













Content ITV PRO
This is Itvedant Content department
Learning Outcome
5
Apply K-Means++ for better initialization
4
Identify K-Means limitations (outliers & shape bias)
3
Use the Elbow Method to find optimal K
2
Explain centroid assignment and updating in K-Means
1
Understand the shift from supervised to unsupervised learning
Topic Name-Recall(Slide3)
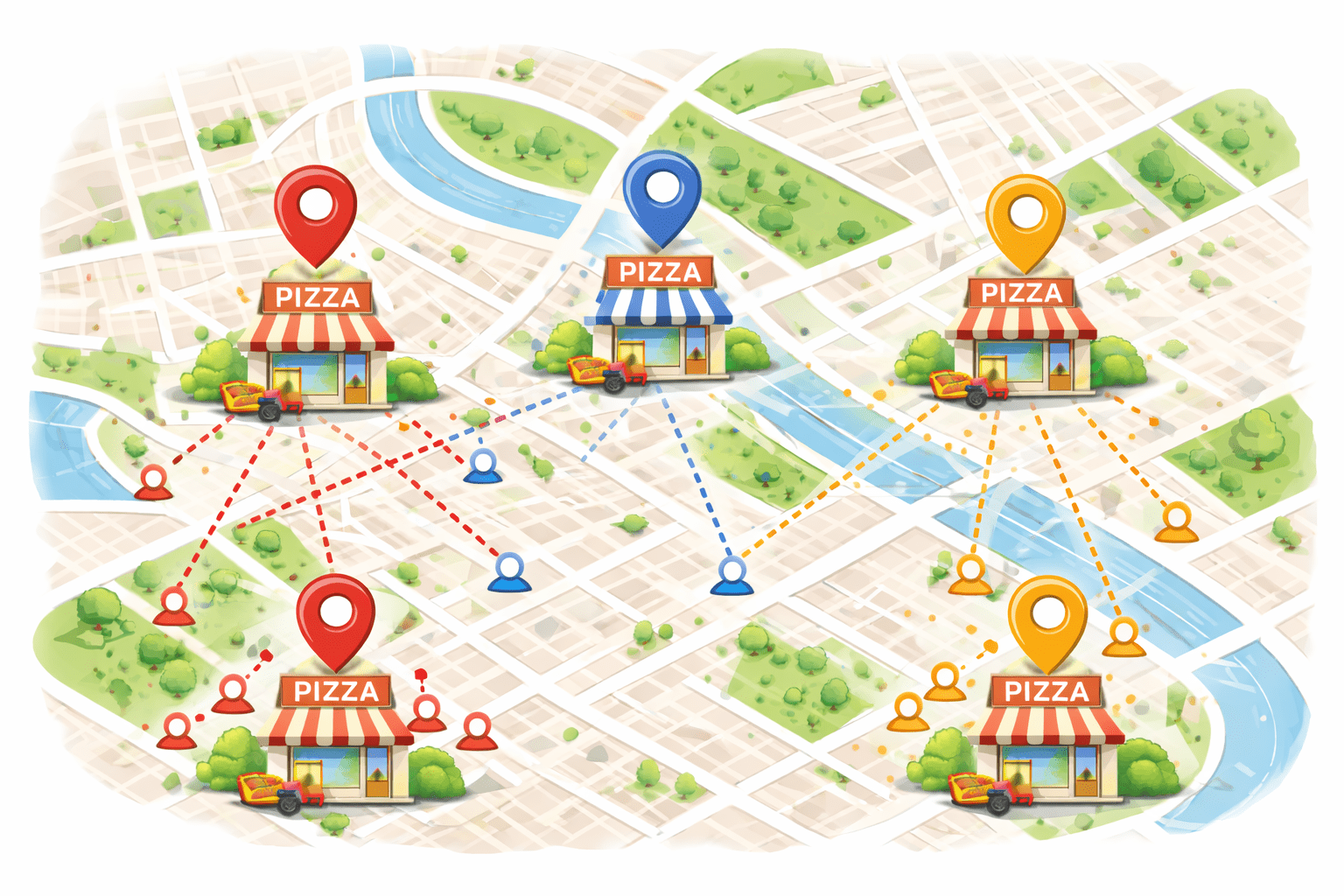
Imagine you are the owner of a big pizza company in a huge city.
