


























Content ITV PRO
This is Itvedant Content department
Learning Outcome
5
Implement an Embedding layer using Keras
4
Differentiate between Random and Pre-trained embeddings
3
Describe how embedding lookup works
2
Explain why embeddings are preferred over one-hot encoding
1
Understand what an Embedding Layer is in NLP
Before this topic, we already learned:
After tokenization, how does a model understand meaning?
Imagine two ways to describe a person:
One-hot = Only their name in attendance register
Embedding = Full biography (interests, profession, behavior)
Just knowing a word’s position in vocabulary is not enough.
We want its story and relationships
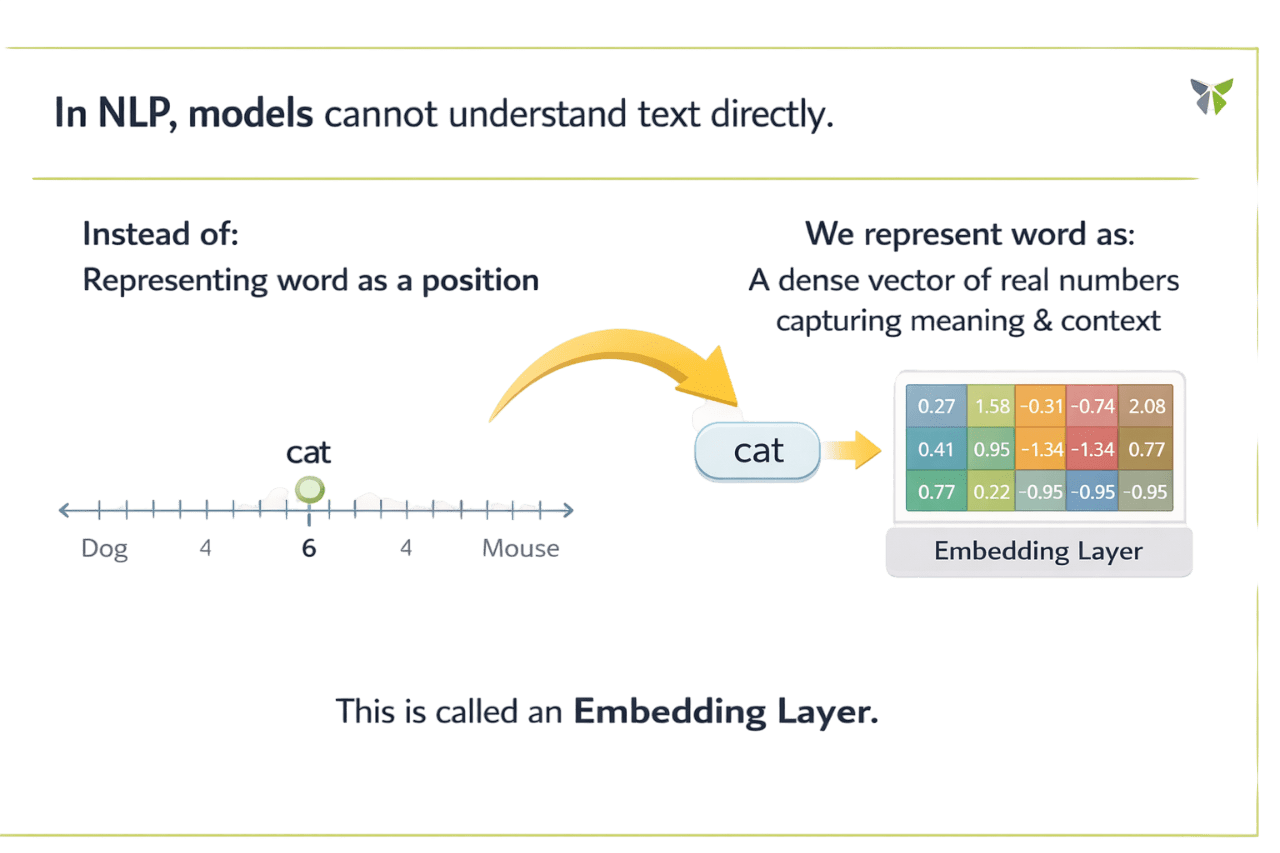
In NLP, models cannot understand text directly...
This is called an Embedding Layer
Let's understand it in detail....
Instead:
Representing word as a position
We represent word as:
A dense vector of real numbers capturing meaning & context
What is an Embedding Layer?
