écoute les requêtes sur des routes définies.
N'hésitez pas à lire le README pour comprendre comment fonctionne la route /auth.
Utilisez la commande pour installer les dépendances du projet :
npm install
Ensuite utilisez la commande pour lancer l'API :
npm start
Configuration pipeline CI - 1
Maintenant que notre projet de base fonctionne, nous allons commencer à intégrer notre pipeline CI.
Pour cela, créez à la racine du projet le fichier .gitlab-ci.yml
N'hésitez pas à installer une extension sur votre IDE pour vous aider avec le format du fichier.
Passons à la prochaine étape.
Configuration pipeline CI - 2
Nous devons spécifier avec quel image notre Runner doit s'executer pour lancer notre pipeline CI, étant une API en nodejs, nous allons utiliser une image nodejs.
Nous allons ajouter des informations sur le cache pour éviter qu'à chaque Job de chaque Stage que nous soyons obliger de réinstaller les dépendances.
# .gitlab-ci.yml file
image: node:latest
cache:
key:
files:
- package-lock.json
paths:
- node_modules/
- .npm/
Configuration pipeline CI - 3
Comme vu ensemble, un Job est une étape spécifique du processus, comme exécuter des tests, compiler du code, ou déployer une application. Un job peut être configuré avec des scripts, des environnements d'exécution, et des conditions spécifiques (par exemple, quand il doit être exécuté). Plusieurs jobs peuvent s'exécuter en parallèle ou en séquence, en fonction des dépendances et de la structure du pipeline.
Un Stage est un groupe de Job et permet d'organiser la pipeline, ils s'exécutent dans l'ordre dont ils sont définis.
Configuration pipeline CI - 4
Définissons nos Stages et réalisons notre premier Job qui sera l'installation des dépendances à la suite du fichier :
stages:
- validate
- test
- build
- release
- deploy
install:
stage: .pre
script:
# define cache dir & use it npm!
- npm ci --cache .npm --prefer-offline
Ici le stage .pre est un Stage déjà créé par Gitlab, il est obligatoirement le premier à être lancé.
Nos Stages sont les étapes habituelles d'une pipeline de CI / CD.
Configuration pipeline CI - 5
Une fois ajouté, réaliser un git commit et un git push pour envoyer les changements à votre dépôt sur Gitlab.
Une fois fait, allez dans la section Build dans la barre à gauche du dépôt sur gitlab.com et cliquez sur Pipelines, il n'y a pas encore de Pipeline lancée, c'est parce que nous n'avons pas encore de Job hors installation.
Passons à l'étape suivante pour réaliser notre Stage validate.
Configuration pipeline CI - 6
Ajoutons maintenant le Stage de validation, pour cela nous allons ajouter les outils Eslint pour vérifier la qualité de notre code NodeJS :
npm init @eslint/config@latest
Choisissez les options "Style et problems", puis "CommonJS", "None of these", "No" pour Typescript et cochez "Node".
Un nouveau fichier eslint.config.mjs est apparu, passons à l'étape suivante.
Configuration pipeline CI - 7
Changez la configuration du fichier pour ignorer les fichiers de tests et ajouter des règles comme ici ne pas avoir de variables inutilisés, de variable non défini ou de console.log dans le code.
// eslint.config.mjs
import globals from "globals";
import pluginJs from "@eslint/js";
export default [
{
ignores: ["**/*.test.js"],
files: ["**/*.js"],
languageOptions: { sourceType: "commonjs" },
},
{ languageOptions: { globals: globals.node } },
pluginJs.configs.recommended,
{
rules: {
"no-unused-vars": "error",
"no-undef": "error",
"no-console": "error",
},
},
];
Configuration pipeline CI - 8
Ajoutons maintenant le script "lint" au package.json pour pouvoir lancer la commande :
npm run lint
// package.json
// ...
"scripts": {
"start": "node src/index.js",
"lint": "eslint src --max-warnings=0"
},
// ...
