Méthodes d'évaluation
UX
Réalisé par Haikel Gara, Antoine Verriez et Valentin Montagne
Master Expert Technologie de l'information EPITECH 2020.
Co-fondateur et CTO d'une startup dans l'Edtech 2019 - fin 2022. (+3 ans)
Formation PSPO-1 Agile Scrum 2022.
Co-fondateur et CTO d'une startup dans la Deeptech fin 2022 - aujourd'hui.
Valentin MONTAGNE

1
Conduire un audit UX
3
Évaluer les émotions des utilisateurs
5
Interpréter, synthétiser et restituer les résultats d’évaluation
2
Utiliser les échelles d’utilisabilité et échelles UX
4
Mesurer et analyser l’expérience utilisateur
Déroulement du cours
Chaque séance débutera par la présentation d'un concept et de l'intérêt d'utilisation de celui-ci.
1
Théorie
Après la théorie, nous verrons alors la pratique en réalisant des exercices sur un repository gitlab.
2
Pratique
Nous verrons ensemble la correction des travaux pratiques. N'hésitez pas à poser vos questions.
3
Correction
Déroulement des journées
Avez-vous déjà réalisé des tests utilisateurs ?
Votre propre agence UX
Durant ce module, vous allez par groupe de 2 à 3 personnes maximum en fonction du nombre de participants devenir une agence UX.
Chaque jour du module, vous aurez une mission pour un client fictif avec rendu en fin de journée.
Trouvez un nom / une identité pour votre agence !
Notation
Durant ce module, vous allez être évalué sur plusieurs livrables :
En groupe de 2 à 3 personnes
- Audit UX de maquettes d'une startup fictive avec présentation des résultats de l'audit et des recommendations en 20 minutes.
- Benchmark en utilisant une échelle UX entre Netflix et un concurrent avec présentation des résultats en 20 minutes.
- Tests utilisateurs sur un prototype interactif d'une startup fictive avec présentation des résultats en 20 minutes.
Individuel
- QCM pour vérifier les connaissances théoriques vu durant le module.
Conduire un audit UX
1.
Les différents types d’audits UX
1.1
Qu'est-ce qu'un audit UX ?
Évaluer la qualité d’un système à partir de l’expertise d’un groupe de spécialistes UX.
L’évaluation est réalisée par des experts en utilisabilité ou UX.
Dans un lieu adapté au travail de groupe, pour la seconde étape de l’évaluation experte.



Quand et comment réaliser un audit UX ?
Quand ?
Dès la génération des premières maquettes et jusqu’au produit final.
Comment ?
Plusieurs experts vont analyser la qualité d’un système à partir de guidelines ou critères, mais également de leur savoir et expérience. Les experts procèdent individuellement à l’évaluation, avant de mettre en commun leurs analyses.
Pourquoi réaliser un audit UX ?
Utiliser des guidelines, critères ou heuristiques déjà établies pour soulever une liste de problèmes à corriger.
Rapide et facile à mettre en œuvre pour évaluer l'UX durant toute l'itération produit.
Elle précédera d'autres méthodes comme le test utilisateur pour améliorer en continu la qualité d'un système.



Les limites de l'audit UX - 1
Dans l'étude de Jacobsen et John, quatre experts regardent la vidéo d'un test utilisateur et identifient indépendamment les problèmes d'utilisabilité.
Seuls 20 % des 93 problèmes détectés le sont par tous les experts et 46% ne le sont que par un seul.
Cette limitation, appelée biais de l'évaluateur (evaluator effect), fait l'objet d'un article célèbre de Hertzum et Jacobsen.
Les limites de l'audit UX - 2
Les résultats souffrent de variabilité liée aux experts qui réalisent l'évaluation (différents évaluateurs vont trouver différents problèmes pour la même interface) ou de la surestimation fréquente du nombre de problèmes réels, appelés « fausses alertes ».
Il est donc recommandé de l'utiliser en combinaison avec d'autres méthodes, telles que les tests utilisateurs.
En résumé - Les avantages - 1
- L'évaluation experte est relativement peu coûteuse et rapide à mettre en œuvre.
- Elle s'applique dès la génération des premières maquettes, jusqu'à l'évaluation du produit final et permet de recueillir du feedback tôt dans le processus.
- Les nombreux ensembles de critères, heuristiques ou guidelines couvrent plusieurs dimensions du système (utilisabilité, accessibilité, qualité).
En résumé - Les avantages - 2
- Il existe des guidelines spécifiques appliquées à un type de système ou de produit (Web, mobile, tablettes) et régulièrement mises à jour.
- Les résultats issus de l'évaluation experte sont facilement traduisibles en recommandations pour l'amélioration du système.
En résumé - Les limites
- L'efficacité de la méthode est fortement liée au niveau d'expertise des évaluateurs, dans le domaine de l'UX mais aussi sur la thématique concernée.
- Les évaluations par des experts surestiment parfois le nombre de problèmes réels et des biais liés aux évaluateurs ont été montrés par de nombreuses études.
- Les pratiques d'évaluation experte nécessitent d'être adaptées pour l'évaluation plus approfondie de l'interaction et de l'UX en fonction du produit.
Faut-il suivre aveuglement les critères pour créer une expérience optimale ?
Au premier abord, on pense souvent qu'une bonne utilisabilité est une condition préliminaire à une bonne UX.
Or, si le concept d'expérience utilisateur englobe l'utilisabilité comme l'un des aspects clés dans la perception de l'attractivité d'un système, cela ne signifie pas qu'il faille respecter à la lettre l'ensemble des critères d'utilisabilité pour créer une expérience optimale.
L'exemple de la Photobox de Odom - 1
Son principe est simple : une boîte en bois intégrant une imprimante Bluetooth cachée. Connectée au compte FlickR de l'utilisateur, la PhotoBox imprime occasionnellement une photo, sélectionnée aléatoirement. Une fois imprimé, ce souvenir attendra patiemment d'être découvert par son propriétaire.
L'exemple de la Photobox de Odom - 2
La PhotoBox ne nécessite aucune attention de la part de l'utilisateur. Ici, on ôte délibérément tout contrôle à ce dernier: il ne choisit ni ce qui est imprimé, ni la fréquence d'impression.
Comme le montre Lallemand, le principe de Photobox viole l'un des critères fondamentaux en utilisabilité qu'est le contrôle utilisateur, au profit d'une expérience émotionnelle d'anticipation, de surprise et de rappel du passé.
L'exemple de la Photobox de Odom - 3
Des recherches ont en effet montré que céder de l'autonomie à un système interactif peut créer de nouvelles expériences d'interaction avec du contenu digital.
L'évaluateur expert devra ainsi choisir de respecter ou non les critères établis en fonction des objectifs visés par le système.
Points communs des audits
Visent à améliorer l’expérience utilisateur.
Utilisent souvent une grille critériée (heuristiques, standards).
Se basent sur des observations expertes (UX designer, ergonome).



Divergences des audits
Portée
- Externe (marché) - Audits concurrentiel et UX
- Interne (produit) - Audits d'ergonomie, d'accessibilité ou de cohérence.
Finalité
- La comparaison - Benchmark
- La mise en conformité - Audit d'accessibilité
- L’amélioration interne - Audit de cohérence ou d'ergonomie.
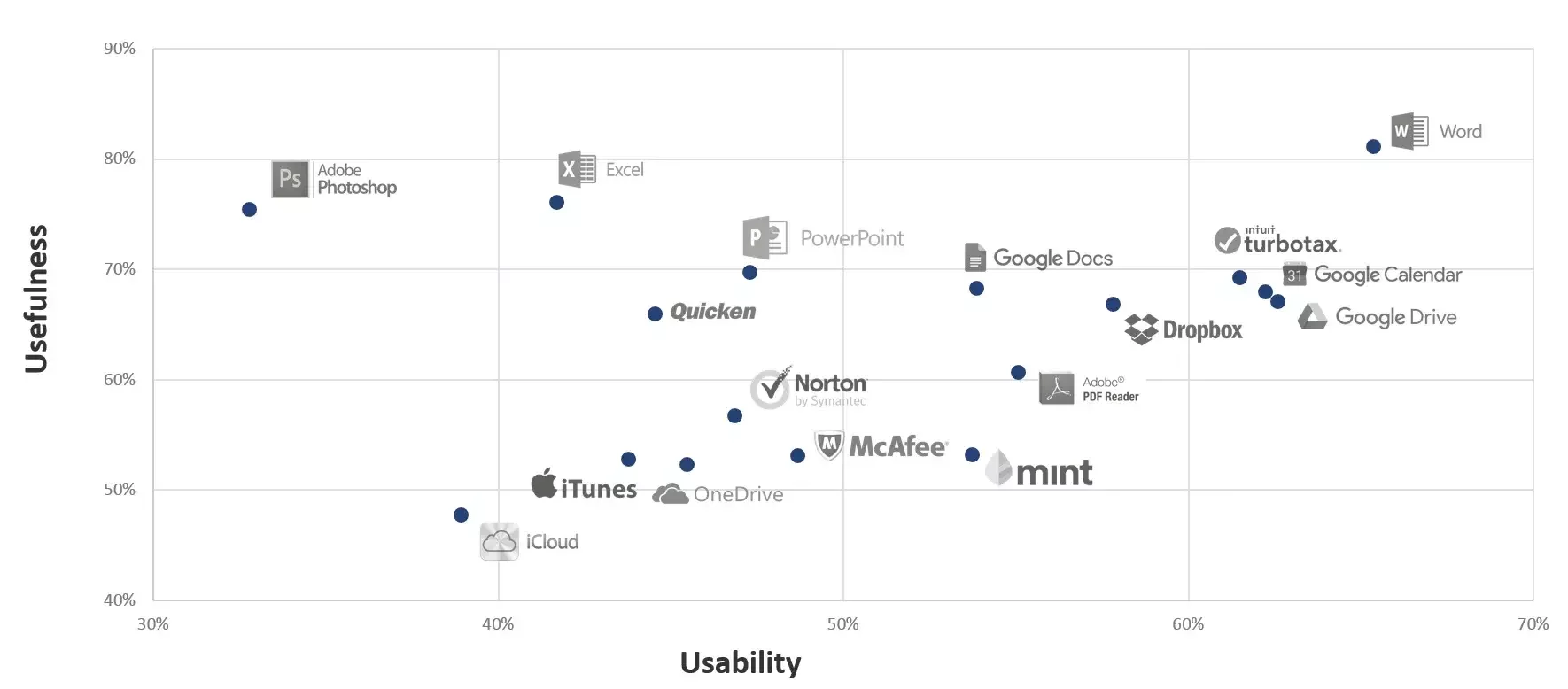
Benchmark concurrentiel
| Objectif | Comparer son produit à ceux des concurrents directs. |
| Méthodes | Analyse des parcours, fonctionnalités, ergonomie, design visuel. |
| Contexte d'usage | Étude de marché, lancement produit, repositionnement. |
| Exemple | Comparer les tunnels de paiement de 5 sites e-commerce. |
Benchmark UX
| Objectif | Comparer son produit à des références UX transversales. |
| Méthodes | Indicateurs UX standardisés (questionnaires, heuristiques Nielsen, tests utilisateurs, etc.) |
| Contexte d'usage | Vérifier si son produit est au niveau des standards de l’industrie. |
| Exemple | Mesurer l’utilisabilité d’une app de transport par rapport à d’autres apps réputées. |
Audit UX et ergonomique
| Objectif | Identifier les forces et faiblesses selon les critères d’ergonomie. |
| Méthodes | Grilles d’analyse (Bastien & Scapin, heuristiques Nielsen, règles Amélie Boucher) |
| Contexte d'usage | Avant redesign, pendant la conception. |
| Exemple | Vérifier la cohérence et la fluidité d’un parcours d’inscription SaaS avant son déploiement. |
Audit d'accessibilité
| Objectif | Vérifier la conformité aux normes d’accessibilité (inclusion). |
| Méthodes | WCAG 2.1, RGAA, tests de navigation clavier/lecteurs d’écran. |
| Contexte d'usage | Secteur public (obligatoire), privé (RSE, inclusion). |
| Exemple | Auditer un portail de mairie pour utilisateurs malvoyants. |
Depuis le 28 juin 2025, l'European Accessibility Act – EAA oblige maintenant les entreprises privées essentielles d'avoir une bonne accessibilité.
Audit de cohérence
| Objectif | Vérifier l’alignement visuel et fonctionnel à l’intérieur d’un produit ou entre plusieurs. |
| Méthodes | Analyse du design system, patterns UI, terminologie, ton rédactionnel. |
| Contexte d'usage | Entreprises multi-produits, refonte design system. |
| Exemple | Vérifier que l’app mobile et le site web d’une banque utilisent les mêmes composants, même développer un Design System. |
En conclusion
L’audit UX est donc une photo experte de l’état actuel du produit et de son environnement.
Il est indispensable pour orienter le design et justifier les choix auprès des parties prenantes.
Quizz - Le bon audit
Retrouvez le bon type d'audit à faire dans chaque situation :
- Mon entreprise possède plusieurs solutions en ligne et aimerait créer un Design System.
Audit de cohérence
- Un nouveau parcours d'inscription va être déployé le mois prochain.
Audit UX
- Mon entreprise prévoit d'ajouter une nouvelle fonctionnalité qui doit être la meilleure sur le marché.
Benchmark concurrentiel
Benchmark concurrentiel & UX
Comment réaliser un benchmark concurrentiel ?
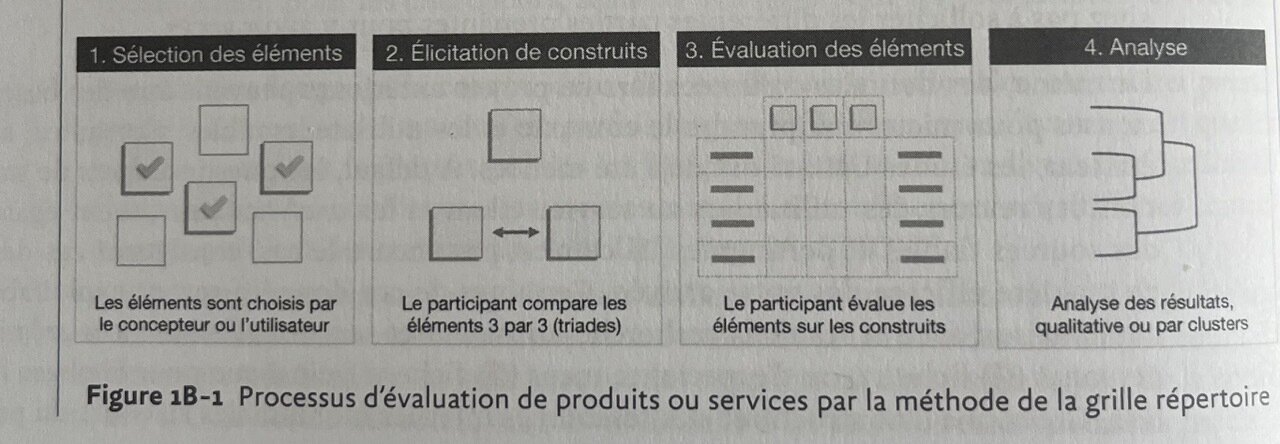
1. Sélection des éléments
- Lister 5 à 10 systèmes ou produits concurrents via vos propres connaissances ou par un utilisateur.
- Pour un site web, rafraîchir la mémoire via une interaction rapide ou des captures.
- La connaissance préalable du concurrent est indispensable pour évaluer l’UX globale, mais pas pour juger la première impression ou l’esthétique.
2. Élicitation de construits
- Faire comparer les éléments 3 par 3 (méthode triadique) pour faire émerger les critères clés de l’expérience.
- Varier les triades, puis formaliser les construits en oppositions (ex. facile/difficile, confortable/inconfortable) sur une échelle de 7 points.
3. Évaluation des éléments
- Le participant évalue ensuite chacun des éléments sur les construits élicités à l'étape précédente.
- Cette évaluation se présente sous la forme d'une grille.
4. Analyse des résultats
L'analyse des résultats montre les caractéristiques qui différencient les concurrents et celles qui soutiennent une expérience positive.
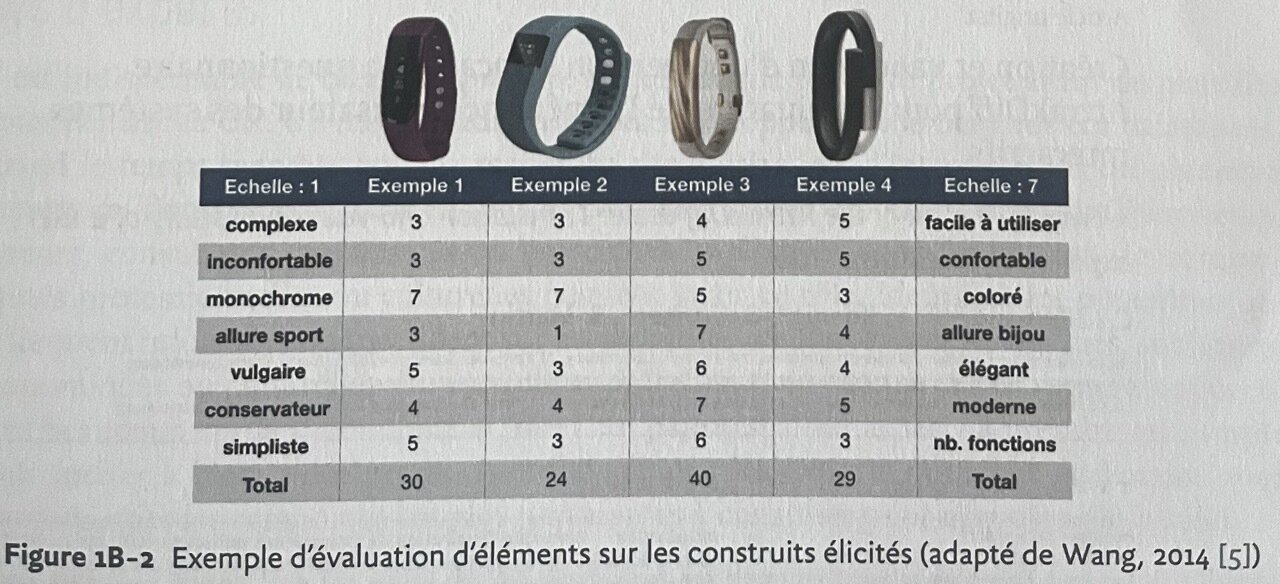
Comment réaliser un benchmark UX ?
On va alors utiliser des indicateurs UX standardisés (SUS, AttrakDiff, heuristiques Nielsen) pour comparer différents produits ou systèmes avec le même indicateur.
Pour ensuite, analyser et trier ceux qui ont les meilleurs indicateurs et comment ils se placent face à notre produit.
Nous verrons plus tard dans le module les questionnaires UX comme SUS et AttrakDiff.
Audit UX et ergonomique
Pourquoi réaliser un audit UX ?
- Améliorer la compréhension de l’utilisateur.
- Détecter et corriger rapidement les défauts d’interface.
- Optimiser la navigation et le contenu.
- Améliorer la conversion, rétention et satisfaction.
- Proposer des solutions innovantes pour une expérience utilisateur claire, fluide et intuitive.
Comment réaliser un audit UX ?
- Choisir un des standards ergonomiques pour évaluer l'interaction, la cohérence, la navigation, la priorisation des actions et la lisibilité comme les heuristiques de Jacob Nielsen ou critères de Bastien et Scapin.
- S’appuyer sur des données qualitatives (retours utilisateurs) et quantitatives (taux de rebond, trafic, ROI), essentielles pour ajouter de la matière à l'audit.
- Analyser et créer un rapport liant, pour chaque vue de la solution, les problèmes identifiés par critères et les recommandations.
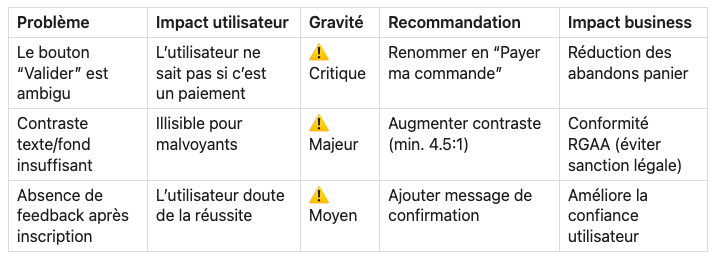
Exemple de rapport