You have 10,000 customers living in different areas. Every time they order pizza, delivery takes time depending on how far they are.
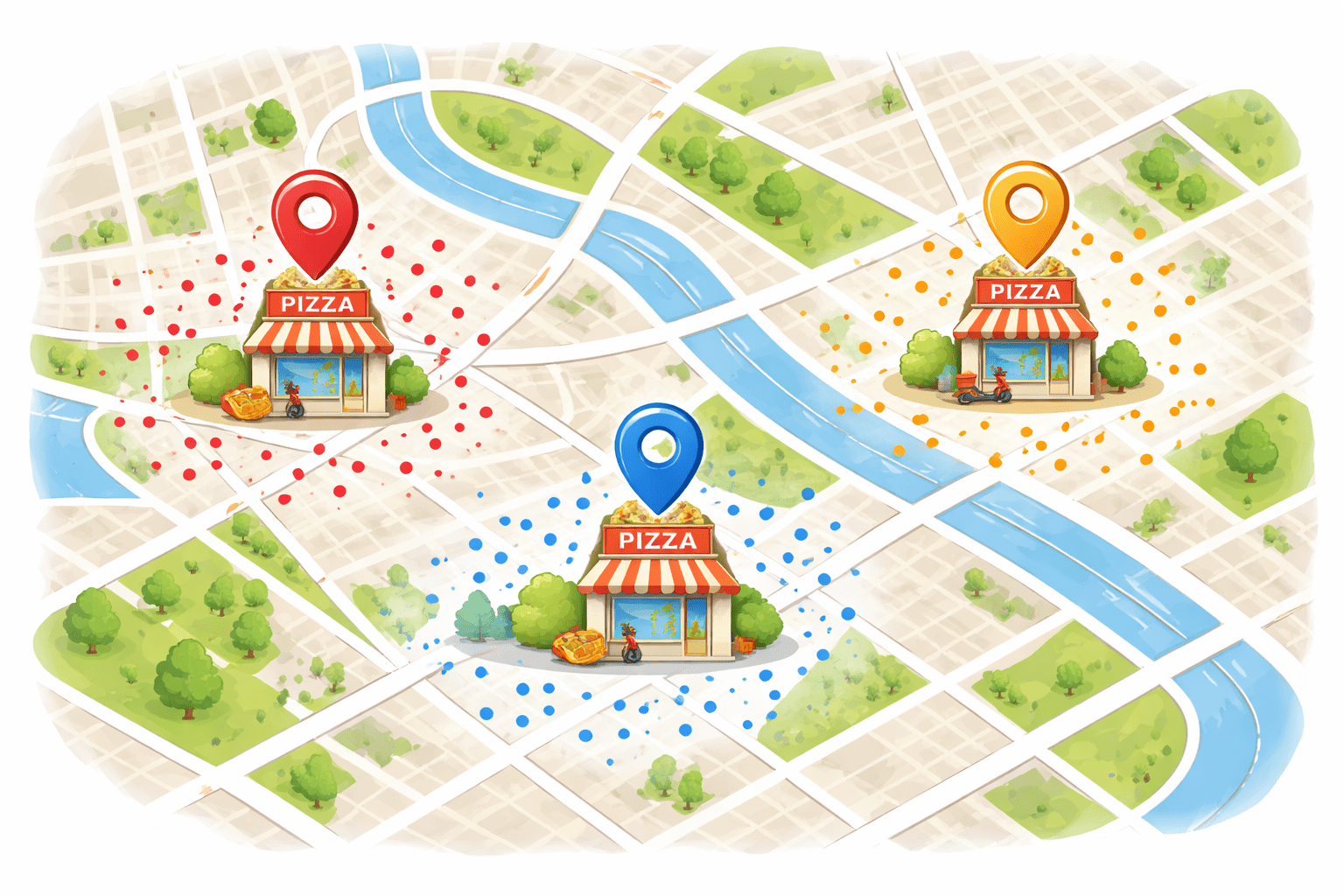
Now you have money to open only 3 new pizza shops.
You start thinking:
“Where should I build these 3 shops so that all customers get pizza as fast as possible?”
If you choose the wrong locations:
Enter K-Means (Smart Assistant)
K-Means helps you find the best central locations based on data
You give all customer locations (GPS points) to a smart algorithm.