Configuration pipeline CI - 9
Ajoutons maintenant un console.log que l'on a "oublié" dans une route de notre API dans le fichier index.js qui affiche la variable secret et qui ne devrait pas être dans nos logs !
const express = require("express");
const auth = require("./modules/authentication");
const app = express();
const port = process.env.PORT || 3000;
app.get("/", (req, res) => {
res.send("Hello World!");
});
app.get("/auth/:secret", (req, res) => {
const { secret } = req.params;
const response = auth(secret);
console.log(secret);
res.status(response.status).send(response.message);
});
app.listen(port, () => {
// eslint-disable-next-line no-console
console.log(`Example app listening on http://localhost:${port}`);
});
Configuration pipeline CI - 10
Lancez la commande npm run lint vous devriez maintenant avoir une erreur.
Ajoutons maintenant un Job dans notre pipeline CI pour lancer cette commande automatiquement. A la suite du fichier .gitlab-ci.yml, ajoutez le Job lint dans le Stage validate.
// .gitlab-ci.yml
// ...
install:
stage: .pre
script:
# define cache dir & use it npm!
- npm ci --cache .npm --prefer-offline
lint:
stage: validate
script:
- npm run lint
Configuration pipeline CI - 11
Faites un nouveau commit et faites un push sur la branch main à nouveau et retournez voir les Pipelines de votre dépôt pour voir le résultat.
La même erreur est détecté automatiquement par votre CI maintenant. Enlevez le console.log et faites de nouveau un push pour corriger le problème.
Mais cela serait plus fiable si l'on détectait ce genre de problème avant qu'il n'arrive sur notre pipeline non ?
Mettons en place notre Git hooks à l'étape suivante.
Installation des Git hooks - 1
Maintenant nous allons installer Husky à notre projet, qui permet de mettre en place les Git hooks pour nous permettre d'executer notre validation ou nos tests avant chaque commit. Cela rentre totalement dans l'intégration continue pour éviter de commit du code qui n'est pas fonctionnel ou de mauvaise qualité.
Lancez la commande :
npm install --save-dev husky && npx husky init
Husky génère alors un dossier .husky, ouvrez le fichier pre-commit dans ce dossier et changez npm test par npm run lint.
Installation des Git hooks - 2
Essayez de commit, vous allez maintenant avoir npm run lint qui s'execute automatiquement. Essayez d'oublier à nouveau un console.log dans le code, lors de la tentative de commit vous devriez être bloqué par l'echec de la commande npm run lint.
Maintenant ajoutons les tests à notre pipeline à l'étape suivante.
Ajout des tests - 1
Pour réaliser l'étape des tests, nous allons installer Vitest :
npm install -D vitest
Ensuite, ajoutons dans package.json la commande "test".
// package.json
// ...
"scripts": {
"start": "node src/index.js",
"lint": "eslint src --max-warnings=0",
"prepare": "husky",
"test": "vitest run"
},
"devDependencies": {
// ...
Vérifiez que tout est fonctionnel avec la commande :
npm test
Ajoutez ensuite cette commande au Git hooks.
Ajout des tests - 2
Ensuite, ajoutons notre Job unit-test qui sera dans notre Stage test.
// .gitlab-ci.yml
// ...
install:
stage: .pre
script:
# define cache dir & use it npm!
- npm ci --cache .npm --prefer-offline
lint:
stage: validate
script:
- npm run lint
unit-test:
stage: test
script:
- npm test
Faites un push à nouveau et vérifiez que le job apparait bien dans votre pipeline et qu'il lance les tests.
Variables d'environnement et Rules - 1
Nous allons maintenant permettre de release une version de notre API via notre Pipeline. Ce Job doit alors être manuel pour nous laisser la possibilité d'activer la release au bon moment.
Par sécurité nous allons ajouter des Rules pour éviter que le Job Release se lance sur d'autres branches que main.