Les principales raisons qui dégradent l'ergonomie
- Un menu, un lien ou un bouton inaccessible.
- Un chargement long d’une page.
- Un parcours complexe.
- Un formulaire qui ne fonctionne pas convenablement
- Une navigation complexe.
- Une structure d’information mal organisée ou un design non attractif.
Audit d'accessibilité
Pourquoi réaliser un audit d'accessibilité ?
Tous les utilisateurs, même avec handicap, utilisent le produit sans obstacle.
Améliorer l’image de marque via l’inclusion.
Garantir le respect des obligations légales (RGAA) et réduire le risque juridique.



Comment réaliser un audit d'accessibilité ? - 1
On utilise un standard international comme WCAG 2.1 (Web Content Accessibility Guidelines) :
- Contraste des couleurs (lisibilité).
- Alternatives textuelles aux images.
- Navigation entièrement possible au clavier.
- Compatibilité avec lecteurs d’écran (ex. NVDA, JAWS, VoiceOver).
- Compréhension des contenus (langage clair, éviter jargon inutile).
Comment réaliser un audit d'accessibilité ? - 2
Des outils existent pour vérifier certains critères comme :
La validation de l'accessibilité est une combinaison d’audit automatique, d'inspection manuelle par un expert et de tests utilisateurs avec personnes en situation de handicap.
Préparation de l'audit UX
1.2
Définir les objectifs
Partir du problème business ou produit, le symptôme déclencheur : Baisse de conversion, taux de rebond élevé, abandon dans un tunnel, retours utilisateurs négatifs, refonte prévue, produit jugé “complexe” ou “peu utilisé”.
Objectif mal défini :
Améliorer l’expérience utilisateur du formulaire d'inscription.
Objectif mieux défini :
Comprendre pourquoi les nouveaux utilisateurs mobile abandonnent le formulaire d’inscription.
Définir un objectif SMART
Un bon objectif d’audit UX SMART est :
-
Spécifique : quel parcours, quelle cible
-
Mesurable : critères de succès clairs
-
Actionnable : débouche sur des décisions
-
Réaliste : faisable avec les ressources
-
Temporel : lié à un contexte ou une échéance
Exemple complet :
Identifier les freins UX du parcours de commande mobile afin de réduire le taux d’abandon avant le prochain sprint de refonte.
Définir la cible (Persona)
Avant de démarrer le processus d’audit, il est indispensable de bien connaître ses utilisateurs actuels et ses futurs prospects.
Pour y parvenir, il est pertinent de créer des cas d’utilisations et des personas. Ces éléments aident l’UX designer à avoir une idée sur :
- Les frustrations et les attentes de l’usager.
- L’objectif de l’interaction avec une interface.
- Une meilleure appréhension du public cible.
Définir le périmètre
On peut délimiter le périmètre de l’audit en fonction du temps et des ressources disponibles :
- Si le produit implique plusieurs types d’utilisateurs ou parcours multiples, mieux vaut prioriser les parcours à plus forte valeur.
- Côté plateformes, idéalement auditer desktop et mobile (les deux sont souvent utilisés).
- En cas de contrainte, se concentrer sur la plateforme la plus critique ou celle qui génère le plus de trafic.
Toujours prioriser les parcours et plateformes à plus forte valeur/impact pour cadrer efficacement l’audit.
La collecte d'informations
Cette étape consiste à rassembler :
- Les éléments du produit à analyser (interfaces, parcours utilisateurs, fonctionnalités clés, composants interactifs).
- Les documents de référence (design system, guides de style, roadmap produit, rapports précédents).
- Le contexte stratégique : objectifs de l’entreprise, contraintes techniques, timing, budget.
- Les données utilisateurs disponibles : profils démographiques, comportements observés, feedbacks, verbatims, analytics (taux de conversion, abandon, etc.).
- Les résultats issus de tests d’utilisabilité ou d’études antérieures.
Établir un plan d'action
- Choisir le type d’audit : ergonomique, accessibilité, cohérence, benchmark.
- Sélectionner les outils : tableau Excel, Notion, Miro, Figma (annotations), etc.
- Planifier le déroulé : qui audite ? combien de temps ? restitutions intermédiaires ?
- Prévoir la restitution : livrable pour l’équipe projet ou client (rapport, tableau de synthèse, présentation).
L’audit doit être pensé comme une mini-mission UX structurée, pas juste une “liste de défauts”.
Élaborer une grille d'audit - 1
La grille est le cœur de l’audit : elle structure l’évaluation et évite les oublis. Elle permet de définir les critères d’évaluation qui serviront de base à l’audit.
Ces critères permettent de mesurer la qualité de l’expérience utilisateur de façon structurée et objective.
Parmi les critères couramment utilisés, on retrouve :
- Clarté & compréhension : l’interface est-elle compréhensible au premier regard ?
- Cohérence & homogénéité : les composants, terminologies et interactions suivent-ils une logique unifiée ?
- Efficacité & fluidité : l’utilisateur atteint-il ses objectifs sans effort inutile ?
Élaborer une grille d'audit - 2
- Accessibilité & inclusion : le produit est-il utilisable par tous, y compris en situation de handicap ou de contrainte technique ?
- Pertinence & utilité : les fonctionnalités et contenus répondent-ils aux besoins des utilisateurs tout en servant les objectifs du projet ?
- Compatibilité & standards : respect des bonnes pratiques, guidelines internes, normes (WCAG, ISO, heuristiques Nielsen, Bastien & Scapin).
Les standards - Les critères de Bastien et Scapin
Créé en 1993 pour l'ergonomie logicielle, 8 familles de critères :
- Guidage (feedback, incitations, affordances).
- Charge de travail (mémoire, actions inutiles).
- Contrôle explicite (l’utilisateur garde la main).
- Adaptabilité.
- Gestion des erreurs.
- Homogénéité / cohérence.
- Signifiance des codes et dénominations.
- Compatibilité (avec contexte, tâches, habitudes).
Exemple de rapport client
Les standards - Heuristiques de Nielsen
Créé en 1994, très utilisées en UX, 10 principes :
- Visibilité de l’état du système.
- Correspondance entre système et monde réel.
- Contrôle utilisateur et liberté.
- Cohérence et standards.
- Prévention des erreurs.
- Reconnaissance plutôt que rappel.
- Flexibilité et efficacité d’utilisation.
- Esthétique et design minimaliste.
- Aide aux erreurs : détection, diagnostic, correction.
- Aide et documentation.
Les standards - Autres
- Heuristiques de Colombo & Pasch, créé en 2012, très axées UI mobile et interactions modernes, 10 principes.
- Règles d’Amélie Boucher, créé ~2007, Ergonomie web et UX Design, 12 règles inspirées de Bastien et Scapin.
-
Critères WCAG 2.1, accessibilité web, norme internationale, 4 principes :
-
Perceptible : alternatives textes, contrastes, multimédia accessible.
-
Utilisable : navigation clavier, temps suffisant, prévention crises (photosensibilité).
-
Compréhensible : lisibilité, assistance à la saisie.
-
Robuste : compatibilité avec technologies d’assistance.
-
Réaliser l'audit UX
1.3
Analyse des données quantitatives - 1
-
Les entreprises utilisent des outils comme Google Analytics pour mesurer la performance de leurs produits digitaux.
-
Ces données fournissent des indicateurs chiffrés qui montrent comment les utilisateurs interagissent avec un site ou une application.
-
Pour aller plus loin, on peut utiliser des outils complémentaires (Hotjar, CrazyEgg, Kissmetrics, PostHog) afin d’analyser les comportements plus en détail.
Analyse des données quantitatives - 2
-
Exemples de métriques importantes :
-
heatmaps (zones les plus consultées),
-
taux de rebond,
-
durée moyenne par page,
-
taux de scroll,
-
nombre de visiteurs uniques.
-
-
L’objectif est de repérer des tendances et de mieux comprendre les usages afin d’améliorer l’expérience utilisateur.
Stratégies d'évaluation
Écran par écran : la plus courante et recommandée. Sur chaque écran, l'expert évalue un par un tous les éléments.
Par heuristique ou critère : où chaque élément est évalué sur tous les écrans du système. L'avantage de cette approche est que l'expert reste focalisé sur un seul aspect à la fois.
Évaluation individuelle
-
Lors d’une évaluation heuristique, chaque expert analyse l’interface plusieurs fois, en vérifiant les éléments d’interaction à l’aide de critères ou heuristiques définis.
-
L’évaluateur identifie les points positifs et les points négatifs de l’interface.
-
En pratique, le rapport final contient souvent environ 80 % de problèmes et 20 % de points positifs.
-
Chaque expert produit une liste structurée d’observations.
-
Les problèmes doivent être expliqués et illustrés (captures d’écran, annotations).
-
Un même élément d’interface peut être signalé plusieurs fois, s’il ne respecte plusieurs heuristiques différentes.
Pourquoi lister le positif ?
Les points positifs sont importants car ils permettent de :
-
Faciliter l’acceptation du rapport par le commanditaire.
-
Éviter que des éléments efficaces soient supprimés par erreur lors des évolutions.
-
Renforcer ou réutiliser ces bonnes pratiques dans les futures versions de l’interface.
Trier les problèmes
Vous pouvez définir plusieurs niveaux de problèmes :
- Problèmes mineurs, non bloquants et sans incidence directe sur la tâche de l'utilisateur.
- Problèmes non bloquants mais importants car ils perturbent la tâche de l'utilisateur.
- Problèmes majeurs potentiellement bloquants pour l'utilisateur.
Confronter les résultats
-
Après les évaluations individuelles, les experts se réunissent pour partager les problèmes identifiés.
-
En cas de divergences, ils discutent afin d’aboutir à un consensus, qui servira de base au rapport final d’évaluation.
-
Cette phase est essentielle pour comparer les points de vue, comprendre les écarts de jugement et pondérer les observations selon l’expertise de chacun.
-
Le travail collectif permet aussi de proposer des solutions plus pertinentes et concrètes aux problèmes UX détectés.
Bonnes pratiques
- Utiliser un outil unique comme source de vérité pour centraliser les résultats.
-
Regrouper les problèmes par thèmes communs afin de formuler des solutions globales.
Analyse des résultats de l'audit UX
1.4
Une étape clé
La valeur d’un audit ne réside pas dans la liste des problèmes identifiés, mais dans la manière dont on traduit les résultats en leviers d’action adaptés à l'audience.