The algorithm does this:
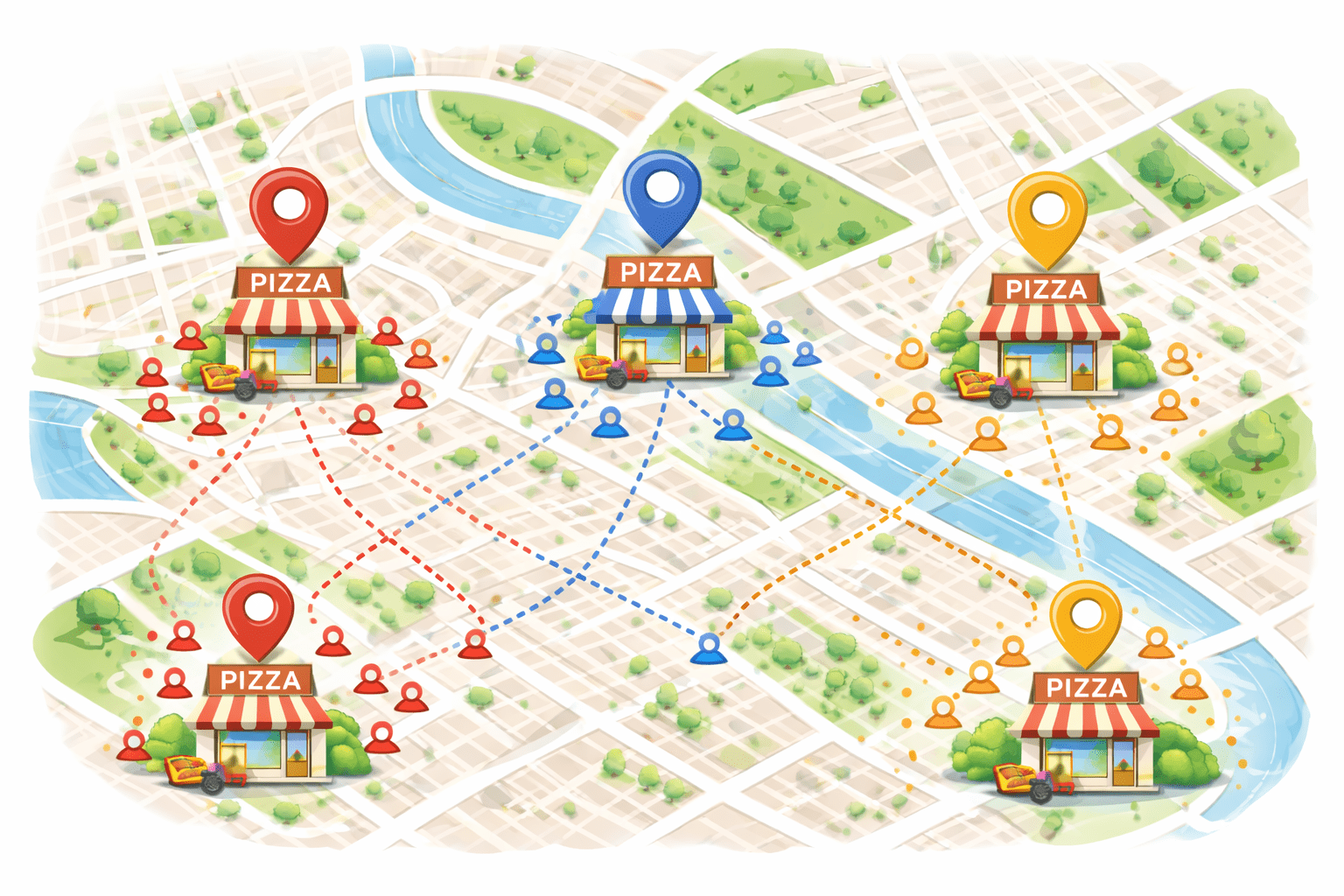
Final Result
So, your 3 pizza shops are placed exactly where they minimize delivery distance
The K-Means Dance
Define the number of clusters
STEP 01
CHOOSE K
STEP 02
DROP CENTROIDS
Place starting points randomly on the map.