Example:
Input token: 3
Output vector: [0.2, -0.1, 0.9, 0.7]
Converts words into dense vectors
Captures semantic meaning
Learns contextual relationships
Is trainable
Why is Embedding Layer Important?
Meaningful representations
Reduces dimensionality
Better Generation
Memory efficient
Captures semantic relationships between words
Compact vector representations instead of sparse one-hot
Dense vectors save storage space significantly
Helps deep learning models perform better
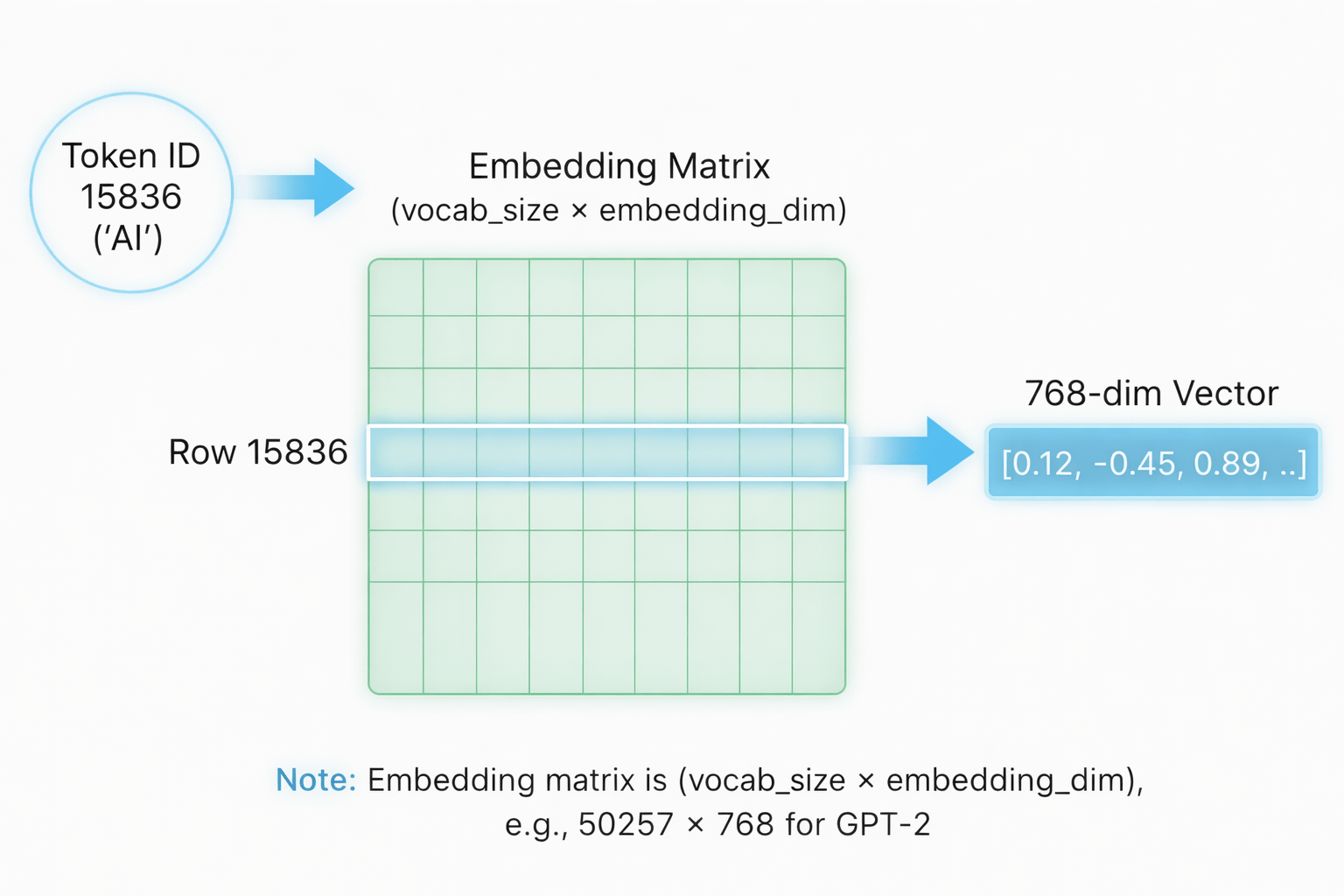
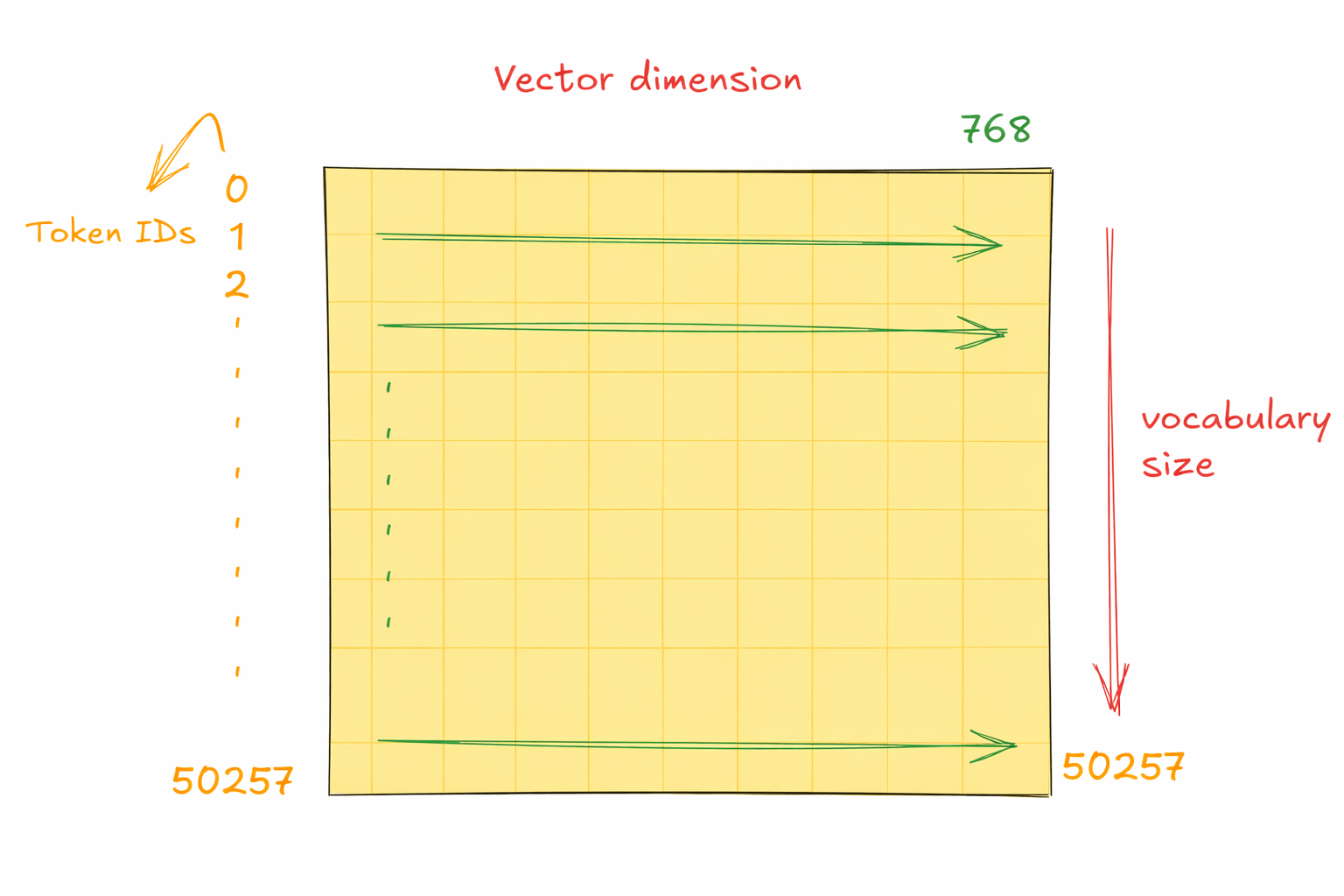
How It Works ?