Pour créer une nouvelle version nous allons utiliser Release-it :
npm init release-it
Choisissez les réponses "Yes" et "package.json" à l'installation.
Variables d'environnement et Rules - 2
Ajoutez dans le package.json dans le champ "release-it" les informations "git" suivantes :
Voir à l'étape suivante l'ajout au .gitlab-ci.yml du Stage Release.
// package.json
// ...
"dependencies": {
"express": "^4.18.2"
},
"release-it": {
"$schema": "https://unpkg.com/release-it/schema/release-it.json",
"gitlab": {
"release": true
},
"git": {
"commitMessage": "chore: release v${version}"
}
}
// ...Variables d'environnement et Rules - 3
// .gitlab-ci.yml
// ...
unit-test:
stage: test
script:
- npm test
release:
stage: release
when: manual
rules:
- if: '$CI_COMMIT_BRANCH == "main"
&& $CI_COMMIT_TAG == null
&& $CI_COMMIT_TITLE !~ /^chore: release/'
before_script:
- git config user.email $GITLAB_USER_EMAIL
- git config user.name $GITLAB_USER_NAME
- git remote set-url origin
"https://gitlab-ci-token:$GITLAB_TOKEN@$CI_SERVER_HOST/$CI_PROJECT_PATH.git"
- git checkout $CI_COMMIT_BRANCH
- git pull origin $CI_COMMIT_BRANCH --rebase
script:
- npx --yes release-it --ciVariables d'environnement et Rules - 4
// Permet de spécifier que ce Job sera activé manuellement.
when: manual
// Permet d'ajouter des rules au Job pour l'afficher ou non grâce au if.
// Ici le commit doit être sur la branche main, cela ne doit pas être un tag
// et le title du commit doit être différent de ce format.
rules:
- if: '$CI_COMMIT_BRANCH == "main"
&& $CI_COMMIT_TAG == null
&& $CI_COMMIT_TITLE !~ /^chore: release/'Quelques explications :
Variables d'environnement et Rules - 5
Ensuite, pour fonctionner, Release-it a besoin d'une variable d'environnement GITLAB_TOKEN. Pour cela nous allons devoir l'ajouter manuellement, mettez votre souris sur Settings et cliquez sur CI / CD, ensuite ouvrez le menu Variables. Ouvrez sur une autre page vos Access Tokens en mettant votre souris sur votre profil en haut à gauche, puis en cliquant sur Préférences, là vous devez cliquer sur Access Tokens et générer un nouveau Token avec les droits api.
Ajoutez ce token dans une nouvelle variable CI / CD de votre projet GITLAB_TOKEN.
Faites un push et lancez la release.
Appelez-moi quand vous avez terminé pour que l'on valide ensemble le TP.
Exercice 1 - Retirez des étapes
Nous avons un problème, ici après la release, deux pipelines se lancent, cela est inutile.
Vous devez retirer les étapes validate et test en ajoutant des rules aux Jobs pour qu'ils ne se lancent pas lorsqu'un tag est créé ou que le commit est le commit de release "chore: release".
Appelez-moi pour que l'on puisse valider ensemble.
Documentation :
Exercice 2 - Ajouter une étape
Préparons un nouveau Job e2e-test dans le Stage test, pour l'instant il ne doit juste réaliser la commande suivante :
echo "Hello E2E !"
Il doit être visible uniquement dans les Merge Requests (Pull Requests).
Appelez-moi pour que l'on puisse valider ensemble.
Exercice 3 - Ajouter une variable d'environnement
Préparons un nouveau Job only-canary dans le Stage validate, qui ne doit se lancer que quand l'on lance la pipeline pour l'environnement Canary, pour cela, nous allons créer une variable d'environnement "ENV_TARGET" qui doit être égale à "canary" pour que le Job se lance.
Pour l'instant il ne doit juste réaliser la commande suivante :
echo "Hello Only Canary !"
Appelez-moi pour que l'on puisse valider ensemble.