Objectif d'un rapport
Un rapport d’évaluation UX sert à résumer et expliquer clairement les résultats d’une évaluation réalisée par des experts, afin d’aider le commanditaire à améliorer le produit et l’expérience utilisateur.
Il ne s’agit pas seulement de lister des défauts, mais de faire comprendre les problèmes, leur importance et leurs conséquences.
Comment analyser et interpréter un audit ?
Les résultats prennent la forme :
-
D’une synthèse des évaluations individuelles.
-
D’un classement des observations :
-
Points forts / points faibles.
-
Niveau de gravité (impact sur l’utilisateur).
-
Pour chaque problème identifié, on fournit :
-
Une description claire (souvent avec capture d’écran).
-
Un score de gravité ou d’importance.
-
Des recommandations d’amélioration concrètes.
Comment analyser et interpréter un audit ?
Chaque problème doit être numéroté, afin de faciliter :
-
Les discussions avec l’équipe de conception.
-
Les échanges avec le commanditaire.
-
Tracer leur résolution.
Comment rédiger un rapport ?
Le commanditaire n’étant généralement pas expert en UX, le rapport doit utiliser un langage simple et accessible.
Il comprend généralement :
-
Une courte présentation du système évalué
(produit, service, contexte d’usage) -
La méthode d’évaluation utilisée
(type d’évaluation experte, critères, référentiel, etc.) -
Le nombre et le profil des experts
(UX designers, ergonomes, chercheurs…) -
Une synthèse des problèmes et recommandations
-
Sous forme de liste ou de tableau
-
Problèmes + gravité + recommandations
-
Les erreurs à ne pas faire
De nombreux clients ont du mal à exploiter :
-
des rapports trop longs ;
-
des listes exhaustives de petits problèmes mineurs.
Résultat fréquent :
Seuls les problèmes les plus simples techniquement sont corrigés, pas forcément les plus importants pour l’UX.
Et si on allait plus loin ?
Selon Barnum, la valeur centrale d’une évaluation experte est avant tout de motiver le commanditaire à améliorer l’expérience utilisateur.
Nouvelle approche recommandée : se concentrer sur l’expérience vécue par l’utilisateur et utiliser le storytelling plutôt qu’un inventaire exhaustif.
Concrètement :
-
Le rapport prend la forme d’une présentation narrative : Il met en scène des personas.
-
Il raconte le parcours utilisateur écran par écran.
-
Avec des réactions, pensées et commentaires fictifs, mais réalistes.
En résumé
-
Un bon rapport UX est clair, synthétique et orienté action
-
Il doit être compréhensible par des non-spécialistes
-
Numérotation, gravité et recommandations sont essentielles
-
Aujourd’hui, raconter l’expérience utilisateur peut être plus efficace que tout documenter
L’évaluation UX ne sert pas qu’à analyser, mais à convaincre et déclencher le changement.
Comment exploiter les résultats d'un audit ?
Interpréter les résultats selon le public cible
Utiliser des outils de présentation et de priorisation
Intégrer dans le process UX
Interpréter les résultats pour l'équipe UX
But : comprendre la profondeur des problèmes et hiérarchiser.
Méthode :
- Classer les constats par gravité (critique, majeur, mineur).
- Regrouper les problèmes par thème (navigation, lisibilité, feedback, accessibilité).
- Relier les constats aux critères violés (Nielsen, Bastien & Scapin, WCAG).
Livrable interne : grille d’analyse brute, tableau de priorisation.
Interpréter les résultats pour l'équipe projet / produit
But : fournir un outil actionnable pour corriger.
Méthode :
- Traduire chaque constat en ticket actionnable.
- Donner une priorisation : Impact utilisateur x Effort de correction.
- Croiser avec objectifs business (conversion, fidélisation, légalité).
Livrable interne : rapport synthétique, workshop collaboratif pour définir les priorités.
Interpréter les résultats pour le client
But : convaincre et aligner les parties prenantes.
Méthode :
- Simplifier le langage, vulgariser.
- Illustrer avec captures d’écran annotées (avant/après, exemples inspirants).
- Relier les problèmes aux risques business (ex. abandon panier = perte de CA, non-conformité WCAG = risque légal).
Livrable interne : présentation en 3 parties : forces du produit, irritants principaux, recommandations prioritaires.
Utiliser des outils de présentation et de priorisation
- Tableaux de priorisation (Impact / Effort ou Gravité / Fréquence).
-
Matrice 2x2 :
- Impact fort + faible effort : à corriger en priorité.
- Impact faible + effort fort : à repousser.
- Roadmap UX : intégrer les recommandations dans le planning produit.
- Visualisation : heatmaps des problèmes, maquettes corrigées (Figma), captures annotées.
Intégrer dans le process UX
- En phase de conception : intégrer recommandations dans les wireframes (corriger directement).
- En phase de développement : transformer les constats en tickets (Jira, Trello, Notion).
- En phase de suivi : refaire un audit comparatif après correctifs pour mesurer l’amélioration.
L’audit doit être une boucle itérative, pas un livrable figé.
Exemple de rapport à un client
C'est l'heure de la pratique !
1.5
Réaliser un audit UX pour une startup
Il est l'heure de s'entraîner pour réaliser un audit UX, son analyse et sa restitution à un client.

Historique de Collab
La startup Collab a rencontré un succès important lors de sa phase bêta grâce à :
-
Une solution ludique de collaboration en ligne : un bureau virtuel simulant les interactions sociales d’un open space.
-
Une campagne marketing efficace.
Suite à ce succès, Collab a décidé de :
-
Lancer de nouvelles formules commerciales.
-
Ajouter de nombreuses fonctionnalités.
-
Repenser entièrement certains parcours utilisateurs.
Ces évolutions ont été réalisées sans accompagnement UX.
Problèmes de Collab
Depuis la sortie officielle de la version 1.0.0, l’entreprise observe :
-
Une dégradation nette des KPI.
-
Une baisse des inscriptions.
-
Une baisse des achats.
-
Un changement de comportement des utilisateurs par rapport à la bêta.
Ces signaux indiquent très probablement :
-
une dégradation de l’expérience utilisateur.
-
des parcours devenus moins clairs, moins efficaces ou moins engageants.
Les KPIs
-
Taux de conversion landing à page d’inscription
-
25% → 25% (stable)
-
-
Taux de conversion page d’inscription à compte créé
-
7% → 2,5% (forte baisse)
-
-
Taux de passage compte gratuit à compte payant
-
12% → 3% (chute critique)
-
-
Taux d’upgrade de formule
-
27% → 7% (chute très importante)
-
-
Taux de churn
-
3% → 2% (légère amélioration)
-
Objectif de l'audit UX
Vous êtes missionnés en tant qu’Agence UX pour :
-
Analyser l’existant
-
Comprendre les causes de la baisse de performance
-
Proposer des solutions concrètes
-
Améliorer l’expérience utilisateur et redresser les KPI
L’objectif final n’est pas seulement d’identifier des problèmes, mais de restaurer la valeur perçue du produit et sa capacité à convertir.
Périmètre de l'audit UX
L'audit UX se focalise sur la version mobile de la solution et sur deux parcours :
Et sur deux personae :
- Isabelle - Manager d'une équipe Design
- Marc - Designer
Lien vers le Product Pitch et les fiches persona
Les maquettes ont volontairement de belles erreurs d'UX ! ;-)
Soutenance
Présentation des résultats de l'audit UX
20 minutes
Les échelles d’utilisabilité et échelles UX
2.
Qu'est-ce qu'une échelle UX ?
Les échelles UX sont des outils standardisés qui recueillent l'avis des utilisateurs sur la facilité d'utilisation perçue d'un système et la satisfaction liée à l'interaction.
Ce sont des questionnaires d'évaluation subjective auto-administrés : les utilisateurs y répondent eux-mêmes.
Pourquoi utiliser une échelle ?
S'appuyer sur des échelles standardisées
Exploiter des mesures quantitatives
Se reposer sur une validation scientifique



Les échelles sont un moyen simple et rapide de collecter de la donnée.
S'appuyer sur des échelles standardisées - 1
Une échelle standardisée est un questionnaire qui reprend un ensemble de questions pré-définies, toujours posées dans le même ordre, et qui dispose d'une grille de réponse et de cotation identique pour tous les répondants.
S'appuyer sur des échelles standardisées - 2
Comparer plusieurs versions d'un même système.
Comparer différents systèmes entre eux.
Tester un système auprès de plusieurs catégories d'utilisateurs.


Exploiter des mesures quantitatives
Les échelles recueillent des données quantitatives.
On peut alors réaliser différents traitements et comparaisons statistiques ; elles facilitent la communication des résultats auprès du commanditaire.
Par exemple, des graphiques pourront illustrer les scores d'évaluation d'un système par rapport à un autre.
Se reposer sur une validation scientifique
On utilise en priorité les échelles validées scientifiquement, elles répondent à deux critères :
- La fiabilité - Appliquée dans les mêmes conditions auprès des mêmes utilisateurs, doit permettre d'obtenir les mêmes scores.
- La validité - qui ont démontré qu'elles évaluaient bien l'opinion des utilisateurs vis-à-vis de l'utilisabilité d'un système donné.
Limites des échelles
Biais de passation (formulation des questions, ordres des items, effet de halo, l'acquiescement)
Si trop long, l'utilisateur répond au plus vite pour être débarrassé.
Ne permet pas de comprendre le Pourquoi, simplement de définir un score.


Comment utiliser une échelle ?
Qui : L’évaluateur sélectionne, diffuse puis analyse les résultats de l'échelle. Un échantillon d’utilisateurs répond au questionnaire.
Où : Le questionnaire peut être administré par papier, ou en ligne.
Quand : Pendant de multiples cycles itératifs d'évaluation. Après la passation d'un test utilisateur ou simplement après une interaction réelle avec un système déjà fonctionnel.
Adapter l'échelle en fonction de son besoin - 1
Une échelle mesure des aspects particuliers d'un système : qualité de l'information, facilité de navigation, apprenabilité, etc.
Si vous souhaitez mesurer une caractéristique précise de votre produit, rien de vous empêche d'utiliser uniquement les items des dimensions qui vous intéressent, ou même de combiner plusieurs dimensions de différentes échelles.
Adapter l'échelle en fonction de son besoin - 2
Attention
Dans ces deux cas, vous ne pourrez pas calculer le score globale du système puisque vous ne disposerez pas de tous les items originaux d'un unique questionnaire.
Format d'un questionnaire
La norme ISO 16982 recommande de privilégier les questionnaires fermés, où le répondant choisit une réponse sur une échelle chiffrée ou dans une liste prédéfinie.
Cela facilite l’analyse et le traitement statistique des résultats, contrairement aux questions ouvertes plus difficiles à exploiter.
Chaque échelle dispose de son propre format, le plus souvent une échelle de Likert à 3, 5, 7 ou 9 points.
Qu'est-ce qu'une échelle de Likert ?
Un outil de mesure très utilisé en sciences sociales, en psychologie, en marketing et dans les enquêtes d’opinion pour évaluer les attitudes, perceptions ou opinions d’un répondant sur un sujet donné.
On présente une affirmation (ex. : « Je suis satisfait de ce service ») et on demande au répondant d’indiquer son degré d’accord ou de désaccord sur une échelle graduée.
Permet de passer du qualitatif au quantitatif.
Exploiter les résultats
Améliorer le système de manière itérative : l'évaluation sert à la conception.
Stratégie UX à long terme : définir des indicateurs sous forme d'objectifs au début du projet
Suivre l'amélioration continue : l'évolution de l'expérience au fil des versions.


En mode Guérilla
Les échelles UX, déjà économes en ressources, peuvent être encore allégées pour réduire le temps de passation et d’analyse.
Comme toute approche “guérilla”, cela implique des compromis sur la quantité et la précision des données.
Cette pratique reste pertinente si elle s’intègre à d’autres méthodes et si l’on privilégie des échelles courtes, notamment pour les études longitudinales (journaux de bord).
Différence entre Utilisabilité, UX, Emotion
2.1
Échelles d'utilisabilité
Mesurer la facilité d’utilisation perçue d’un système (efficacité, efficience, facilité d’apprentissage).
Utilisabilité seulement.
SUS, UMUX, UMUX-Lite, CSUQ, EUCS, DEEP.
"Est-ce que le système est facile à utiliser ?"