STEP 03
ASSIGN POINTS
Each data point joins its nearest centroid
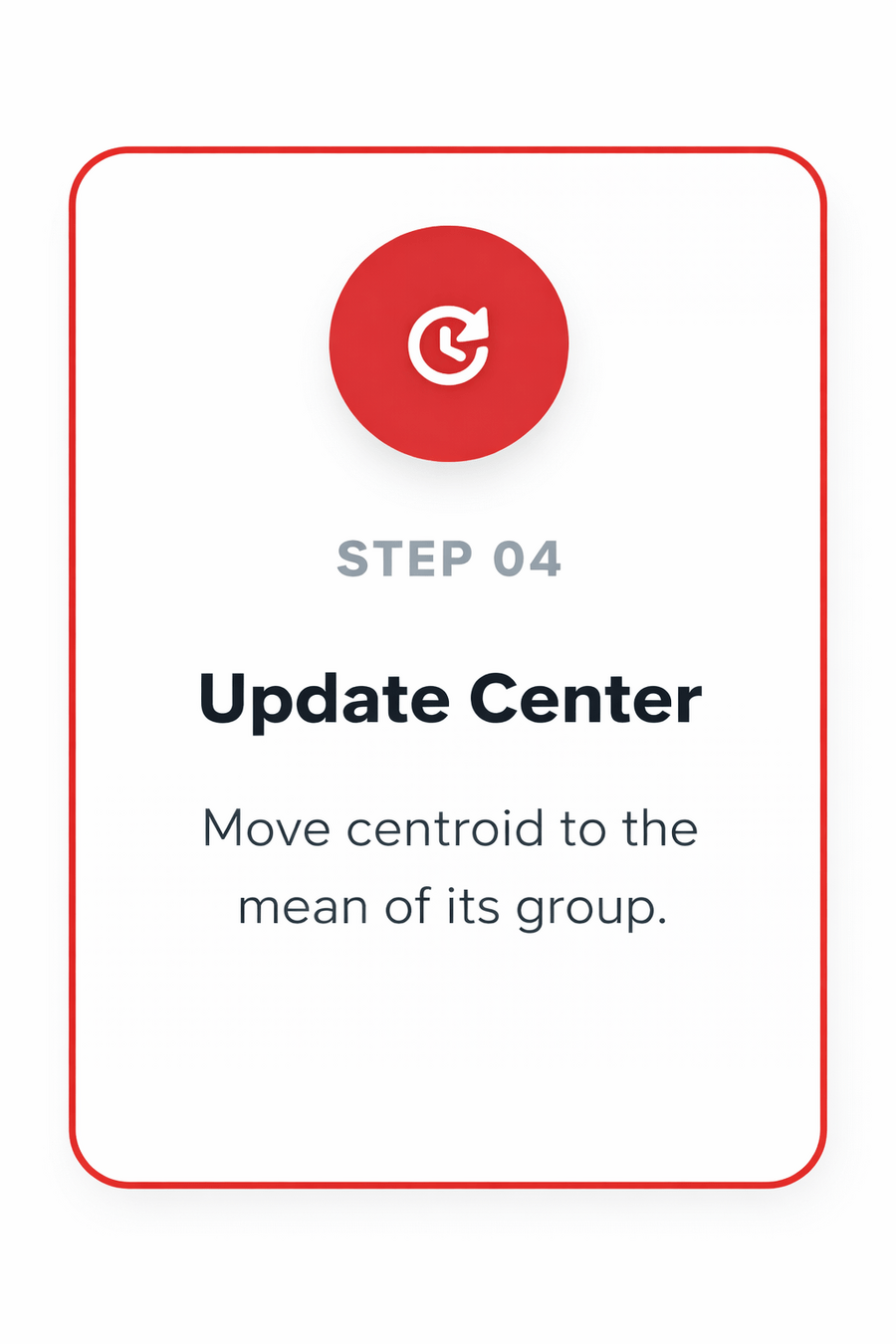
STEP 04
UPDATE CENTER
Move centroid to the mean of its group
STEP 05
REPEAT
Loop until centroids stop moving (Convergence)
The Big Question: How Many Pizza Places?
The Problem : How do we know K = 3 is correct? What if we actually need 5 clusters?