Documentation :
Exercice 4 - Ajouter des dépendances
Préparons un nouveau Job integration-test dans le Stage test, qui ne doit se lancer que quand le Job unit-test réussi, de même pour e2e-test qui ne doit maintenant se lancer que quand integration-test réussi.
Pour l'instant il ne doit juste réaliser la commande suivante :
echo "Hello Integration !"
Appelez-moi pour que l'on puisse valider ensemble.
Documentation :
Exercice 5 - Enlevons la duplication de code
Durant les derniers exercices, nous avons souvent appliqué le même comportement à plusieurs Jobs. Pour éviter la duplication de code et que le fichier soit plus maintenable, utilisons les Anchors en YAML pour pouvoir faire hériter à nos Jobs une configuration.
Appelez-moi pour que l'on puisse valider ensemble.
Github Actions
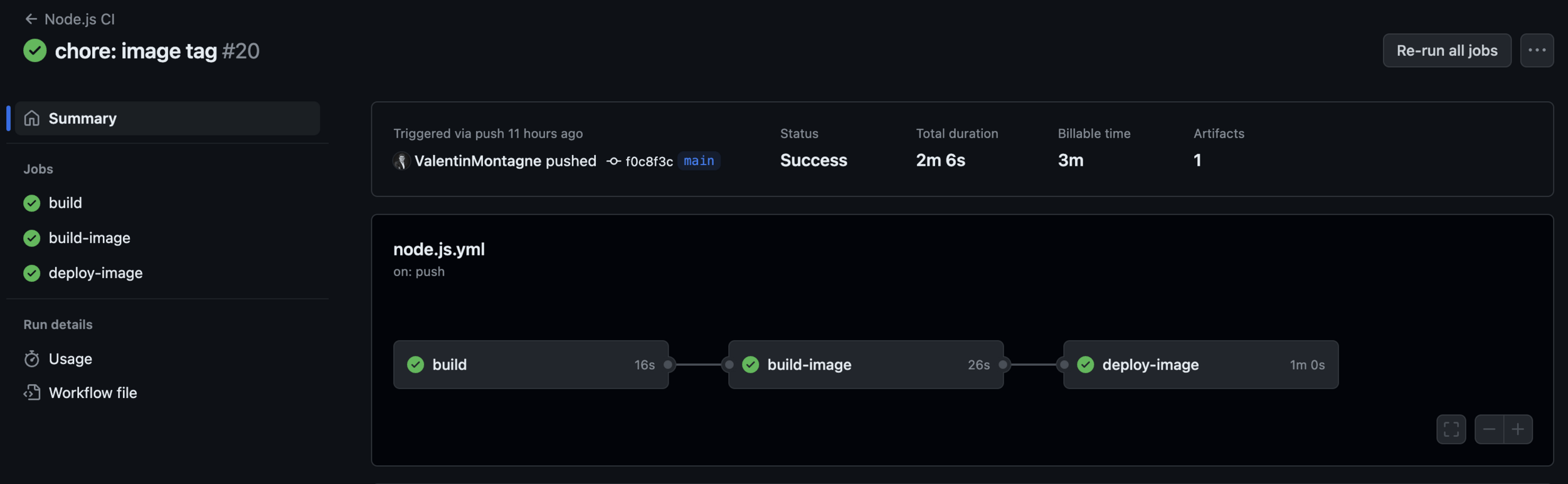
Découvrons ensemble Github Actions, pour cela nous allons recommencer ce TP en utilisant uniquement Github.
Je vous invite à créer un compte Github si ce n'est pas déjà le cas pour la suite du TP.