Échelles UX
Mesurer l’expérience utilisateur dans son ensemble même les dimensions hédoniques.
Plusieurs critères :
Utilisabilité, émotions, esthétique et satisfaction globale.
AttrakDiff, meCUE, UEQ.
“Comment je me sens en utilisant le système ? Est-ce agréable, utile, motivant ?”

Échelles émotionnelles
Mesurer directement les émotions ressenties : positives, négatives, intensité.
Plusieurs critères :
Utilisabilité, émotions, esthétique et satisfaction globale.
SAM (Self-Assessment Manikin), PANAS, PrEmo, etc.
“Qu’est-ce que j’ai ressenti pendant l’interaction ?”
En résumé
- L'utilisabilité n'est qu'une composante de l'expérience utilisateur.
- Les échelles d’utilisabilité sont plus ciblées : efficace pour mesurer la performance perçue.
- Les échelles UX sont plus holistiques : utiles pour mesurer l’expérience globale.
- Les échelles émotionnelles vont encore plus loin : centrées sur l’affect.
Questionnaires d'utilisabilité
2.2
Définition de l'utilisabilité
Degré selon lequel un produit peut être utilisé par des utilisateurs identifiés, pour atteindre des buts définis avec efficacité, efficience et satisfaction, dans un contexte d'utilisation spécifié.
(ISO 9241-11, 1998)
SUS - System Usability Scale
Une des premières échelles de mesure de l'utilisabilité perçue (1996).
Libre de droits et comporte un nombre restreint d'items faciles à comprendre pour les utilisateurs.
Le créateur du SUS, John Brooke, explique que cette échelle a été créée avec soin en se basant sur les éléments de la norme ISO 9241-11 sur l'utilisabilité , mais qu'elle se voulait quick and dirty pour les utilisateurs, c'est-à-dire rapide à remplir et facile à comprendre.
Pourquoi utiliser SUS ?
- Un questionnaire à faible coût, simple et facile à remplir par l’utilisateur. (- de 15 min / participant)
-
C’est la plus utilisée historiquement : un questionnaire en 10 items qui fournit un score global d’usabilité.
-
Comparatif, permet de benchmarker.
Le questionnaire
Que veut dire le score ?
Le score SUS moyen est estimé à 68.
On estime en général qu’un score est bon à partir de 75.
Passable ou correct : entre 50 et 75.
Un score inférieur à 50 révèle de gros problèmes en termes de satisfaction client sur l’usabilité.
UMUX & UMUX-Lite
En cherchant à réduire le plus possible le nombre d'items du SUS tout en gardant la même mesure des composants de l'utilisabilité (efficacité, efficience, satisfaction), Finstad a développé et validé l'échelle UMUX (Usability Metric for User Experience) qui comprend quatre items.
Lewis et al. ont cherchés à réduire encore le questionnaire. Leurs recherches ont démontré qu'il était possible de réduire à deux items, le 1 et 3 pour un UMUX-LITE.
Le questionnaire
L’UMUX-Lite s’articule sur deux questions très simples et une échelle de réponse de 1 à 7 :
- Est-ce que (cette app / ce service) réponds à mes besoins ?
- Est-ce que (cette app / ce service) est facile d’utilisation ?
Pour calculer votre score global UMUX Lite, appliquez cette formule :
(Q1_Score + Q2_Score - 2) * 100 / 12
Présentation des résultats
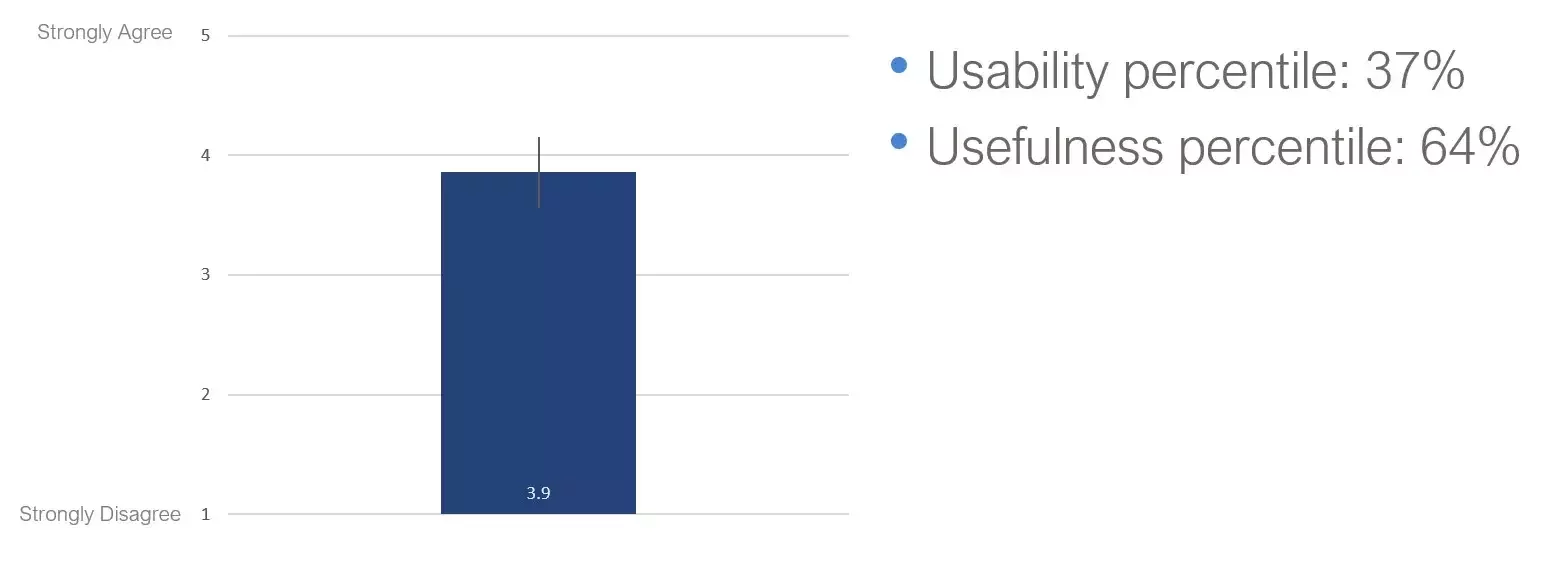
Présentation des résultats
Compatibilité SUS
Les réponses récoltées sont facilement comparables au questionnaire SUS classique.
Tout en étant pourtant extrêmement court et rapide à remplir, ce qui assure un taux de réponses beaucoup plus élevé.
Avec vos résultats, vous pouvez retrouver l’équivalent SUS en appliquant cette formule :
0.65 * (([Q1_Score] + [Q2_Score] — 2) * 100 / 12 + 22.9
DEEP
Le Diagnostic End-User Experience Problems a été développé afin de pallier au défaut des principales autres échelles qui ne permettent pas d'identifier le Pourquoi. L'ambition du DEEP est de mesurer :
- La manifestation de l'expérience de l'utilisateur, que les auteurs nomment le « phénotype de l'utilisabilité ».
- L'origine du problème dans l'interface, appelé le « génotype de l'utilisabilité ».
Une échelle complète
Le DEEP s'appuie sur la combinaison d'items extraits et adaptés d'autres échelles : PHUE, CSUQ, QUIS, SUS, PUTO, USE et WAMMI. Certains items ont également été inspirés de la méthode d'inspection de l'utilisabilité MiLE+.
L'échelle est ainsi constituée de dix-neuf items sous forme de phrases affirmatives, réparties en six catégories.
DEEP est conçu pour évaluer un site web.
Le questionnaire
Avantages de DEEP
- Permet d'identifier où dans les grandes catégories sont les faiblesses UX du produit.
- Permet de facilement prioriser les améliorations à faire en fonction de thématique. (Ex : La Cohérence de la solution est trop faible)
Attention par contre à son temps de réalisation et d'analyse qui est bien supérieur aux autres échelles.
CSUQ
Computer System Usability Questionnaire est dérivé de l'échelle PSSUQ (Post Study System Usability Questionnaire, première version en 1992), dont elle reprend exactement les mêmes items mais dans une formulation au présent pour ne pas juste dépendre d'un test utilisateur.
Le CSUQ se présente sous deux formes : une version originale à 19 items et une version courte à 16 items.
Aujourd'hui on utilise la version courte.
Le questionnaire
Avantages de CSUQ
- Le questionnaire est utilisable sur tout type de produit digital. (Site internet, mobile, logiciel...)
- Il possède 3 dimensions :
- 1 à 8 : Utilité du système.
- 9 à 15 : Qualité des informations.
- 16 à 18 : Qualité de l'interface.
- 19 étant pour le score global.
Attention cependant à sa longueur, qui doit être utilisé sur des utilisateurs prêt à passer du temps sur le questionnaire.
Les résultats
| Dimensions | Score moyen (sur 7) |
|---|---|
| Utilité du système | 5.8 |
| Qualité des informations | 4.9 |
| Qualité de l'interface | 6.2 |
| Score global | 6 |
Ou sous la forme d'un graphique Radar comme DEEP.
ASQ
L'After-Scenario Questionnaire est une échelle à trois items issue des travaux de l'équipe d'utilisabilité d'IBM. Elle est présentée aux utilisateurs après chaque scénario accompli au cours d'un test utilisateur et non pas à l'issue de tous les scénarios comme c'est souvent le cas.
Elle permet de quantifier rapidement l'usabilité d'une section d'un test utilisateur.
Le questionnaire
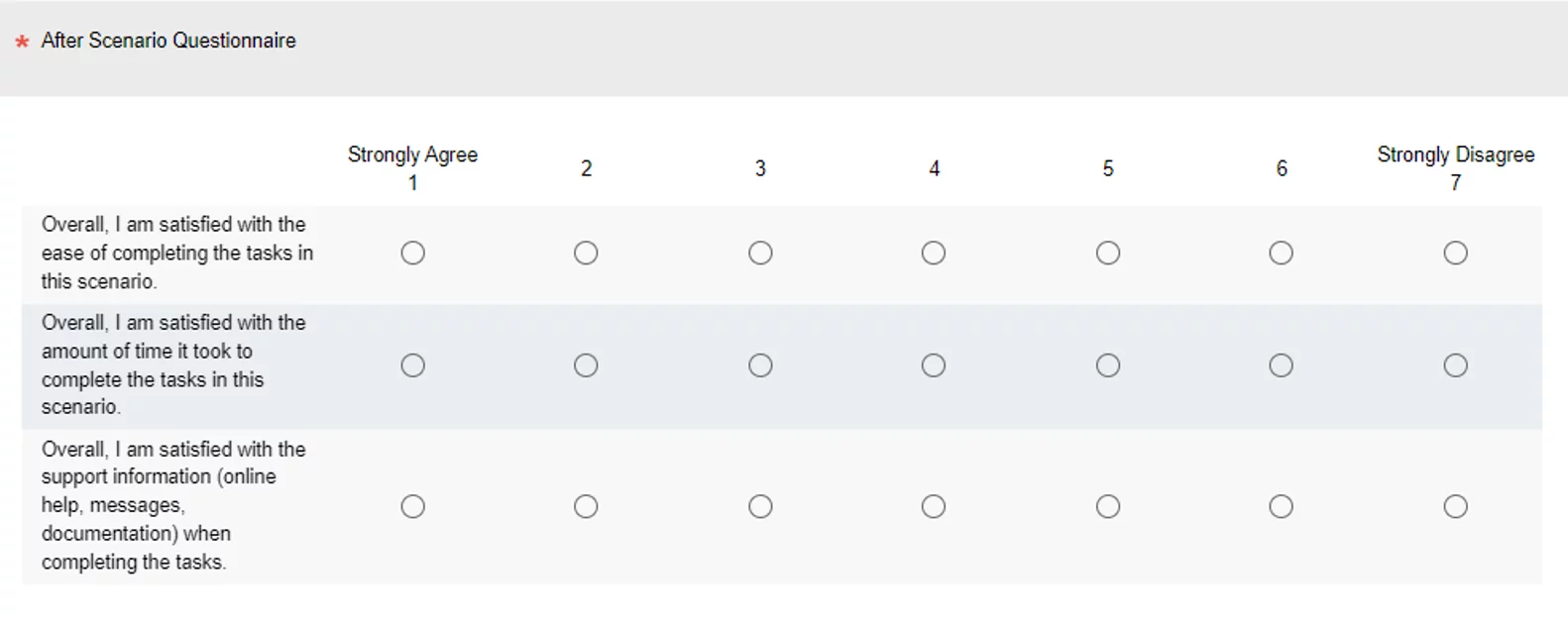
Les résultats
| Scénario | Facilité | Temps | Support | Moyenne |
|---|---|---|---|---|
| Créer un compte | 2,1 | 2,5 | 2,0 | 2,2 |
| Modifier un profil | 3,8 | 4,2 | 3,5 | 3,8 |
| ... | ... | ... | ... | ... |
En résumé
| Échelles | Temps | Cible |
|---|---|---|
| SUS | Rapide (10 items) | Tout type de système |
| UMUX-Lite | Ultra rapide (2 items) | Tout type de système |
| DEEP | Long (~20–30 items selon les versions) | Évaluations stratégiques, benchmarks produits sur site internet |
| CSUQ | Long (19 items) | Systèmes complexes |
| ASQ | Ultra rapide (3 items) | Tout type de système (Après chaque scénario) |
Nous verrons plus tard comment le bon questionnaire en fonction de la situation.
Questionnaires UX
2.3
Évaluer l'expérience utilisateur
Vers le début des années 2000, on reconnaît officiellement qu’il ne suffit plus d’évaluer l’utilisabilité seule : il faut aussi mesurer les dimensions émotionnelles, motivationnelles et contextuelles de l’expérience utilisateur.
Donald Norman popularise l’expression user experience (1993 chez Apple) puis Marc Hassenzahl, Klaus Thüring et d’autres chercheurs qui introduisent la distinction entre aspects pragmatiques (utilisabilité) et aspects hédoniques (émotions, stimulation, identification).
AttrakDiff
Créé par Marc Hassenzahl et ses collaborateurs Burmester et Koller en 2003, AttrakDiff est une échelle UX holistique qui évalue, en un seul questionnaire, à la fois les dimensions :
- pragmatiques - utilité, efficacité
- hédoniques - plaisir, stimulation
Simple, rapide et polyvalente, elle s’applique à tout type de produit ou service.
Pourquoi utiliser AttrakDiff ?
L’AttrakDiff analyse la qualité des interactions entre l’utilisateur et le système tels que l’attractivité, l’utilisabilité, la désirabilité, l’ergonomie et l’accessibilité selon différentes perspectives de l'utilisateur :
- Son ressenti, ses perceptions et ses pensées.
- Le contexte d’utilisation du dispositif interactif.
L'échelle est validé scientifiquement, ce qui signifie qu’elle aboutit à des résultats fiables qui reposent sur des critères parfaitement testés.
Pourquoi utiliser AttrakDiff ?
Evaluation unique : cette méthode débouche sur un score unique de l’analyse UX d’un dispositif interactif.
Comparaison produit A – produit B : elle offre une analyse comparative de l’UX entre deux produits.
Comparaison avant/après : elle analyse l’UX du produit avant et après l’application de certaines optimisations.