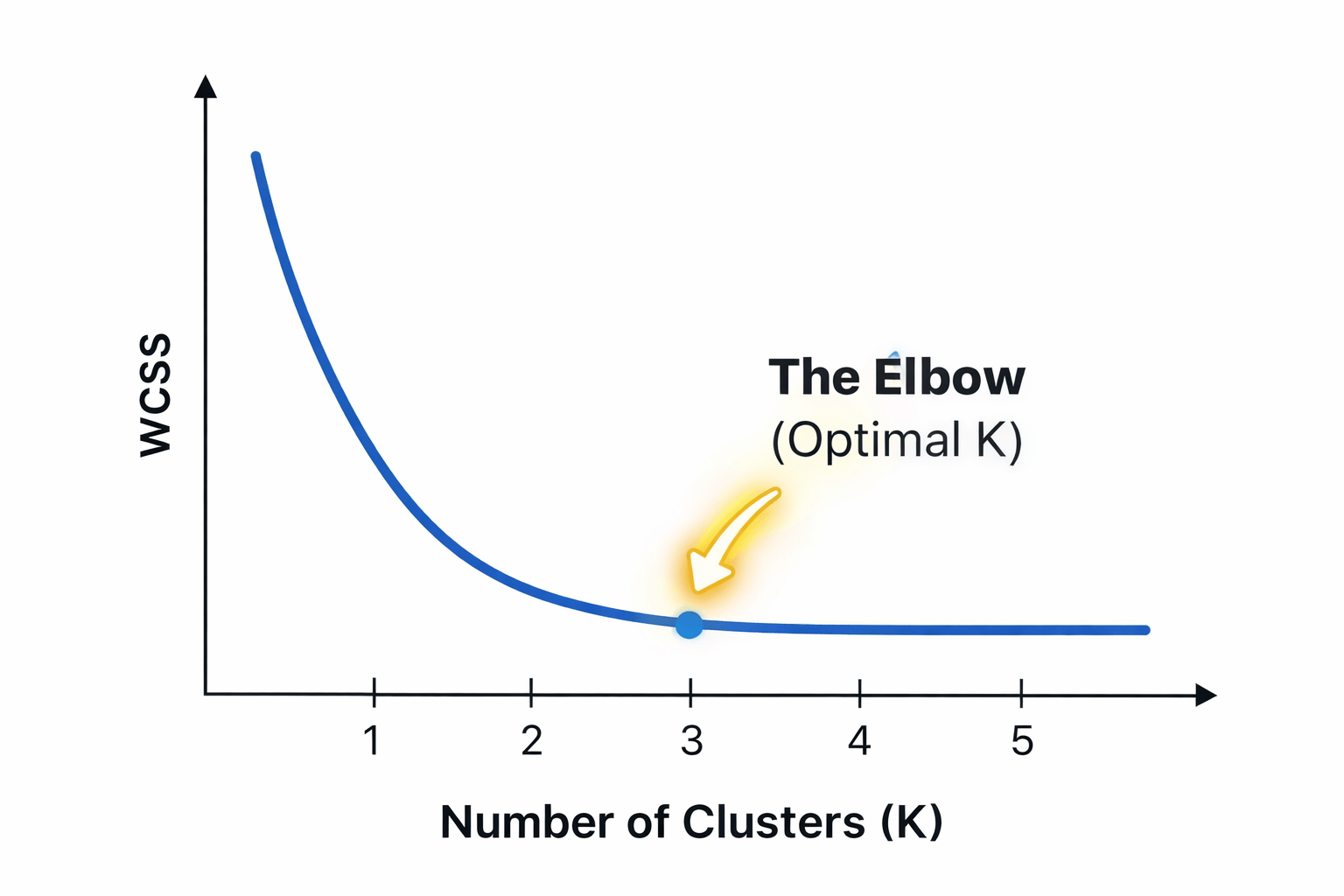
The Metric: WCSS
Measures "Total Delivery Distance". It calculates the sum of squared distances between points and their cluster center.
Within-Cluster Sum of Squares
WCSS = Σ Distance(Centroid)²
Within-Cluster Sum of Squares
WCSS = Σ Distance(Centroid)²
The Insight: "The Elbow"
The line drops rapidly, then bends and flattens. The bend point is where adding more clusters stops being valuable.
The Random Initialization Flaw
In Step 2, K-Means drops the starting centroids completely at random.