Validation et tests
name: Node.js CI
on:
push:
branches: ['main']
pull_request:
branches: ['main']
jobs:
build:
runs-on:
ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v3
with:
node-version: ${{ matrix.node-version }}
cache: 'npm'
- name: Install
run: npm ci --cache .npm --prefer-offline
- name: Validate
run: npm run lint
- name: Test
run: npm test
- name: Build for production
run: npm run build
- uses: actions/upload-artifact@master
with:
name: web
path: ./distTP - Auth API
Github Actions
Github Actions
Maintenant que vous êtes plus à l'aise avec l'intégration continue, vous serez en autonomie, suivez la documentation https://docs.github.com/fr/actions pour réaliser le même TP qu'avec Gitlab CI.
N'hésitez pas à m'appeler en cas de problème.
Exercice - Ajouter un build avec artefact
Préparons un nouveau Job build dans le Stage build, qui doit lancer le build de votre projet personnel (build le HTML dans un dossier /dist, une image Docker ou autre).
Le but ensuite est de stocker le résultat soit comme artefact si build HTML par exemple ou dans un Registry pour une image Docker.
Appelez-moi pour que l'on puisse valider ensemble.
Exercice Bonus - Créer votre propre pipeline CI sur un projet à vous
Rien de mieux que de tester ses connaissances sur un cas réel.
Récupérer un ancien projet à vous et tenter d'y ajouter une pipeline d'intégration continue avec l'outil de votre choix.
Appelez-moi pour que l'on puisse valider ensemble.
Stratégies de déploiement avec CI / CD
3.
Qu'est-ce que le déploiement continu ?
Le code est déployé après chaque modification.
Au vu de la fréquence, on automatise alors le déploiement.
Plusieurs stratégies de déploiement existent. (Blue / Green, Feature Flag, Canary...)

Pourquoi utiliser le déploiement continu ?
Gérer correctement les différents environnements de la solution.
Identifier et corriger rapidement les bugs et régressions.
Améliorer la stabilité de la solution et revenir rapidement à la version d'avant.



Externaliser son infrastructure
Automatiser et monitorer le déploiement des applications
Cloud as a service
Code as Infrastructure
Définir toute son infrastructure via des fichiers de configuration.
Automatiser la création, l'édition et la suppression des ressources de l'infrastructure dans le cloud.
Suivre les différentes versions de l'infrastructure en fonction de la solution.


Automatise le déploiement sur tous les grands Clouds.
Est capable de gérer des grands cluster avec Kubernetes.
S'intègre facilement dans les pipelines CI / CD.

Terraform a été mis en open-source en 2014 sous la Mozilla Public License (v2.0).
Puis, le 10 août 2023, avec peu ou pas de préavis, HashiCorp a changé la licence pour Terraform de la MPL à la Business Source License (v1.1), une licence non open source.
OpenTofu est un fork de la version Open source de Terraform et est géré par la fondation Linux. C'est donc une bonne alternative à Terraform aujourd'hui.
La migration à OpenTofu est extrêmement simple car il n'y a pas de différence de fonctionnement avec Terraform.
Exemple avec Github Actions, Docker et Terraform - 1
build-image:
runs-on: ubuntu-latest
needs: build
steps:
- uses: actions/checkout@v3
- uses: actions/download-artifact@master
with:
name: web
path: ./dist
- name: Set up QEMU
uses: docker/setup-qemu-action@v3
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Login to Docker Hub
uses: docker/login-action@v3
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
- run: ls
- name: Build and push
uses: docker/build-push-action@v5
with:
context: .
push: true
tags: valentinmontagne/nginx-web-example:latest
# ${{ github.sha }}Exemple avec Github Actions, Docker et Terraform - 2
deploy-image:
runs-on: ubuntu-latest
needs: build-image
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_DEFAULT_REGION: eu-west-3
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Setup Terraform
uses: hashicorp/setup-terraform@v1
with:
cli_config_credentials_token: ${{ secrets.TF_API_TOKEN }}
- name: Terraform Init
run: terraform init
- name: Terraform Format
run: terraform fmt -check
- name: Terraform Plan
run: terraform plan -input=false
- name: Terraform Apply
run: terraform apply -auto-approve -input=false
# Add condition here to avoid to deploy when checking a PR.Exemple avec Github Actions, Docker et Terraform - 3
Pour réaliser le déploiement continue, nous utilisons les fichiers de configuration pour Terraform suivants :
1. Main - permet de définir les ressources à créer côté Cloud.
2. Variables - permet de définir des variables qui peuvent changer en fonction de la stratégie de déploiement comme le type de serveur à créer.