Les échelles de l'AttrakDiff
Elle contient 28 éléments étalés sur 4 échelles :
- Qualité pragmatique (QP) : elle évalue l’utilisabilité du produit et à quel point il est facile pour l’utilisateur d’atteindre son objectif. (do-goals)
- Qualité Hédonique Stimulation (QHS) : elle décrit à quel niveau le produit stimule l’utilisateur, à travers ses fonctionnalités et sa valeur ajoutée. Donc, un produit stimulant est un produit créatif, captivant, original, conventionnel, etc.
- Qualité Hédonique Identité (QHI) : elle définit à quel niveau le produit s’aligne à l’identité de l’utilisateur. Le produit est adapté aux besoins de ce dernier et est parfaitement conçu pour lui.
- Attractivité globale (ATT) : Elle apporte une vision globale de l’attractivité du produit, tout en se basant sur les qualités pragmatiques et hédoniques.
Le questionnaire
meCUE
Inventé par Minge et Riedel en 2013. Il est basé sur le modèle théorique de Thüring et Mahlke (2007). Il comporte 34 éléments ventilés en 4 modules :
- La perception du produit : évaluer les valeurs de l’efficacité, d’utilisabilité, d’esthétique, d’engagement et du statut du produit. (15 items)
- Les émotions : évaluer les émotions négatives et positives de l’utilisateur. (12 items)
- Les conséquences de l’usage : évaluer le niveau d’identification de l’usager du produit à lui-même. (intention d'usage) (6 items)
- L’évaluation globale : évaluer de manière globale la performance du produit
Le questionnaire
En résumé
- AttrakDiff : rapide, clair, orienté comparaison et communication.
-
meCUE : plus riche, analytique, adapté aux recherches approfondies et aux suivis dans le temps.
AttrakDiff en version courte sera plus intéressant pour cibler des utilisateurs n'ayant pas beaucoup de temps alors que meCUE sera un très bon outil pour de la recherche UX avec des volontaires pour des expérimentations.
Choisir la bonne échelle
2.4
Comment mesurer l'expérience utilisateur via une échelle ?
Choisir la bonne échelle en fonction de votre situation.
Choisir le mode de passation : papier ou numérique ?
Recruter les utilisateurs cibles : définir l'échantillon.



Comment choisir l'échelle ?
Quel est le type de système que vous souhaitez évaluer ?
Quelle est la disponibilité de vos utilisateurs ?
Souhaitez-vous obtenir un retour sur certaines caractéristiques de votre système ou la globalité ?



Selon l'objectif du projet
| Objectif | Échelles |
|---|---|
| Mesurer l’utilisabilité globale | SUS, UMUX-Lite |
| Identifier les problèmes précis d’UX | DEEP / CSUQ (Utilisabilité), meCUE (UX) |
| Évaluer l’expérience au-delà de l’utilisabilité | AttrakDiff, meCUE |
| Mesurer la charge mentale | NASA-TLX, SMEQ/RSME |
| Communiquer une note simple et rapide à collecter aux décideurs | UMUX-Lite ou AttrakDiff court |
Selon la cible du projet
| Cible | Échelles |
|---|---|
| Grand public / utilisateurs peu familiers | SUS, UMUX-Lite, SMEQ, AttrakDiff court |
| Utilisateurs professionnels | CSUQ, EUCS, meCUE, NASA-TLX |
| Participants à une étude académique / recherche UX avancée | meCUE |
Selon la temporalité du projet
| Temporalité | Échelles |
|---|---|
| Phase exploratoire / avant conception | AttrakDiff court ou UES |
| Pendant la conception / tests itératifs rapides | SUS, UMUX-Lite ou AttrakDiff court |
| Évaluation avant lancement (benchmark) | SUS, UMUX-Lite, AttrakDiff ou meCUE |
| Suivi longitudinal / post-lancement | meCUE, AttrakDiff ou UES |
Comment calculer l'échantillon nécessaire d'une échelle ?
-
z1−α/2z_{1-\alpha/2}z1−α/2 est la valeur de la loi normale pour ton niveau de confiance (ex. 1,96 pour 95 %),
-
σ\sigmaσ est l’écart-type attendu,
-
EEE est la marge d’erreur souhaitée.
Comment calculer l'échantillon nécessaire d'une échelle ?
Repères pratiques (si il n’y a pas de pilot) :
-
UMUX-Lite (échelle 1–7) : σ≈1.0\sigma \approx 1.0σ ≈ 1.0 à 1.1.
-
UMUX-Lite en SUS-équivalent (0–100) : σ≈12\sigma \approx 12σ ≈ 12 à 13 (proche du SUS).
-
AttrakDiff (-3 à +3) sur une dimension agrégée : σ≈0.6\sigma \approx 0.6σ≈0.6 à 0.8.
Comment calculer l'échantillon nécessaire d'une échelle ?
Exemples rapides :
-
UMUX-Lite (1–7), marge d'erreur ±0,3 :
n≈(1,96×1,1/0,3)2≈52n \approx (1{,}96\times1{,}1 / 0{,}3)^2 \approx 52n ≈ (1,96×1,1/0,3)^2 ≈ 52. -
UMUX-Lite (SUS-eq 0–100), marge d'erreur ±5 points :
n≈(1,96×12,5/5)2≈24n \approx (1{,}96\times12{,}5 / 5)^2 \approx 24n ≈ (1,96×12,5/5)^2 ≈ 24. -
AttrakDiff (-3..+3), viser ±0,2 sur PQ :
n≈(1,96×0,7/0,2)2≈47n \approx (1{,}96\times0{,}7 / 0{,}2)^2 \approx 47n ≈ (1,96×0,7/0,2)^2 ≈ 47.
C'est l'heure de la pratique !
2.5
Exercice 1 - DEEP
Il est l'heure de s'entraîner pour mesurer l'utilisabilité !
Réalisez un questionnaire DEEP selon votre propre perception d’un site internet que vous
venez de visiter, puis analysez les résultats.
Appelez-moi pour que l'on puisse vérifier ensemble.
Exercice 2 - AttrakDiff
Il est l'heure de s'entraîner pour mesurer l'expérience utilisateur !
Réalisez un questionnaire AttrakDiff selon votre propre perception d’une solution que vous utilisez fréquemment, puis analysez les résultats.
Appelez-moi pour que l'on puisse vérifier ensemble.
Livrable à rendre
En tant qu’agence UX, vous recevez une demande d’un client potentiel : Netflix souhaite réaliser un benchmark UX de ses concurrents afin d’évaluer si une augmentation des prix est envisageable.
Choisissez un questionnaire, recueillez les réponses d’un échantillon d’une dizaine de personnes et comparez l’expérience de Netflix à celle d’un concurrent. Analysez ensuite les résultats.
Vous devrez présenter votre démarche et vos conclusions pour la prochaine fois en 15 minutes.
Évaluer les émotions des utilisateurs
3.
Qu'est-ce qu'une émotion ?
L'émotion est un concept psychologique complexe et de nombreux débats animent la communauté scientifique sur la nature ou la définition des émotions.
Pour Darwin, les émotions sont la base de la faculté d'adaptation et de survie de l'être humain.
L'émotion renvoie souvent à un épisode affectif court mais intense, qui est déclenché par un stimulus externe ou interne.
Pourquoi évaluer les émotions ?
Un événement vécu ou un souvenir peut déclencher une réaction émotionnelle. Il y a donc un facteur causal dans l'émotion.
Au-delà du sentiment subjectif, l'émotion est un processus complexe qui se manifeste également par des changements d'état aux niveaux cognitif, psychophysiologique, motivationnel et moteur.
Évaluer les émotions permet de trouver un moyen de réduire les émotions négatives et d'amplifier les positives dans une expérience utilisateur.
Différence avec l'humeur ?
L'humeur en revanche n'est pas (consciemment) tournée vers un objet particulier. On peut se sentir de mauvaise humeur sans savoir vraiment pourquoi.
Elle renvoie donc plutôt à la présence silencieuse de niveaux d'affects d'intensité faible ou modérée.
Les états affectifs relevant de l'humeur vont être présents sur une durée plus longue qu'une émotion, mais restent limités dans le temps.
Différence avec l'affect ?
L'affect est une notion plus générale, une tendance, qui désigne le ressenti (préférences, aversions) qu'une personne a envers un objet, une situation ou une personne.
Émotions et humeurs sont des types particuliers d'affects.
L'émotion comme fixateur de mémoire
Quels souvenirs gardez-vous du mois dernier ?
De l'année dernière ?
Il y a fort à parier que ce sont des souvenirs liés à des situations qui ont provoqué chez vous de l'émotion.
Les recherches ont montré que les émotions, même modérées, facilitent la mémorisation.
Plusieurs phénomènes sont impliqués dans ce processus :
L'encodage, la consolidation et le rappel.
Comment améliorer la mémoire par l'émotion ?
Tout d'abord, l'émotion, positive ou négative, va augmenter l'attention et l'élaboration cognitive de l'information qui sera confiée à la mémoire. C'est la toute première étape pour que l'information soit conservée ; elle doit être captée.
Ensuite, elle est consolidée, c'est-à-dire que la trace mnésique peut être renforcée ou non. Encore une fois, les émotions jouent un rôle dans ce processus de consolidation, tout simplement car elles stimulent la rumination mentale et le partage social.
Plus l'émotion est forte, plus on retient ?
Attention, pour que l'émotion joue un rôle d'amplification de la mémoire, il faut qu'elle soit légère ou modérée. Dans le cas d'une émotion forte, nous pouvons oublier certains éléments du contexte.
Ex: le cas d'un accident où la victime aura du mal à se souvenir de la situation complète.
Exemple d'une expérience
Le psychologue Stephan Hamann a réalisé une expérience dans laquelle il présentait des mots et des images, dont une moitié était émotionnellement neutre et l'autre chargée en émotion.
Cette dernière catégorie stimulait la partie du cerveau appelée amygdale, centre des émotions.
Les participants se souvenaient de deux fois plus de mots et d'images que pour la catégorie émotionnellement neutre.
En résumé
- Une situation qui va induire une émotion légère à modérée sera mieux remémorée.
- Une information encodée dans un contexte d'émotion positive sera mieux rappelée dans un futur contexte positif; il en va de même pour une information négative.
- Plus une information est pertinente ou rare, mieux elle sera mémorisée.
- Proposez une expérience émotionnelle positive à l'aide d'une expérience sensorielle exceptionnelle, ou en étant très pertinent ou surprenant, ou encore en humanisant vos interfaces.
La cartographie des émotions
3.1
Les émotions primaires
Les émotions primaires sont des émotions universelles, biologiquement programmées, présentes chez tous les humains (et parfois observées chez certains animaux). Elles sont :
- rapides (réponses immédiates),
- automatiques (peu contrôlées consciemment),
- universelles (partagées à travers cultures et langues) et associées à des expressions faciales et physiologiques spécifiques.
Elles constituent la brique de base sur laquelle se construisent les émotions plus complexes ou secondaires.
Les émotions primaires
Paul Ekman (1982), propose 6 émotions de base universelles, identifiables par l’expression faciale :
2 positives : Joie, Surprise.
4 négatives : Tristesse, Colère, Peur, Dégoût.