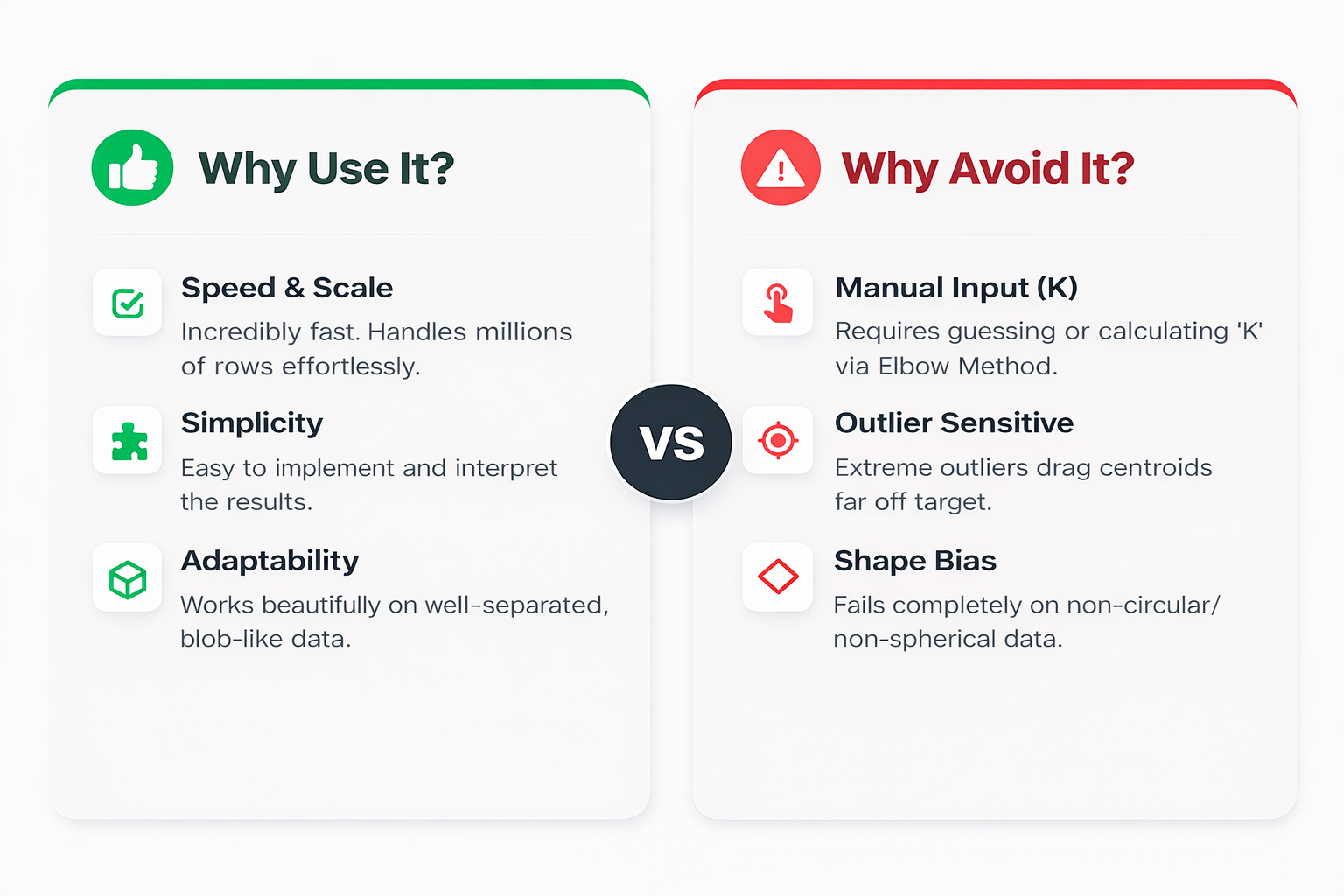
Pros & Cons Cheat Sheet
Summary
5
Sensitive to outliers & works best for spherical data
4
K-Means++ improves initialization
3
Elbow Method finds optimal K
2
Moves centroids to cluster centers
1
K-Means finds groups in unlabeled data
Quiz
Why do K-Means results change every run?
A. Too many dimensions
B. Random initialization issue (use K-Means++)
C. Missing R-squared
D. Clusters too circular
Quiz-Answer
A. Too many dimensions
B. Random initialization issue (use K-Means++)
C. Missing R-squared
D. Clusters too circular
Why do K-Means results change every run?
By Content ITV