Stratégies de déploiement
Blue / Green
Feature Flag
Canary



1. Comment déployer fréquemment sans interrompre les utilisateurs ?
2. Comment déployer fréquemment sans bugs ou régressions pour les utilisateurs ?
3. Comment tester les changements avec de vrais utilisateurs ?
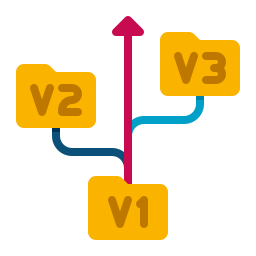
Stratégie Blue / Green
On crée deux environnements distincts mais identiques. Un environnement (Blue) exécute la version actuelle de l'application et un environnement (Green) exécute la nouvelle version de l'application.
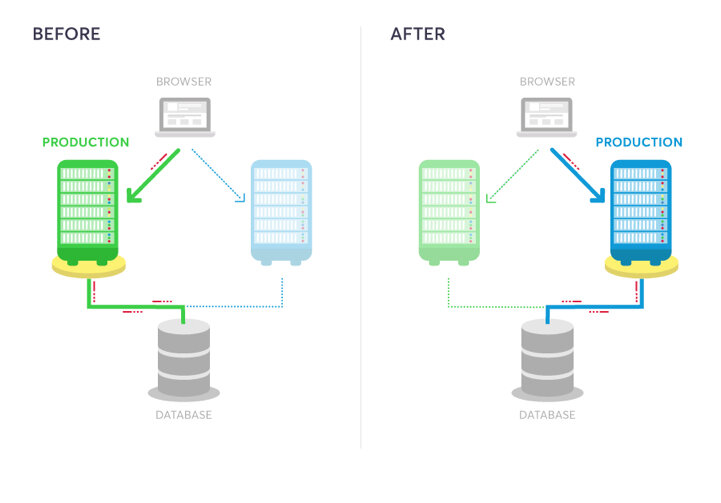
Stratégie Canary
Redirige le trafic d'une portion des utilisateurs en fonction de critères ou d'un simple pourcentage vers la nouvelle version. Après un certain temps ou d'une condition, l'ensemble du trafic est rédirigé.
Stratégie Feature Flag
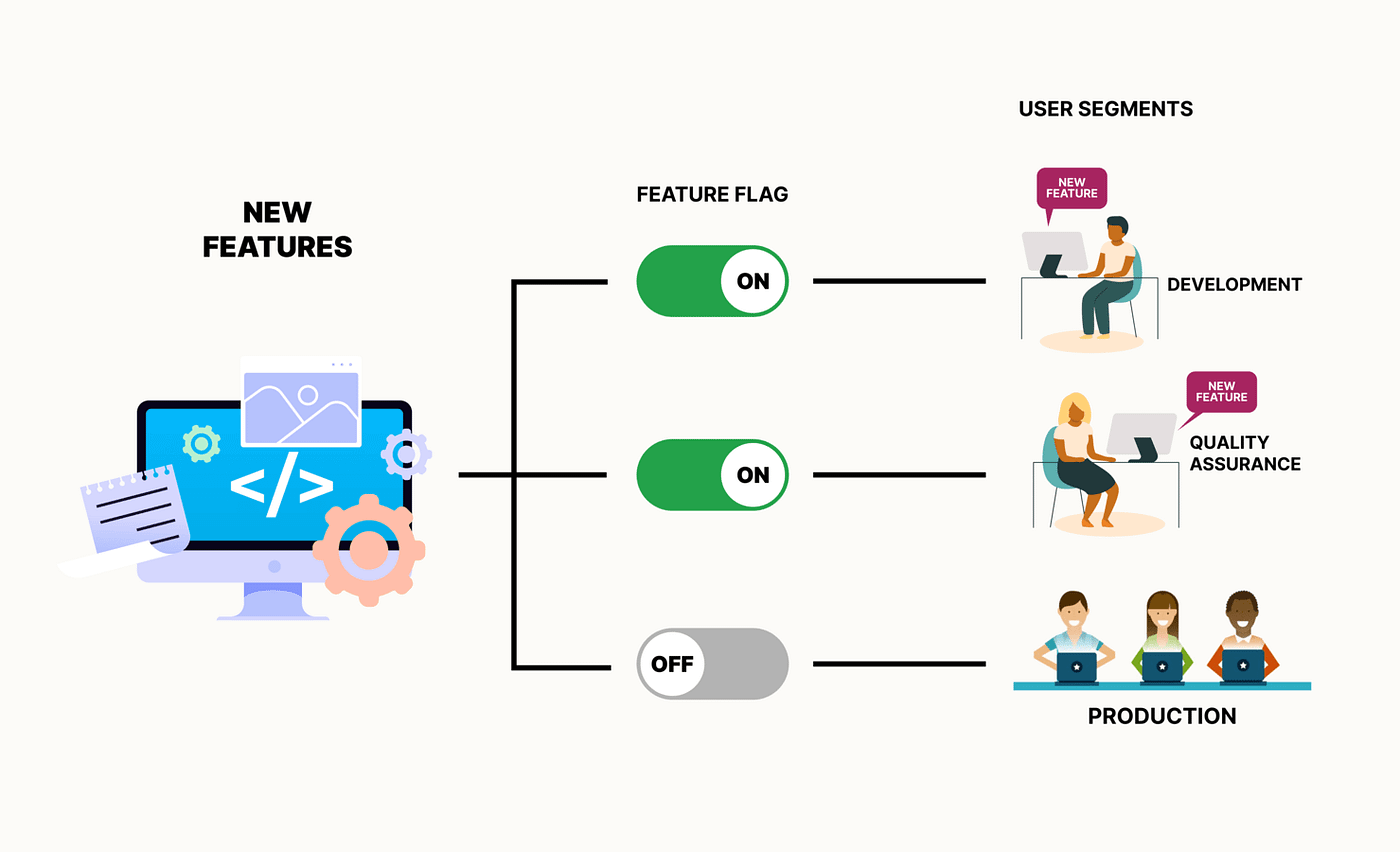
Gère les fonctionnalités dans le code source. Une condition dans le code permet d'activer ou de désactiver une fonctionnalité pendant l'exécution. Voir Unleash.
Mise en place des stratégies avec Gitlab CI
Bonus Exercice - Créer l'étape de Build d'une pipeline CI / CD avec Docker
En vous basant sur le cours, ajoutez dans votre pipeline CI / CD une étape permettant de build une image Docker et de la publier sur votre Docker Hub via Github Actions.
(Pour cela il vous faut un compte Docker)
Vous pouvez partir du code suivant comportant un projet de base en nodeJS et un Dockerfile :
https://gitlab.com/vm-marvelab/docker-cicd
Ceci est un bon exemple avec Gitlab CI.
Bonus - Exercice - Ajouter une partie sécurité à votre CI
Renseignez-vous sur les outils que vous pouvez ajouter à une CI pour vérifier la sécurité du projet comme :
- Scanner le dépôt pour vérifier si des secrets ont été push
- Scanner les dépendances du dépôt pour détecter des vulnérabilités.
- Utiliser un outil SAST pour vérifier les vulnérabilités de sécurité dans le code.
4.
N'hésitez pas à me donner votre avis.
Merci!
Intégration continue
By Valentin MONTAGNE