La cartographie des émotions
Les autres émotions sont des états mixtes ou dérivés, c’est-à-dire des mélanges, composés ou combinaisons d’émotions de base.
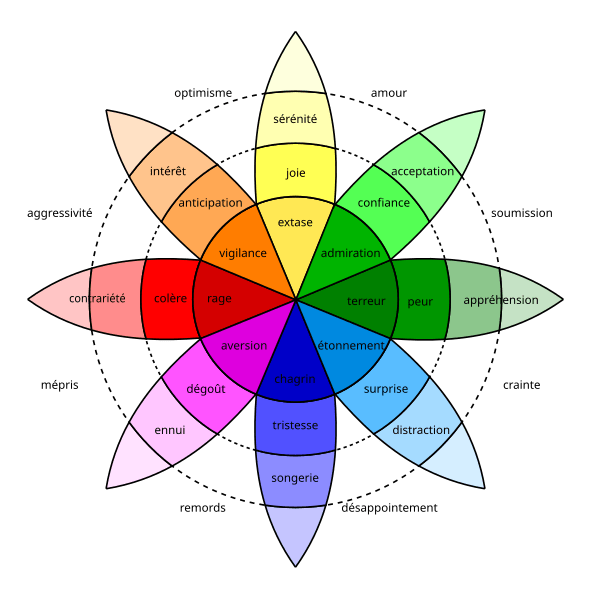
Dans la roue des émotions de Plutchik (1980) le cercle et la palette de couleurs représentent l’idée que les émotions se combinent les unes et autres et s’expriment selon différents niveaux d’intensité.
La roue GEW
Plus scientifique et validée expérimentalement : 20 émotions représentées sur une roue, réparties en valence positive/négative et degré de contrôle.
Les participants choisissent une émotion et la notent en intensité.
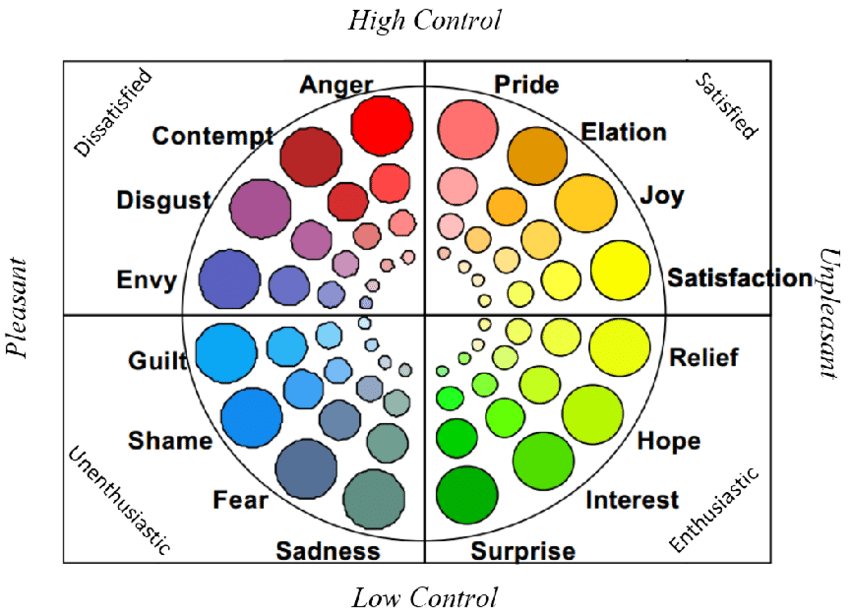
Pourquoi cartographier en UX ?
- Cartographier les émotions ressenties pendant l’usage :
- Identifier les pics émotionnels dans un parcours (ex. frustration lors d’un paiement).
- Réaliser une User Journey Map avec la composante d'émotion pour adapter le système aux émotions de l'utilisateurs.
- Méthode standardisée pour capturer les émotions subjectives.
- Utilisée en recherche académique (laboratoires, ergonomie) pour quantifier réellement les émotions ressenties.
Perspectives modernes
Certains chercheurs (p. ex. Lisa Feldman Barrett, 2006–2017) contestent l’idée de “basic emotions fixes”. ils parlent d’émotions construites culturellement et contextuellement.
Mais pour l’UX et la psychologie appliquée, les modèles Ekman et Plutchik restent des références pratiques.
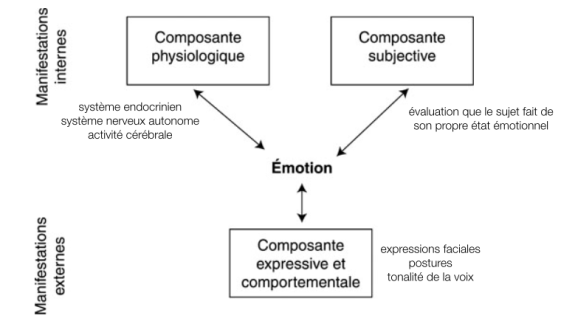
Les trois composantes de l’évaluation des émotions
3.2
Le diagramme des trois composantes
Évaluer la composante physiologique - 1
Les émotions déclenchent des réponses physiologiques automatiques du système nerveux autonome, Les principaux indices physiologiques mesurables de l'émotion sont :
-
la réponse ou conductance électrodermale : activité des glandes sudoripares de la paume de la main.
-
la fréquence cardiaque : variations électriques issues de la contraction des muscles du cœur, dont l'électrocardiogramme rend compte ;
-
la fréquence respiratoire : nombre de cycles respiratoires durant une minute, mesurés par exemple via une ceinture thoracique ;
Évaluer la composante physiologique - 2
- l'électroencéphalographie : activité électrique du cerveau mesurée par des électrodes posées sur le cuir chevelu.
Globalement, les mesures physiologiques ont pour avantage de tracer les réactions émotionnelles de manière non invasive et « objective ».
Objectif et limites
Obtenir une mesure non consciente des émotions.
Limites :
- Coûteux (capteurs, labo).
- Données difficiles à interpréter seules (stress ≠ forcément négatif).
- Peut être intrusif en fonction des capteurs portés par l’utilisateur.
Les indicateurs de la composante physiologique
- Fréquence cardiaque (HR, HRV) : augmentation en cas de stress, peur.
- Fréquence respiratoire : accélérée en cas d’anxiété.
- Conductance électrodermale (GSR/EDA) : mesure de la transpiration, corrélée à l’excitation émotionnelle.
- Électroencéphalogramme (EEG) : mesure de l’activité cérébrale, permet de distinguer valence (positive/négative).
Évaluer la composante comportementale
Un schéma musculaire spécifique correspond à chaque émotion. Deux techniques principales servent à évaluer les émotions sur la base des expressions faciales.
-
Le Facial Action Coding System (FACS) : consiste à coder la contraction des muscles faciaux sur la base d'unités d'action standardisées (au nombre de 46). Dans le cas de la joie par exemple, ce sont les unités d'action 6 (remontée des joues) et 12 (étirement du coin des lèvres) qui sont activées.
-
L'électromyographie : mesure la tension des muscles du visage par enregistrement du courant électrique.
Les logiciels d'analyse
Plusieurs logiciels (par exemple Facereader ©) intègrent le système de codage FACS et proposent d'identifier automatiquement les expressions faciales de l'utilisateur à partir d'une webcam.
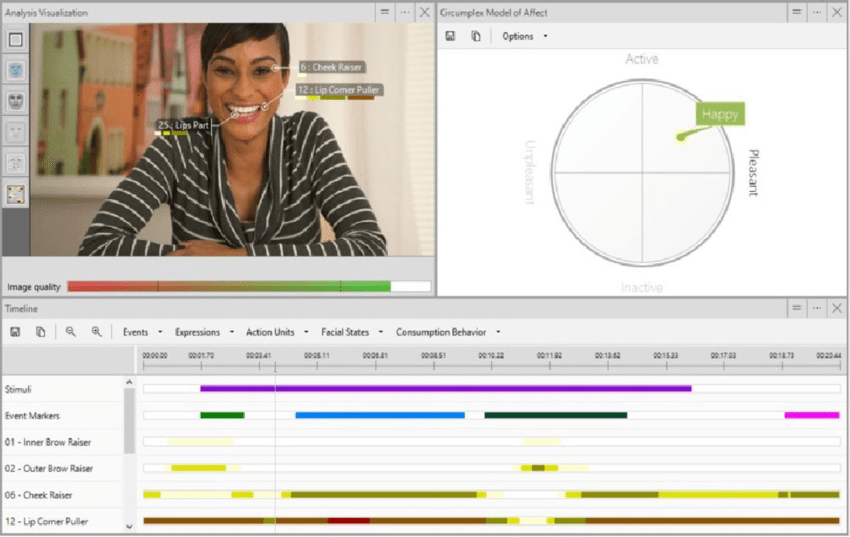
Évaluer la composante subjective
Ici c'est utilisateur qui va consciemment évaluer ses émotions. La composante subjective de l'émotion est estimée à l'aide de deux types d'instruments d'auto-évaluation :
- Dimensions émotionnelles : l'émotion peut être appréhendée par trois dimensions: le plaisir, l'activation et la dominance (ou contrôle). Ces dimensions sont indépendantes et bipolaires.
- Émotions discrètes : on présente au sujet des labels émotionnels, adjectifs, images ou phrases. Le sujet doit évaluer, à l'aide d'échelles, le degré avec lequel il ressent l'émotion proposée.
Comment évaluer la composante subjective ?
Plusieurs échelles existent mais une est particulièrement utilisé dans le contexte UX :
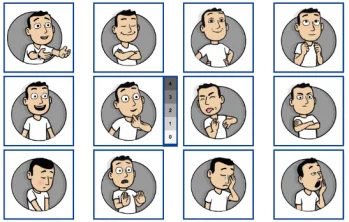
PrEMO (Desmet, Hekkert, & Jacobs, 2000 ; https://www.premotool.com/) est une échelle non-verbale de mesure des émotions discrètes.
Contrairement aux échelles SAM ou PANAS qui ont été crées par des psychologues, PrEMO a été créé spécifiquement pour l’étude des émotions liées à l’interaction avec des systèmes et produits.
Comment fonctionne PrEMO ?
Douze émotions sont représentées par des personnages de cartoon animés avec du son.
Les utilisateurs évaluent à quel point ils ressentent chacune des émotions, sur une échelle allant de 0 à 4.
Tout comme SAM, PrEMO est indépendant du langage et de la culture.
Objectif et limites
Recueillir l’expérience vécue du point de vue utilisateur.
Limites :
- Risque de biais (mémoire, désirabilité sociale).
- Dépend du vocabulaire émotionnel de l’utilisateur.
- Pas toujours en temps réel (post-tâche).
Les échelles de la composante subjective
- PANAS (Positive and Negative Affect Schedule) : mesure affect positif vs affect négatif.
- PrEmo : échelle pictographique, permet aux participants de sélectionner des émotions représentées par des personnages animés.
- SAM (Self-Assessment Manikin) : pictogrammes représentant valence (plaisir), arousal (intensité), dominance (contrôle).
- GEW / Plutchik (vus avant) : également utilisés en composante subjective.
Des questions ?
Mesurer et analyser l’expérience utilisateur
4.
Les tests utilisateurs
4.1
Qu'est-ce qu'un test
utilisateur ?
L'utilisateur est invité à réaliser un ensemble de tâches prédéfinies par l'équipe de conception. Ses interactions avec le système sont observées et analysées par au minimum deux UX Designers.
Les tests utilisateurs sont une méthode centrale pour évaluer l’expérience d’usage d’un produit ou d’un service. Ils permettent de mesurer l’utilisabilité et d’identifier les points de friction dans l’interaction.
Pourquoi réaliser un test utilisateur ?
Identifier les problèmes dans la conception du produit ou du service
Déceler des opportunités d’amélioration
Mieux comprendre le comportement et les préférences des utilisateurs cibles

Pourquoi faut-il des tests utilisateurs ?
Un bon designer UX ne devrait-il pas savoir créer une excellente interface utilisateur ?
Même les meilleurs designers UX ne peuvent pas concevoir une expérience parfaite — ou même simplement “suffisamment bonne” — sans un processus itératif basé sur l’observation des vrais utilisateurs et de leurs interactions avec le design.
La conception d’une interface moderne implique de nombreuses variables, et il y en a encore plus dans le cerveau humain. Le nombre total de combinaisons possibles est immense.
La seule façon de réussir un design UX est de le tester.
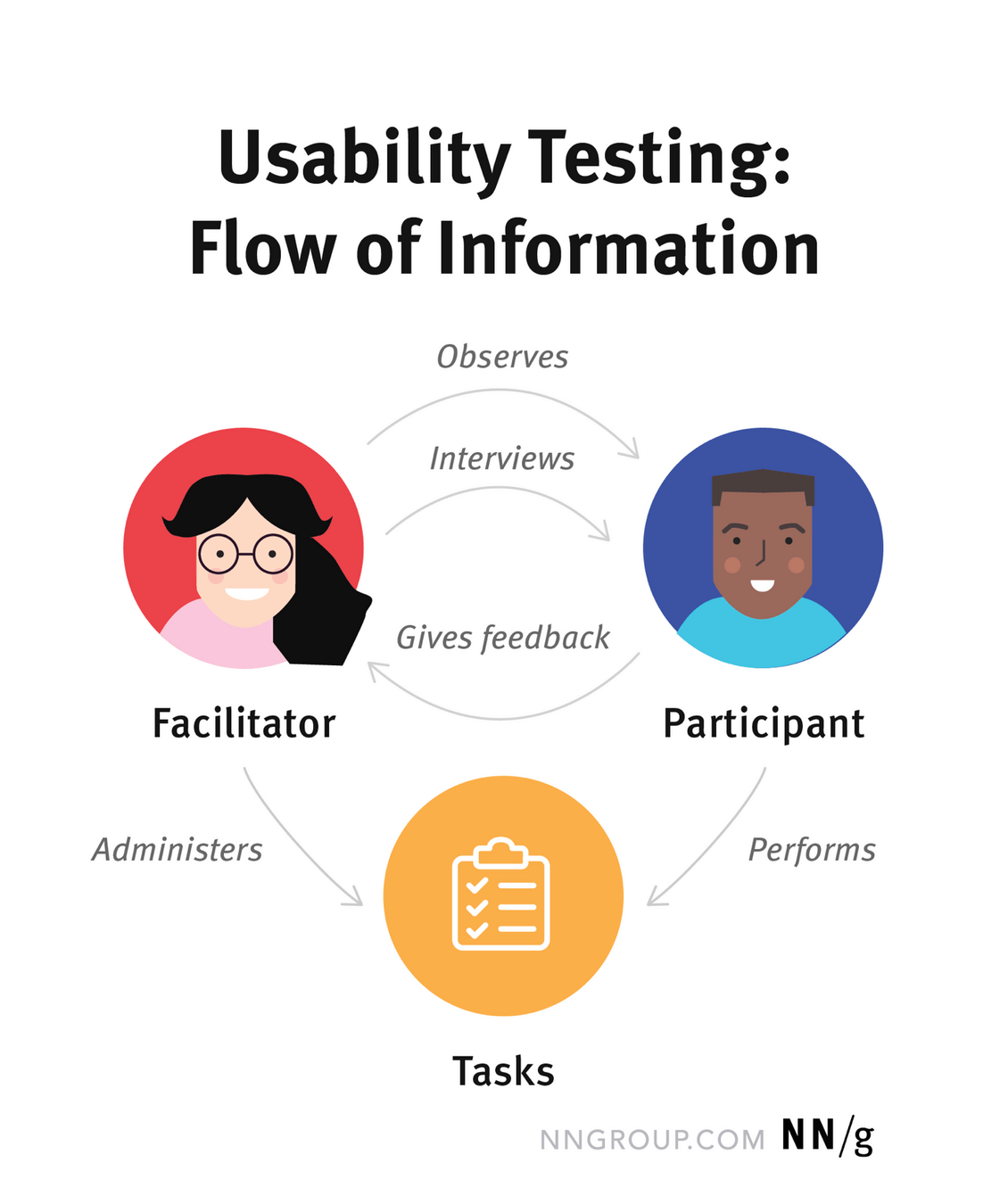
Comment réaliser un test utilisateur ?
Créer un échantillon de 3 à 6 utilisateurs en fonction de votre persona.
Désigner un facilitateur qui gère le test et un observateur qui prends note.
Un protocole de test et des ressources pour cadrer les tâches à réaliser par le testeur.
Comment réaliser un test utilisateur ?
Pourquoi un échantillon de 5 utilisateurs ?
Le rôle du Facilitateur
Donne les instructions, répond aux questions et pose des questions complémentaires.
S’assure que le test produit des données de qualité et valides, sans influencer accidentellement le comportement.
Suit le protocole de test pour garder les mêmes conditions d'un test à l'autre.
Le rôle de l'Observateur
Suit les interactions du participant avec le produit ou le service.
Valide ou invalide les étapes du protocole en fonction des interactions du participant.
Rédige des notes sur les retours à l'oral ou les blocages du participant.
Le rôle du Participant
Être un utilisateur existant ou bien quelqu’un ayant un profil similaire au groupe cible, partageant les mêmes besoins.
Les participants sont invités à penser à voix haute : ils décrivent leurs actions et leurs pensées.
L’objectif est de comprendre leurs comportements, objectifs, pensées et motivations.