TOKENIZE
Convert words into integers
LOOKUP
Integer maps to vector via embedding table
TRAIN
Vectors updated during backpropagation
Example:
Input tokens:[3, 7, 4]
Each maps to:4-dimensional vector
Types of Embeddings
RANDOM (TRAINABLE)
Created from scratch
Updated during training
Task-specific learning
PRE-TRAINED
Already trained on large corpora:
Word2Vec
GloVe
fastText
Can be: Static or Fine-tuned
Embeddings One-Hot Encoding
| Feature | One-Hot | Embedding |
|---|---|---|
| Vector Length | Vocabulary size | Fixed |
| Semantic Meaning | ❌ | ✅ |
| Memory Efficient | ❌ | ✅ |
| Learns Context | ❌ | ✅ |
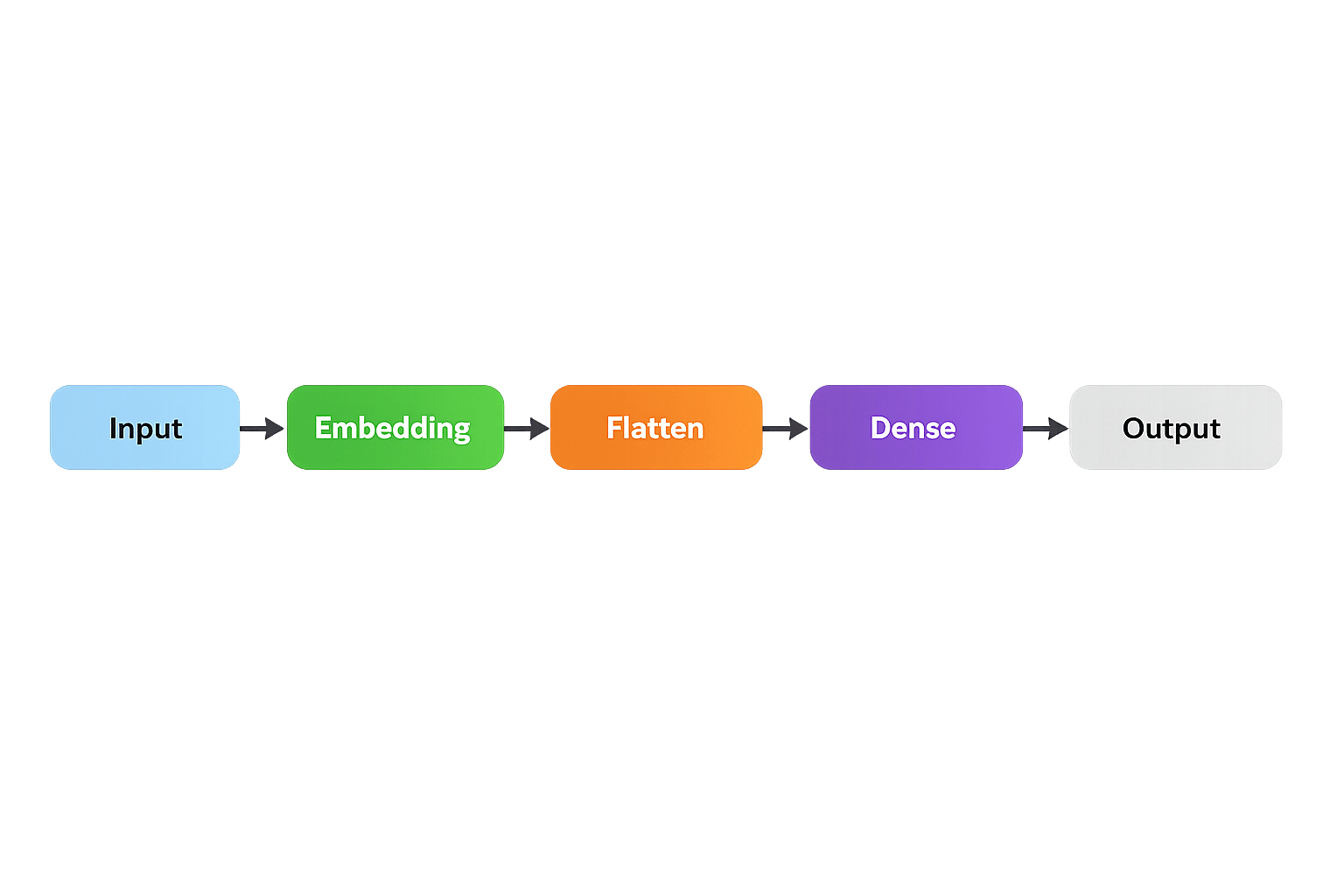
Embedding Layer in Keras
Architecture:
input_dim
Vocabulary size
output_dim
Embedding vector dimension
input_length
Maximum sequence length
model = Sequential([
Embedding(
input_dim=vocab_size,
output_dim=embed_dim,
input_length=max_len
),
Flatten(),
Dense(units)
])Daily Life Applications
Summary
5
Widely used in NLP models
4
Can be random or pre-trained
3
More efficient than one-hot encoding
2
Captures semantic meaning & relationships
1
Embedding Layer converts words into dense vectors
Quiz
Which statement best explains why embeddings are preferred over one-hot encoding?
A) They increase vocabulary size
B) They create sparse vectors
C) They capture semantic meaning in dense vectors
D) They remove need for tokenization
Quiz-Answer
Which statement best explains why embeddings are preferred over one-hot encoding?
A) They increase vocabulary size
B) They create sparse vectors
C) They capture semantic meaning in dense vectors
D) They remove need for tokenization
By Content ITV