Les tâches
Les tâches d’un test d’utilisabilité sont des activités réalistes que le participant pourrait effectuer dans la vie réelle. Elles peuvent être très spécifiques ou ouvertes, selon les questions de recherche et le type de test.
Exemples de tâches issues d’études réelles :
- Votre imprimante affiche “Erreur 5200”. Comment pouvez-vous supprimer ce message d’erreur ?
- Vous envisagez d’ouvrir une nouvelle carte de crédit chez Wells Fargo. Rendez-vous sur wellsfargo.com et décidez quelle carte vous pourriez ouvrir, le cas échéant.
- On vous a demandé de parler à Tyler Smith du service de gestion de projet. Utilisez l’intranet pour trouver où il se situe. Indiquez votre réponse à voix haute.
Les tâches
Le libellé des tâches est très important. De petites erreurs de formulation peuvent amener le participant à mal comprendre ce qu’on lui demande ou influencer sa manière d’accomplir la tâche (phénomène psychologique appelé priming).
Les instructions peuvent être données à l’oral (le facilitateur les lit) ou sur une fiche de tâches remise au participant.
On demande souvent aux participants de lire les instructions à voix haute, afin de s’assurer qu’ils les ont bien comprises et d’aider les chercheurs à suivre le déroulé du test.
Exemple d'un test utilisateur
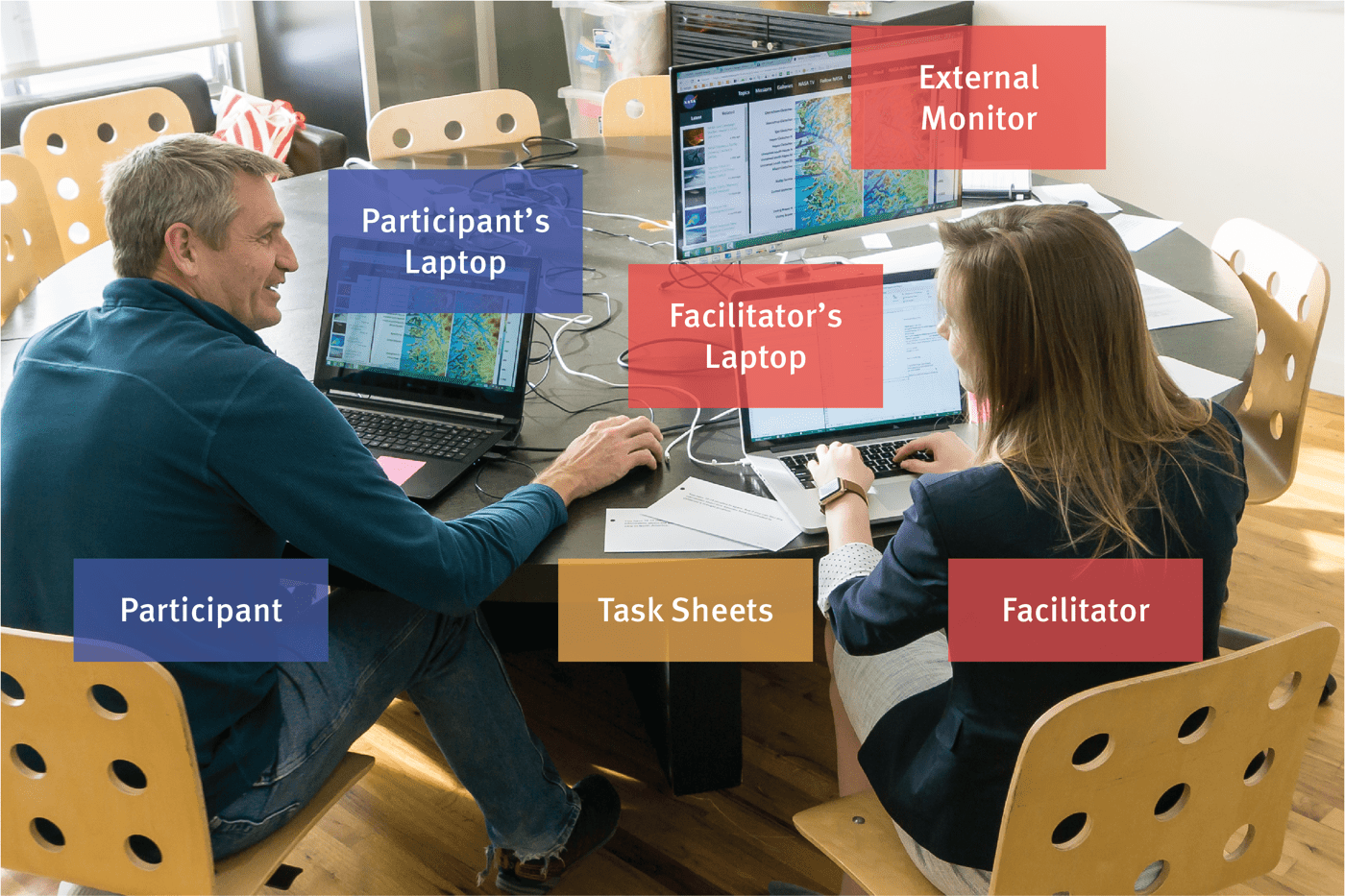
Exemple d'un test utilisateur
Dans une session de test où il n'y aurait qu'un facilitateur : le participant est assis à gauche, le facilitateur à droite. Le participant utilise un ordinateur portable spécial, équipé d’un logiciel d’enregistrement d’écran et d’une webcam pour capter ses expressions faciales.
L’écran est connecté à un moniteur externe pour le facilitateur, qui écoute les retours, administre les tâches et prend des notes.
Les types de tests utilisateurs
Les tests utilisateurs peuvent être conduits de différentes manières selon les objectifs et les contraintes du projet. On distingue quatre grandes catégories de tests :
- en situation contrôlée : en laboratoire de test.
- en contexte naturel : en situation réelle.
- à distance : via un outil. (visio ou pour réaliser un test non-monitoré)
- en mode guérilla : dans un lieu publique.
En situation contrôlée
Les tests d’utilisabilité visent à observer les interactions d’un utilisateur avec un système dans un environnement contrôlé, afin de limiter les distractions et les variables externes.
Traditionnellement menés en laboratoire d’utilisabilité, ces tests impliquent une séparation entre la salle de test et la salle d’observation, avec un enregistrement audio et vidéo des actions, expressions et verbalisations (méthode du think aloud).
Cependant, ces dispositifs, jugés coûteux et artificiels, ont évolué vers des tests “in sitro”, combinant la rigueur du laboratoire (in vitro) et le réalisme du terrain (in situ).
En contexte naturel
Le contexte physique et social influence fortement l’expérience vécue. Les tests en contexte naturel, menés sur le terrain (domicile, lieu de travail, espace public…), permettent d’observer l’utilisateur dans ses conditions réelles d’usage et évite le côté artificiel des labos.
L’objectif est de capturer l’expérience authentique. Ce mouvement, appelé “the turn to the wild”, affirme que l’évaluation doit se dérouler dans la vie quotidienne même où les technologies sont utilisées.
A distance
Retire la contrainte de la proximité géographique entre observateur et participant. Très utilisés aujourd’hui, ils facilitent la mobilisation rapide d’un grand nombre d’utilisateurs.
On distingue deux formes principales :
-
les tests synchrones, menés en temps réel par un évaluateur via un outil dédié ou une visioconférence ;
-
les tests asynchrones, automatisés, qui se déroulent sans supervision directe et permettent de tester plusieurs participants simultanément.
En mode guérilla
Les tests utilisateurs en mode guérilla sont des évaluations rapides et peu coûteuses, menées de façon informelle, souvent dans des lieux publics, auprès d’utilisateurs sollicités spontanément.
Cette approche allège la logistique et les coûts des tests classiques, mais elle présente des limites en termes de validité et de rigueur méthodologique.
Elle constitue donc une méthode complémentaire, utile pour des retours rapides, mais à privilégier avec prudence face aux tests plus structurés.
Test à distance non modéré
Contrairement aux tests en présentiel ou modérés, il n’y a pas d’interaction directe facilitateur–participant : le chercheur utilise un outil en ligne spécialisé pour configurer des tâches écrites destinées au participant.
Ensuite, le participant réalise ces tâches seul, à son rythme. L’outil de test délivre les instructions et éventuelles questions de suivi.
Une fois le test terminé, le chercheur reçoit l’enregistrement de la session ainsi que des métriques comme le taux de réussite des tâches.
Qualitatifs vs Quantitatifs
- Tests qualitatifs : se concentrent sur la collecte d’insights, d’observations et d’anecdotes sur l’usage du produit. Ils sont idéaux pour découvrir les problèmes d’expérience utilisateur. Les plus courants.
- Tests quantitatifs : visent à collecter des mesures chiffrées décrivant l’expérience (ex. taux de succès, temps de réalisation). Idéals pour établir des benchmarks.
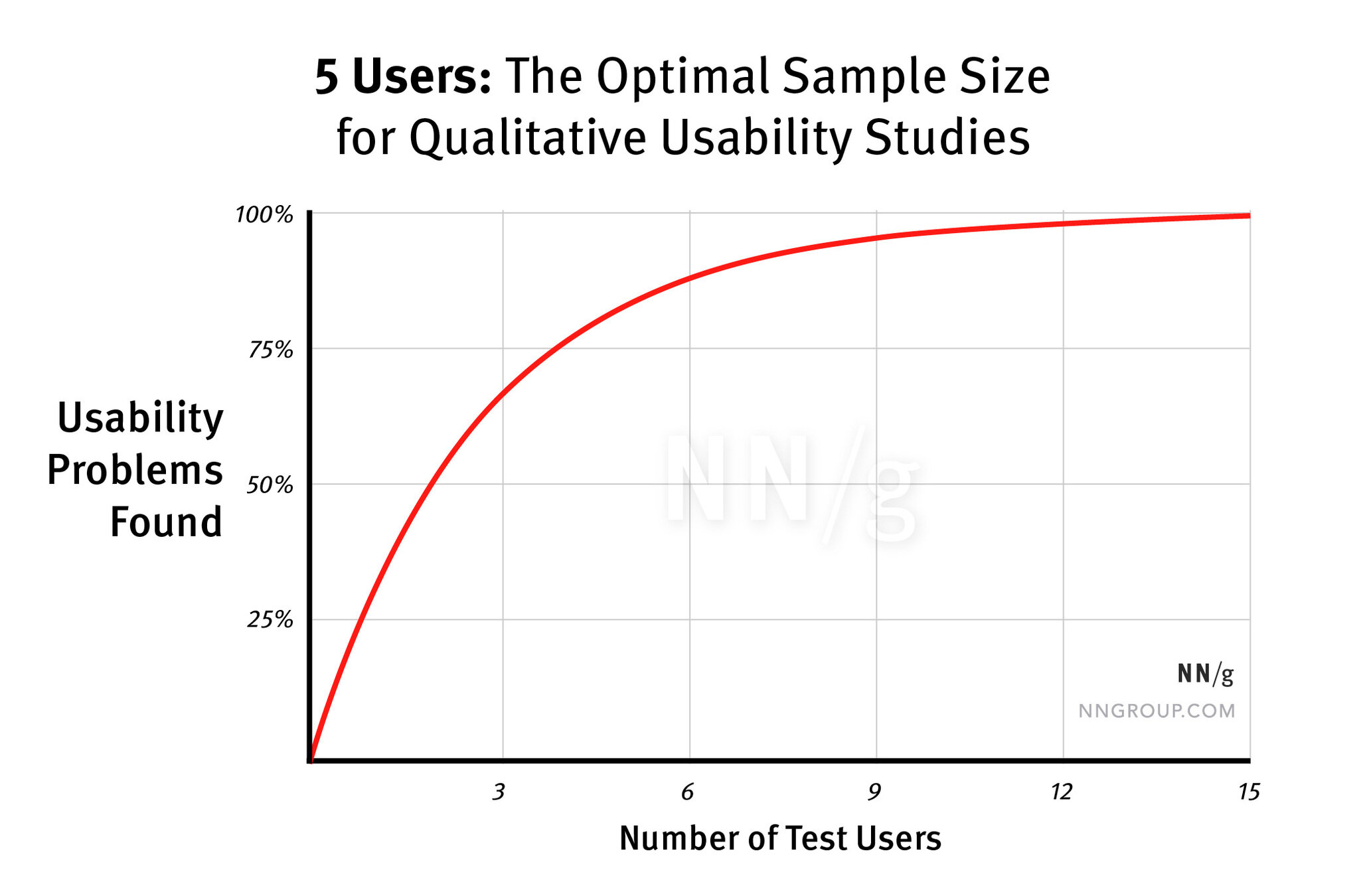
Le nombre de participants dépend du type d’étude :
Pour un test qualitatif classique sur un seul groupe d’utilisateurs, 5 participants suffisent généralement à identifier la majorité des problèmes récurrents.
Le coût d'un test utilisateur
Les études simples, dites “discount usability testing”, peuvent être peu coûteuses, même si vous devez généralement prévoir quelques centaines de dollars pour les incentives des participants. La session de test peut se dérouler dans une simple salle de réunion, et une étude basique prend environ 3 jours :
- Jour 1 : Planifier l’étude.
- Jour 2 : Tester avec 5 utilisateurs.
- Jour 3 : Analyser les résultats et les transformer en recommandations de redesign pour l’itération suivante.
À l’opposé, certaines recherches plus coûteuses sont parfois nécessaires, et le budget peut alors atteindre plusieurs centaines de milliers de dollars pour les études les plus complexes.
Facteurs qui augmentent les coûts
- Comparaison de plusieurs designs (competitive testing)
- Tests internationaux dans plusieurs pays
- Tests avec plusieurs groupes d’utilisateurs ou personas
- Études quantitatives
- Utilisation d’équipements sophistiqués comme l’eye-tracking
- Besoin d’un véritable laboratoire d’utilisabilité ou d’une salle d’observation type focus group
- Rédaction d’une analyse et d’un rapport détaillé des résultats
Qu'est-ce qu'un Goal-Based User Test ?
Consiste à définir clairement les objectifs de l’évaluation avant de choisir la méthode de test. Plutôt que de sélectionner une technique au hasard, on part de la question :
“Qu’est-ce que je veux apprendre de l’utilisateur, à ce stade du projet ?"
Exemple :
- Si je veux valider la compréhension d’une page d’accueil : test des 5 secondes.
- Si je veux mesurer l’efficacité d’un tunnel d’achat : test de parcours.
Quand utiliser un test ? - 1
| Méthode | Objectif | Contexte d'usage |
|---|---|---|
| Prototype Low-fi | Tester l’architecture, le flux | Early design |
| Guerrilla testing | Feedback rapide et économique | Early stage, validation rapide |
| Prototype Hi-fi | Tester interactions, esthétique | Pré-développement |
| Observations in situ | Comprendre l’usage réel en contexte | Produit existant / terrain |
| Test des 5 secondes | Vérifier la compréhension immédiate | Pages d’accueil, landing pages |
Quand utiliser un test ? - 2
| Méthode | Objectif | Contexte d'usage |
|---|---|---|
| Test de parcours | Mesurer efficacité, erreurs, satisfaction | Prototype fonctionnel / produit existant |
| A/B testing | Comparer deux versions sur un indicateur | Produit en production |
| Eye Tracking | Observer où l’utilisateur regarde et son attention | Analyse visuelle, optimisation UI |
Préparer un test utilisateur
4.2
Supports et objectifs pour test utilisateur - 1
| Objectif | Description | Support |
|---|---|---|
| Exploration | Tester le système dès la génération des premières solutions, afin d’identifier les problèmes de fond. | Maquettes |
| Évaluation | Tester le système dans une version suffisamment fonctionnelle pour simuler l’exécution de tâches spécifiques auprès des utilisateurs. | Prototype fonctionnel |
| Validation | Tester le système dans sa version finale, avant la mise sur le marché, afin de vérifier qu’il répond bien aux exigences de qualité attendues. | Prototype final |
Supports et objectifs pour test utilisateur - 2
| Objectif | Description | Support |
|---|---|---|
| Comparaison | Tester plusieurs alternatives d'un même système, ou plusieurs Maquettes, systèmes comparables entre eux, afin d'identifier les forces et faiblesses de chaque produit | Maquettes, prototypes, produits finaux |
| Amélioration continue | Évaluer la conformité du système avec les besoins du marché dans un processus d'amélioration continue | Produit sur le marché |
Planifier
Avant toute chose, vous devrez sélectionner le type de test le plus adapté à vos besoins. Rappelez-vous également qu'un test est un « éco-système» combinant plusieurs méthodes.
Planifier des sessions de tests implique de réfléchir à la construction cohérente d'un plan de test et d'un protocole, qui décriront en détail le déroulement des passations.
Réalisez un audit au préalable pour corriger les problèmes les plus évidents et ainsi mieux exploiter les bénéfices des tests utilisateurs.
Définir les scénarios d'usage
Ils simulent des actions représentatives des buts utilisateurs et doivent donc être élaborées avec soin. Plusieurs types de scénarios sont possibles :
- Les scénarios d'usage représentent les buts principaux des utilisateurs (ex. procéder à un achat sur un site d'e-commerce, naviguer vers un lieu grâce à un GPS).
- Prioriser par les points les plus critiques déjà identifiés en amont.
- Utiliser des scénarios d'usages définis par les utilisateurs eux-même en réalisant une interview utilisateur pour préparer le test.
Le contenu d'un scénario
- Sont rédigés sous la forme d'objectifs à atteindre, chaque scénario comprenant un seul objectif.
- Ne décrivez pas les scénarios par une succession d'actions comme « cliquez ici » ou « ouvrez telle fenêtre ».
- Sont rédigés en phrases courtes et facilement compréhensibles.
- S'adressent directement à l'utilisateur par le pronom « vous ».
- Ne mentionnent pas dans leur formulation les labels précis utilisés sur le système testé.
- Indiquent les éléments additionnels nécessaires à la réalisation de la tâche (par exemple, des identifiants si l'utilisateur doit consulter l'espace personnel d'un site).
Bonne pratique d'un scénario
- Débutez par un scénario facile que tous les utilisateurs réussiront.
- Selon les aspects que vous souhaitez observer, vous pouvez aussi laisser quelques minutes au participant pour explorer librement le système et recueillir ainsi ses premières impressions spontanées.
- Les scénarios seront présentés aux utilisateurs par ordre croissant de difficulté et du plus générique au plus spécifique.
- Il est indispensable de pré-tester vos scénarios pour valider leur cohérence avant la passation effective du test et pour mesurer le temps nécessaire pour une passation.
Établir une grille d'observation
Doit contenir :
- les activités et tâches réalisées.
- le temps qu'il a fallu à l'utilisateur pour réaliser chaque tâche.
- la succession des différents écrans parcourus par l'utilisateur.
- les réussites et éléments qui ont provoqué de la satisfaction.
- les échecs, erreurs, pannes ou problèmes rencontrés.
- les commentaires des utilisateurs.
- des éléments d'observation libre rédigés par l'observateur (par exemple, la description de l'état émotionnel de l'utilisateur).
Une grille sera sous forme de tableau comme un fichier Excel ou une base de donnée Notion.
Recruter les utilisateurs
Être un utilisateur existant ou bien quelqu’un ayant un profil similaire au groupe cible, partageant les mêmes besoins.
Pour motiver les utilisateurs, on peut les dédommager ou leur donner un avantage avec le produit.
Réaliser une base de donnée de vos testeurs pour facilement les recontacter ou pour historique.


Passation - Durée
Un test utilisateur ne devrait pas durer plus de 90 minutes, accueil des participants et étape de débriefing inclus.
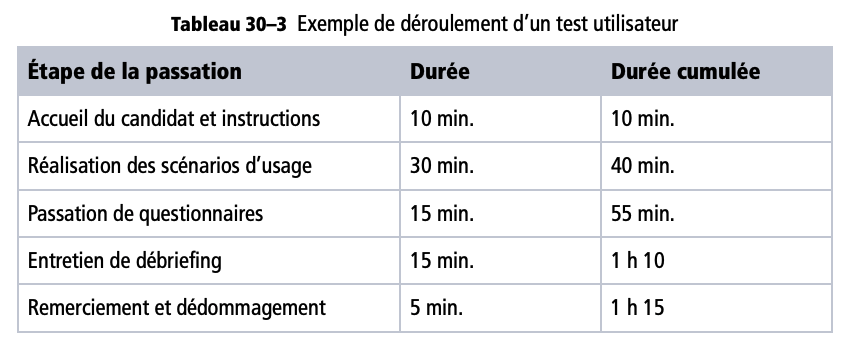
Passation - L'avant
La passation d’un test utilisateur commence par l’accueil et la mise en confiance du participant.
Le facilitateur doit expliquer le déroulement de la séance, faire signer le consentement éclairé, puis présenter les scénarios de tâches sous forme écrite, idéalement regroupés dans un petit fascicule pour faciliter le suivi.
Avant de commencer, il est essentiel de rappeler que c’est le système, et non l’utilisateur, qui est évalué, et de vérifier la bonne compréhension des consignes en répondant à toutes les questions du participant.
Passation - Pendant
Une fois les consignes données, laissez le participant consulter les scénarios de tâches et commencer à son rythme.
Selon le contexte, il peut être utile de mener un court entretien préalable pour identifier ses attentes vis-à-vis du système et les aspects de l’expérience utilisateur qui comptent le plus pour lui.
Pendant le test, laissez le participant agir sans intervention. Contentez-vous d’observer et de renseigner vos grilles d’observation, sans influencer son comportement.
Si vous partagez la même pièce, évitez tout commentaire ou réaction pouvant le perturber. En cas de blocage sur un scénario, invitez-le simplement à passer à la tâche suivante.
Passation - l'après
Le débriefing conclut la séance de test et vise à approfondir la compréhension de l’expérience utilisateur. Il s’appuie principalement sur l’entretien post-test, permettant de recueillir les perceptions, frustrations, points positifs et comparaisons avec d’autres systèmes.
On peut aussi proposer des tâches complémentaires ou utiliser des échelles d’utilisabilité et d’UX pour obtenir des données quantitatives.
Enfin, il est essentiel de vérifier le bien-être du participant, de le remercier et lui remettre la récompense prévue, tout en poursuivant l’enregistrement jusqu’à son départ, car les remarques spontanées de fin de séance sont souvent précieuses.
Passation - Bonnes pratiques
- Entre les passations, n’oubliez pas de remettre à zéro les éléments de votre système pour ne pas biaiser vos scénarios et votre recueil de données.
- Pour les systèmes complexes, confrontez lors de l’entretien de débriefing les utilisateurs aux enregistrements de leur passation. Cette auto-confrontation permet de recueillir des explications sur les actions réalisées, les erreurs commises et le ressenti de l’utilisateur.
- La technique de la co-découverte peut aider à recueillir des verbalisations plus naturelles et spontanées en situation contrôlée. Au lieu d’un seul utilisateur, ce sont deux utilisateurs (qui se connaissent) qui vont réaliser le test ensemble.
Analyser un test utilisateur
4.3
Analyser les résultats
Selon les métriques définies dans les objectifs du test, les résultats obtenus peuvent inclure :
- la proportion de succès et d’échecs pour chaque scénario.
- le nombre d’erreurs commises pour chaque scénario.
- le nombre et le type des erreurs répétées.
- le nombre d’actions effectuées par rapport au nombre d’actions minimal requis pour réaliser la tâche.
- le temps moyen mis pour la réalisation de chaque scénario.
- le contenu des verbalisations des utilisateurs.
- le contenu des entretiens au cours du débriefing.
- les scores aux questionnaires d’utilisabilité ou d’UX, si vous en avez fait passer.
Catégoriser le qualitatif
La catégorisation permet de transformer des retours qualitatifs en enseignements clairs et exploitables pour améliorer l’expérience utilisateur, en 4 étapes :
-
Lire et s’imprégner : Comprendre le contexte, repérer les émotions et les thèmes récurrents.
-
Créer des catégories (codage) : Attribuer à chaque retour un ou plusieurs thèmes — ex. Navigation, Compréhension, etc.
-
Regrouper et hiérarchiser : Fusionner les thèmes similaires pour dégager des axes majeurs d’analyse (ex. “Lisibilité” + “Visibilité” = “Clarté”).
-
Synthétiser en insights : Pour chaque catégorie, formuler un constat utilisateur et une recommandation design.
Du qualitatif vers le quantitatif
Lors du regroupement en catégorie, garder les verbatims qui est la source de vos données pour en faire une fréquence.
Si sur 5 testeurs, la catégorie a été remonté par 3 utilisateurs vous avez donc : 3 / 5 soit une fréquence de 0,6 ce qui représente donc 60% de vos utilisateurs.
Exemple d'insight avec recommandation :
| Insights | Recommandations |
|---|---|
| 60 % des utilisateurs ne voient pas le bouton d’achat | Augmenter le contraste du CTA |
Exemple d'analyse

Prioriser les problèmes
Les résultats des tests utilisateurs servent à identifier et corriger les problèmes d’utilisabilité du système.
Pour hiérarchiser les actions à mener, il est recommandé d’établir un ordre de priorité entre les problèmes observés, en distinguant ceux qui bloquent la progression des utilisateurs de ceux qui sont mineurs.
L’utilisation d’une matrice de fréquence des problèmes permet de visualiser leur récurrence et de cibler en priorité les plus fréquents, donc les plus critiques à résoudre.
Exemple de priorisation

Restituer les résultats et analyse
Toutes les données recueillies lors des tests utilisateurs sont synthétisées dans un rapport d’évaluation, souvent illustré par des captures d’écran annotées présentant les principales observations, recommandations et le niveau de gravité des problèmes détectés.
Les pistes d’amélioration sont ensuite élaborées par l’équipe de conception. Ces solutions sont ensuite retestées auprès des utilisateurs, dans une démarche itérative visant l’amélioration continue du système.
Exemple de restitution

C'est l'heure de la pratique !
4.4
La startup Collab'

Une nouvelle mission
Fort de son produit novateur et d'une campagne marketing réussie, Collab a décidé de développer de nouvelles formules, d'enrichir les nombres de fonctionnalités et de revoir entièrement certains parcours de l'application. Bien évidemment, ils n'ont pas jugé utile de faire appel à des UX lors de cette phase.
Néanmoins, l'entreprise constate une nette dégradation des KPI notamment d'inscriptions et achats sur leur solution. Changement de comportement constaté lors de leur sortie officielle en 1.0.0.
Vous avez été choisis en tant qu'Agence UX pour analyser, comprendre et proposer vos solutions afin de redresser la situation et d'améliorer les KPIs!
Metrics: KPI actuels de la 1.0.0 contre KPI de la Bêta
-
Taux de conversion de la landing page (renvoi vers la page d'inscription) : 25% (taux inchangé)
-
Taux de conversion de la page d'inscription (en compte créé) : 2.5% contre 7% avant.
-
Taux de passage d'un compte gratuit à un compte payant : 3% contre 12% avant.
-
Taux de d'upgrade de formule : 7% contre 27% avant.
-
Taux de churn : 2% contre 3% avant.
Les ressources
Rappel : Collab est un espace de travail virtuel disponible sur navigateur et application mobile.
La startup vous donne accès à plusieurs ressources pour auditer l'UX de sa solution :
Lien vers les product pitchs et personae.
Lien vers le prototype (seulement mobile) :
Exemple de méthodologie
- Choisir le persona cible et préparer l'échantillon de testeurs.
- Préparer le protocole de test et les ressources liées au test.
- Réaliser au minimum 3 tests utilisateurs. (dont un avec moi)
- Bonus - Proposer un questionnaire rapide en fin de parcours pour évaluer l'utilisabilité perçue.
- Rédiger la présentation pour restituer les résultats et proposer vos recommendations.
Présentations à partir de 16h en 15 minutes pour chaque groupe.